是否曾想过Python怎样在幕后管理数据?变量是怎样存储在内存中的?什么时候会被删除?
在这篇文章中,我们将深入python内部来探究内存管理。
读完这篇文章,你将:
- 了解更多关于底层计算逻辑,尤其是内存相关方面
- 理解Python怎样对底层操作进行抽象
- 明白Python内存管理的的算法
探究Python内部原理能让你有个更好的视角观察Python。希望你对Python有个新的认识。在你的程序正常运行的背后有大量Python的功劳。
内存是一本空白的书
首先,你可以把计算机的内存想象成一本写短篇故事的空白书。当前的每一页都是空的。不同的作者会参与进来。每个作者都会得到一些页面来写入他们的故事。
他们得写的很小心因为不能把东西写到其他人的页面上,在他们写之前,他们会和经理商量一下。经理来决定他们允许写到哪些页上。
因为这书写了很久了,很多故事已经没什么意义了。当一个故事没人看或没人提及时,就会被删掉,留下页面给新的故事。
本质上,计算机内存就像那本空白的书。实际上,通常将固定长度的连续内存称为内存页,因此这个比喻很相似。
书的作者就像需要存数据到内存的应用或进程。经理决定作者可以在书中何处写入内容,他扮演着类似内存管理器的角色。删掉旧的故事给新故事腾出空白页的人就是垃圾回收器。
内存管理:从硬件到软件
内存管理是指应用程序读写数据的过程。内存管理器决定把应用数据放在哪。因为内存是有限的,就跟前面书的比喻一样,内存管理器得找一些空位给程序。提供内存空间的过程通常叫内存分配。
另一方面,当数据不再需要时,可以被删除或释放。但释放到哪里呢?这些内存又是从哪里来的?
在计算机内部,有个物理设备存储着正在运行的Python程序数据。在Python代码和硬件之间隔着很多抽象层。
其中在硬件(比如内存,硬盘)上面的最主要一层是操作系统。
操作系统之上就是程序了,其中就有Python的默认实现版(内置在操作系统或从python.org下载的)。Python代码的内存管理由Python程序负责的。Python程序用于内存管理的算法和数据结构就是本文的主旨。
Python的默认实现版
Python的默认实现版叫CPython,是C语言写的。
***次知道的时候让我很惊讶。一门语言由另一门语言编写?!好吧,并不全是,但也差不多。
Python这门语言的定义是由英语写在参考手册上的。(https://docs.python.org/3/reference/index.html)
然而手册本身并没有什么很大作用。你仍需要按参考手册中的规则写出一些解析代码。
注意:虚拟机就像硬件机,但是由软件实现的。
典型的基于指令的处理过程和汇编指令很相似。
Python是解释执行的语言。你的Python代码实际上会被编译成计算机更能识别的叫字节码的指令。当你运行代码的时候这些指令由虚拟机解析出来。
记得你见到的.pyc文件或__pycache__文件夹吗?就是那些字节码来被虚拟机解析。
同时你也需要能在计算机中实际执行这些字节码的东西。默认的Python实现包含了这以上两样。需要了解的是除了CPython外还有很多其他实现。IronPython被编译成在微软的公共语言运行时上运行。Jython将编译为Java字节码在Java虚拟机上运行。还有PyPy,关于它还得另起一篇文章,还是一笔带过先。
这篇文章主要集中在Python默认实现CPython是如何管理内存上。
声明:Python每个版本的发布都会有很多改变。
当前篇幅主要讨论的是Python3.7版。
说回来,CPython是用C写的并可以解析Python字节码。这些和内存管理又有什么关联呢?因为内存管理的算法和数据结构就在C写的CPython代码里。要理解Python的内存管理机制,就得对CPython本身有个基本的了解。
也许你听说过在Python里面一切皆对象,包括像int或str这样的类型本身。
注意:在C语言里面一个struct就是一组不同类型数据的集合。
可以类比为面向对象语言里面一个只有属性没有方法的类。
CPython是用没有原生面向对象支持的C语言写的。所以,在CPython的代码里面有很多有趣的设计。
PyObject在Python里面是所有对象的鼻祖,它只包含两样东西:
- ob_refcnt: 引用计数
- ob_type: 类型指针
引用计数是用于垃圾回收的。类型指针则是指向另一实体类型的指针。那个类型的指针只是另一个描述Python实体的struct(比如dict或int)。
每个实体包含特定的内存分配器,用于申请内存和存储自身。每个实体也有特定的内存释放器用于当自身不被引用时的内存释放。
与此同时,在申请和释放内存时还有个很重要的因素。内存在计算机内是共享资源,如果两个不同的进程同时使用一块相同的内存则会出错。
全局解释器锁(GIL)
GIL是解决计算机中如内存之类的共享资源的通用解决方案。当两个线程试图同时修改相同的资源时,它们可能会影响到对方。最终结果可能是都得不到自己想要的结果。
再拿书本来打个比方。想象一下两个固执的作者坚持本次该轮到自己来书写。而且,他们写的还是同一页纸。
他们都忽略对方然后各自在这一页上写故事。
结果是两个故事互相交织在一起,整页都没人看得懂。
有个解决方案是当线程影响到共享资源(书本中的空白页)的时候有唯一一个全局的的锁来锁住解释器。换句话说,同时只有一个作者可写。
Python的GIL通过加锁整个解释器来获得资格,就是说另一个线程不会影响到当前这个。当CPython对内存进行处理的时候,使用GIL来确保这些操作是安全的。
这种方式有它的优点和缺点,Python社区对GIL的争论很激烈。想要了解更多GIL的知识,我建议你们可以看看《什么是全局解释器锁》(https://realpython.com/python-gil/?from=ethan)这篇文章。
垃圾回收
我们再看一下书的类比,假设其中一些故事已经过时了。没人看也没人引用这些故事。这种情况下就该处理掉这些故事以便腾出新的页面。
这些没人看和引用的故事就像Python里面引用计数为0的对象。提醒一下每个实体对象在Python中都有一个引用计数和类型指针。
有几个不同的因素可让引用计数增长。比如,当前对象被赋予其它变量时引用计数会增长。
- numbers = [1, 2, 3]
- # 引用计数 = 1
- more_numbers = numbers
- # 引用计数 = 2
当把对象传参使用的时候也会增加引用计数:
- total = sum(numbers)
***举个例子,当一个list包含此对象的时候也会增加引用计数:
- matrix = [numbers, numbers, numbers]
你可以通过sys模块来检查Python对象的引用计数。你可以这样用sys.getrefcount(numbers), 但要记得当你用getrefcount()的时候numbers的引用计数也会加1。
任何情况下,如果一个对象仍在你代码某处被使用,那它的引用计数就会大于0.一旦降为0的时候,这个对象特定的释放函数就会被调用来释放内存给其他对象复用。
所谓的“释放”到底是什么意思呢?其他对象又是如何复用这块内存的?让我们深入CPython的内存管理机制。
CPython的内存管理机制
准备好,我们即将深入研究CPython的内存结构和算法。
如上所述,在硬件和CPython之间还有很多抽象层。操作系统对实体内存做了抽象并建立了一个虚拟内存层给程序(包括Python)来访问。
Python留了一块内存来给对象之外的内部使用。其他部分取决于对象如何存储(int,dict等等)如果你想要个全面的了解,可以看下CPython的源码,所有内存管理相关的都在里面。
CPython有一个内存分配器来负责在对象内存区分配内存。这个对象分配器就是所有魔法发生的源头。每当一个新的对象需要分配或释放时都会被调用。
像典型的int或list等Python对象在每次分配和释放时不会包含太多的数据。所以分配器被设计成在分配少批量数据时如何更好的工作。同时也要避免不要当真的需要内存的时候才去申请物理内存。
源码里面关于分配器的描述是:一种快速且为小块内存专用的分配器,用于通用malloc之上。此处讲的malloc是C里面用于分配内存的库函数。
现在我们来看看CPython的内存分配策略。首先,我们先讲一下3个互相影响的区。
arenas区是内存中***的区,在内存中是按页对齐的。页是指被操作系统使用的一小块连续且固定大小的内存块。Python假设操作系统使用的页大小是256K。
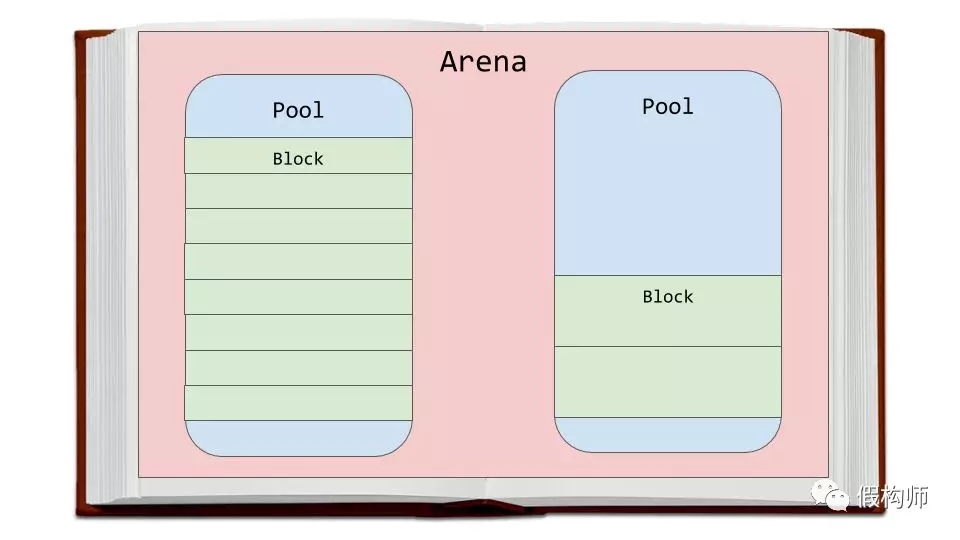
arenas区内部是内存池,每个内存池是个虚拟内存页(4K)。就像我们类比书里面的空白页面。这些内存池被切分成更小的内存块。
同个内存池内的所有块大小均相同。给定一组请求数据,规格类定义了指定块大小。以下图表是从源码注释转换而来:
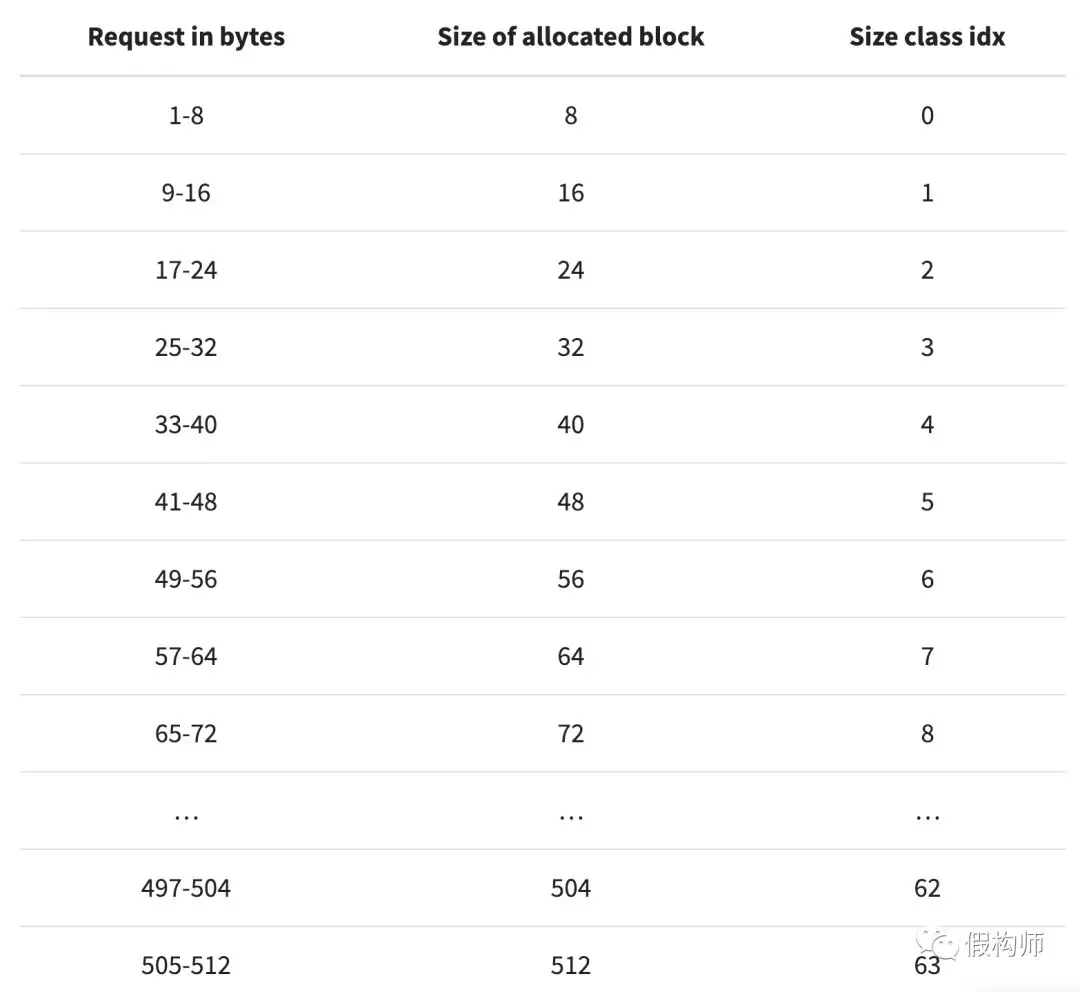
例如,如果需要42个字节,那么数据会存放在一个48字节的块中。
内存池
内存池是由相同规格类定义的块组成。每个内存池都管理着一个双向链表,链接着其他相同规格的内存池。由此算法可以很容易的通过给定的块大小找到可用空间,甚至是在不同内存池之间也行。
可通过已使用的内存池列表追踪所有相同规格类的可用空间。给定一个块大小,算法可以从已使用内存池列表中检测出来。
内存池必须是以下3种状态之一:使用中,满,空。使用中的内存池有特定大小块可供数据存储。满的内存池内被已分配的数据占满。空内存池没有数据,当需要的时候可以被初始化为任意大小规格的内存池。
空内存池列表记录着所有空状态的内存池。那空内存池什么时候会被用到呢?
假设你的代码需要8个字节的内存池块。如果在已使用的内存池列表中没有关于8个字节规格的,那么一个空的内存池会被初始化为专门存储8个字节。同时这个新的内存池会被添加到已使用内存池中供接下来的请求使用。
当满的内存池当中有些块被回收了,那么这个内存池又会被添加到当前大小的使用中内存池列表中。
现在你知道这些内存池是怎样从不同状态之间自由切换的算法了。
内存块
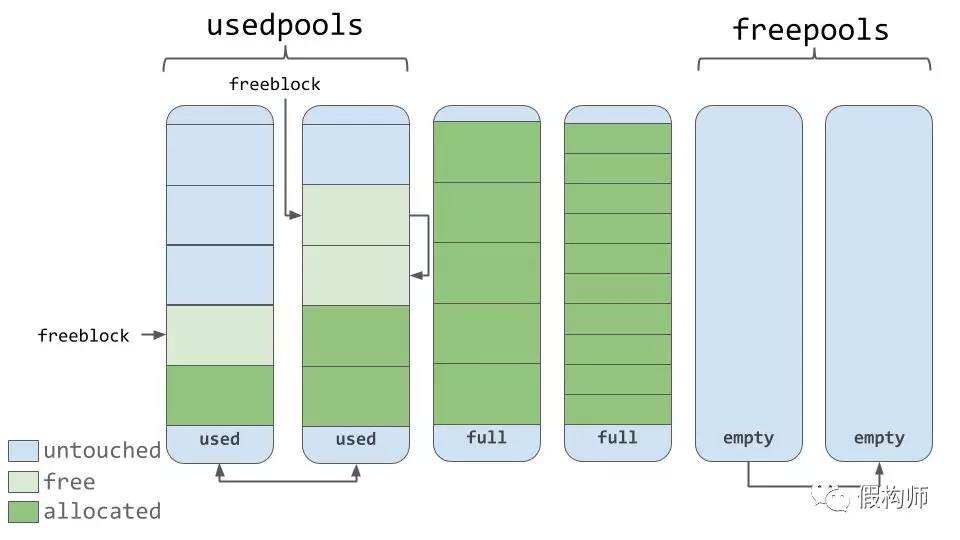
由上图可知,内存池包含一个指向空内存块的指针。这里有一点细微的差别。源代码的注释指出,分配器力求在各级别(arena, pool, block)内存真正被需要的时候才去使用它。
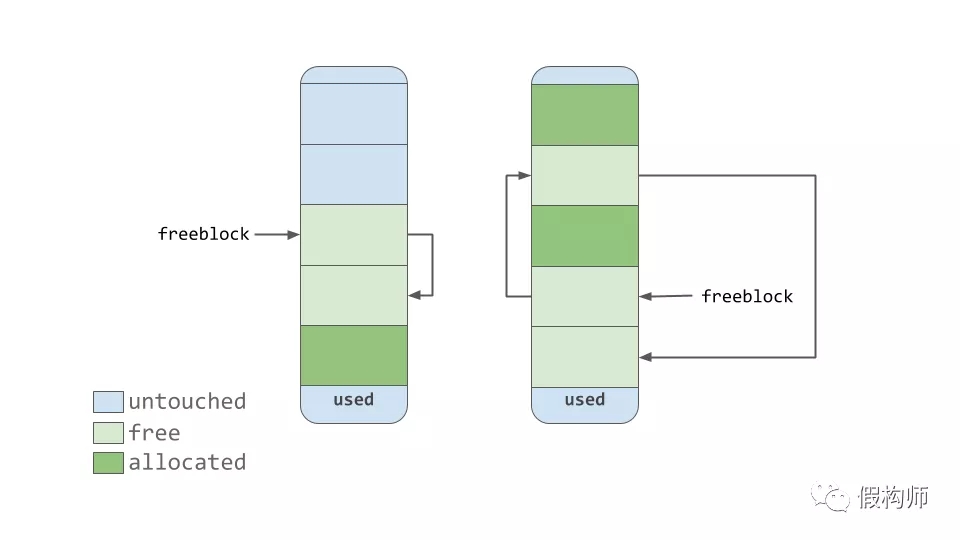
内存池中的块有3种状态。这些状态的定义如下:
- untouched: 还未被分配使用的内存块
- free: 被分配然后又被"释放"的内存块且里面没有保存相关数据了
- allocated: 已分配且含有数据的内存块
free状态的块指针列表保存着一系列的free态内存。换句话说,一个可用来放数据的列表。如果需要比可用的所有free态内存还要多,那么分配器会去使用那些untouched态的块。
当内存管理器把内存块状态置为"释放"时会把它添加到free态链表的头部。这个链表可能不像上面那图一样为连续的内存块。它可能是如下图那样:
Arenas区
arenas区包含着内存池。这些内存池可以是使用中,满,或空的。arenas区不像内存池那样有明显的状态区分。
arenas区由称为usable_arenas的双向链表组织而成。此链表按可用内存池的数量排序。越少可用内存池的排在越前面。
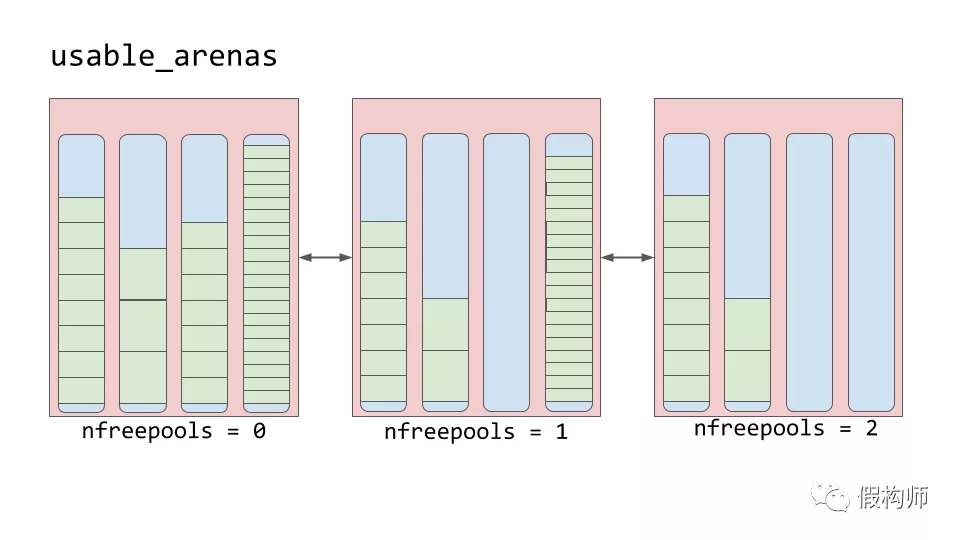
这意味着arena区会选择更接近用满的地方来存放数据。为什么不反过来做呢?为什么数据不放到最空的地方去?
这就要说到真正的内存释放。你也许注意到我给释放加了引号, 它并不是真正的释放到操作系统。Python继续保留着以供新的数据使用。真正的内存释放是返回给操作系统使用。
arenas区是唯一可以真正被释放的地方。所以那些接近为空的区域也理所当然应当为空。通过这种方式,可以真正释放内存,减少Python程序的总体内存占用。
总结
内存管理是计算机工作中不可或缺的一部分。不管好坏,Python几乎在幕后处理所有这些问题。
在本篇中,你学到了:
- 什么是内存管理和为什么它很重要
- 默认的Python实现CPython是用C写的
- CPython的内存管理是怎样通过数据结构和算法来管理你的数据的
Python抽象了很多繁杂的细节来与计算机打交道,让你有能力从更高的层次来开发代码而不用为字节存放到哪而头疼。