【51CTO.com快译】我们在本教程中将构建和部署一个机器模型,以便利用Stackoverflow数据集预测工资。 看完本文后,你能够调用充分利用REST的Web服务来获得预测结果。
由于目的是演示工作流程,我们将使用一个简单的双列数据集进行试验,该数据集包含多年的工作经验和薪水。想了解数据集的详细信息,参阅我之前介绍线性回归的那篇文章。
先决条件
1.Python和Scikit-learn方面的基础知识
2.有效的微软Azure订阅
3.Anaconda或Miniconda
配置开发环境
使用Azure ML SDK配置一个虚拟环境。 运行以下命令以安装Python SDK,并启动Jupyter Notebook。从Jupyter启动一个新的Python 3内核。
- $ conda create -n aml -y Python=3.6
- $ conda activate aml
- $ conda install nb_conda
- $ pip install azureml-sdk[notebooks]
- $ jupyter notebook
初始化Azure ML环境
先导入所有必要的Python模块,包括标准的Scikit-learn模块和Azure ML模块。
- import datetime
- import numpy as np
- import pandas as pd
- from sklearn.model_selection import train_test_split
- from sklearn.linear_model import LinearRegression
- from sklearn.externals import joblib
- import azureml.core
- from azureml.core import Workspace
- from azureml.core.model import Model
- from azureml.core import Experiment
- from azureml.core.webservice import Webservice
- from azureml.core.image import ContainerImage
- from azureml.core.webservice import AciWebservice
- from azureml.core.conda_dependencies import CondaDependencies
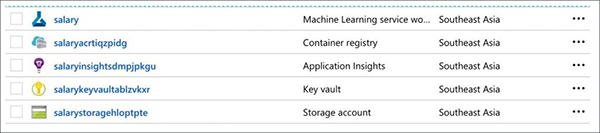
我们需要创建一个Azure ML Workspace,该工作区充当我们这次试验的逻辑边界。Workspace创建用于存储数据集的Storage Account、存储秘密信息的Key Vault、维护映像中心的Container Registry以及记录度量指标的Application Insights。
别忘了把占位符换成你的订阅ID。
- ws = Workspace.create(name='salary',
- subscription_id='',
- resource_group='mi2',
- create_resource_group=True,
- location='southeastasia'
- )
几分钟后,我们会看到Workspace里面创建的资源。
现在我们可以创建一个Experiment开始记录度量指标。由于我们没有许多参数要记录,于是获取训练过程的启始时间。
- exp = Experiment(workspace=ws, name='salexp')
- run = exp.start_logging()
- run.log("Experiment start time", str(datetime.datetime.now()))
训练和测试Scikit-learn ML模块
现在我们将进而借助Scikit-learn训练和测试模型。
- sal = pd.read_csv('data/sal.csv',header=0, index_col=None)
- X = sal[['x']]
- y = sal['y']
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=10)
- lm = LinearRegression()
- lm.fit(X_train,y_train)
经过训练的模型将被序列化成输出目录中的pickle文件。Azure ML将输出目录的内容自动拷贝到云端。
- filename = 'outputs/sal_model.pkl'
- joblib.dump(lm, filename)
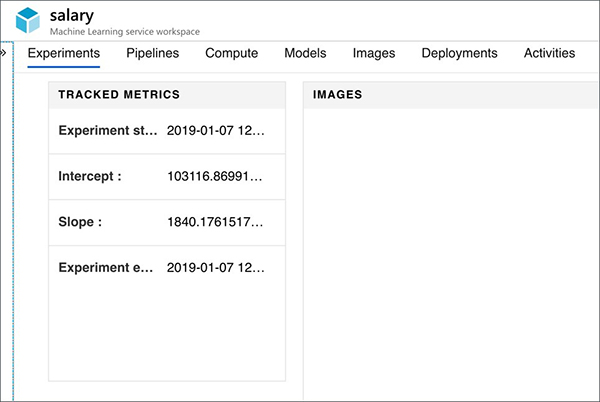
不妨记录训练作业的斜率、截距和结束时间,从而完成试验。
- run.log('Intercept :', lm.intercept_)
- run.log('Slope :', lm.coef_[0])
- run.log("Experiment end time", str(datetime.datetime.now()))
- run.complete()
我们可以通过Azure Dashboard来跟踪度量指标和执行时间。
注册和加载经过训练的模型
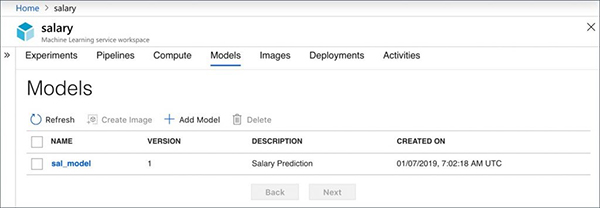
每当我们冻结模型,它可以用独特的版本向Azure ML注册。这让我们能够在加载时在不同的模型之间轻松切换。
不妨将SDK指向PKL文件的位置,注册来自上述训练作业的工资模型。我们还将一些额外的元数据以标签这种形式添加到模型中。
- model = Model.register(model_path = "outputs/sal_model.pkl",
- model_name = "sal_model",
- tags = {"key": "1"},
- description = "Salary Prediction",
- workspace = ws)
检查Workspace的Models部分,确保我们的模型已注册。
是时候将模型打包成容器映像(到时作为Web服务来公开)并部署的时候了。
为了创建容器映像,我们需要将模型所需的环境告诉Azure ML。然而,我们传递一段Python脚本,该脚本含有基于入站数据点来预测数值的代码。
Azure ML API为两者提供了便利的方法。不妨先创建环境文件salenv.yaml,该文件告诉运行时环境在容器映像中添加Scikit-learn。
- salenv = CondaDependencies()
- salenv.add_conda_package("scikit-learn")
- with open("salenv.yml","w") as f:
- f.write(salenv.serialize_to_string())
- with open("salenv.yml","r") as f:
- print(f.read())
下列代码片段从Jupyter Notebook来执行时,创建一个名为score.py的文件,该文件含有模型的推理逻辑。
- %%writefile score.py
- import json
- import numpy as np
- import os
- import pickle
- from sklearn.externals import joblib
- from sklearn.linear_model import LogisticRegression
- from azureml.core.model import Model
- def init():
- global model
- # retrieve the path to the model file using the model name
- model_path = Model.get_model_path('sal_model')
- model = joblib.load(model_path)
- def run(raw_data):
- data = np.array(json.loads(raw_data)['data'])
- # make prediction
- y_hat = model.predict(data)
- return json.dumps(y_hat.tolist())
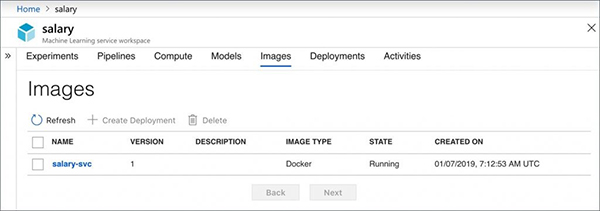
现在将推理文件和环境配置传递给映像,从而将各点连起来。
- %%time
- image_config = ContainerImage.image_configuration(execution_script="score.py",
- runtime="python",
- conda_file="salenv.yml")
这最终会创建将出现在Workspace的Images部分中的容器映像。
我们都已准备创建定义目标环境的部署配置,并将它作为托管在Azure Container Instance的Web服务来运行。我们还决定选择AKS或物联网边缘环境作为部署目标。
- aciconfig = AciWebservice.deploy_configuration(cpu_cores=1,
- memory_gb=1,
- tags={"data": "Salary", "method" : "sklearn"},
- description='Predict Stackoverflow Salary')
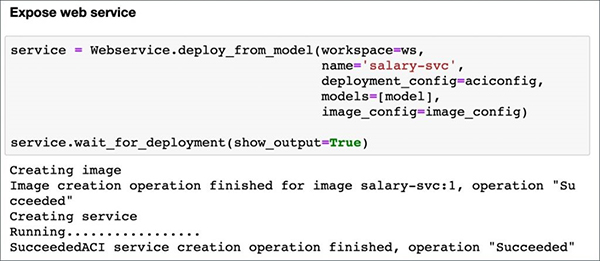
- service = Webservice.deploy_from_model(workspace=ws,
- name='salary-svc',
- deployment_config=aciconfig,
- models=[model],
- image_config=image_config)
- service.wait_for_deployment(show_output=True)
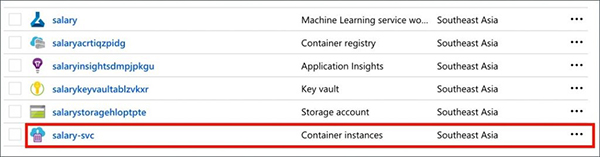
Azure Resource Group现在有一个为模型运行推理的Azure Container Instance。
我们可以从下面这个方法获得推理服务的URL:
- print(service.scoring_uri)

现在通过cURL来调用Web服务。我们可以从同一个Jupyter Notebook来做到这一点。

你可以从Github代码库来访问数据集和Jupyter Notebook。
这种方法的独特之处在于,我们可以从在Jupyter Notebook里面运行的Python内核来执行所有任务。开发人员可以利用代码完成训练和部署ML模型所需的各项任务。这正是使用诸如ML Service之类的ML PaaS具有的好处。
原文标题:Build and Deploy a Machine Learning Model with Azure ML Service,作者:Janakiram MSV
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】