













Redis分布式锁进化史
近两年来微服务变得越来越热门,越来越多的应用部署在分布式环境中,在分布式环境中,数据一致性是一直以来需要关注并且去解决的问题,分布式锁也就成为了一种广泛使用的技术,常用的分布式实现方式为Redis,Zookeeper,其中基于Redis的分布式锁的使用更加广泛。
但是在工作和网络上看到过各个版本的Redis分布式锁实现,每种实现都有一些不严谨的地方,甚至有可能是错误的实现,包括在代码中,如果不能正确的使用分布式锁,可能造成严重的生产环境故障,本文主要对目前遇到的各种分布式锁以及其缺陷做了一个整理,并对如何选择合适的Redis分布式锁给出建议。
各个版本的Redis分布式锁
V1.0
- tryLock(){
- SETNX Key 1
- EXPIRE Key Seconds
- }
- release(){
- DELETE Key
- }
这个版本应该是最简单的版本,也是出现频率很高的一个版本,首先给锁加一个过期时间操作是为了避免应用在服务重启或者异常导致锁无法释放后,不会出现锁一直无法被释放的情况。
这个方案的一个问题在于每次提交一个Redis请求,如果执行完***条命令后应用异常或者重启,锁将无法过期,一种改善方案就是使用Lua脚本(包含SETNX和EXPIRE两条命令),但是如果Redis仅执行了一条命令后crash或者发生主从切换,依然会出现锁没有过期时间,最终导致无法释放。
另外一个问题在于,很多同学在释放分布式锁的过程中,无论锁是否获取成功,都在finally中释放锁,这样是一个锁的错误使用,这个问题将在后续的V3.0版本中解决。
针对锁无法释放问题的一个解决方案基于GETSET命令来实现
V1.1 基于GETSET
- tryLock(){
- NewExpireTime=CurrentTimestamp+ExpireSeconds
- if(SETNX Key NewExpireTime Seconds){
- oldExpireTime = GET(Key)
- if( oldExpireTime < CurrentTimestamp){
- NewExpireTime=CurrentTimestamp+ExpireSeconds
- CurrentExpireTime=GETSET(Key,NewExpireTime)
- if(CurrentExpireTime == oldExpireTime){
- return 1;
- }else{
- return 0;
- }
- }
- }
- }
- release(){
- DELETE key
- }
思路:
- SETNX(Key,ExpireTime)获取锁
- 如果获取锁失败,通过GET(Key)返回的时间戳检查锁是否已经过期
- GETSET(Key,ExpireTime)修改Value为NewExpireTime
- 检查GETSET返回的旧值,如果等于GET返回的值,则认为获取锁成功
注意:这个版本去掉了EXPIRE命令,改为通过Value时间戳值来判断过期
问题:
- 在锁竞争较高的情况下,会出现Value不断被覆盖,但是没有一个Client获取到锁
- 在获取锁的过程中不断的修改原有锁的数据,设想一种场景C1,C2竞争锁,C1获取到了锁,C2锁执行了GETSET操作修改了C1锁的过期时间,如果C1没有正确释放锁,锁的过期时间被延长,其它Client需要等待更久的时间
V2.0 基于SETNX
- tryLock(){
- SETNX Key 1 Seconds
- }
- release(){
- DELETE Key
- }
Redis 2.6.12版本后SETNX增加过期时间参数,这样就解决了两条命令无法保证原子性的问题。但是设想下面一个场景:
- C1成功获取到了锁,之后C1因为GC进入等待或者未知原因导致任务执行过长,***在锁失效前C1没有主动释放锁
- C2在C1的锁超时后获取到锁,并且开始执行,这个时候C1和C2都同时在执行,会因重复执行造成数据不一致等未知情况
- C1如果先执行完毕,则会释放C2的锁,此时可能导致另外一个C3进程获取到了锁
大致的流程图
存在问题:
- 由于C1的停顿导致C1 和C2同都获得了锁并且同时在执行,在业务实现间接要求必须保证幂等性
- C1释放了不属于C1的锁
V3.0
- tryLock(){
- SETNX Key UnixTimestamp Seconds
- }
- release(){
- EVAL(
- //LuaScript
- if redis.call("get",KEYS[1]) == ARGV[1] then
- return redis.call("del",KEYS[1])
- else
- return 0
- end
- )
- }
这个方案通过指定Value为时间戳,并在释放锁的时候检查锁的Value是否为获取锁的Value,避免了V2.0版本中提到的C1释放了C2持有的锁的问题;另外在释放锁的时候因为涉及到多个Redis操作,并且考虑到Check And Set 模型的并发问题,所以使用Lua脚本来避免并发问题。
存在问题:
- 如果在并发极高的场景下,比如抢红包场景,可能存在UnixTimestamp重复问题,另外由于不能保证分布式环境下的物理时钟一致性,也可能存在UnixTimestamp重复问题,只不过极少情况下会遇到。
V3.1
- tryLock(){
- SET Key UniqId Seconds
- }
- release(){
- EVAL(
- //LuaScript
- if redis.call("get",KEYS[1]) == ARGV[1] then
- return redis.call("del",KEYS[1])
- else
- return 0
- end
- )
- }
Redis 2.6.12后SET同样提供了一个NX参数,等同于SETNX命令,官方文档上提醒后面的版本有可能去掉SETNX, SETEX, PSETEX,并用SET命令代替,另外一个优化是使用一个自增的唯一UniqId代替时间戳来规避V3.0提到的时钟问题。
这个方案是目前***的分布式锁方案,但是如果在Redis集群环境下依然存在问题:
由于Redis集群数据同步为异步,假设在Master节点获取到锁后未完成数据同步情况下Master节点crash,此时在新的Master节点依然可以获取锁,所以多个Client同时获取到了锁
分布式Redis锁:Redlock
V3.1的版本仅在单实例的场景下是安全的,针对如何实现分布式Redis的锁,国外的分布式专家有过激烈的讨论, antirez提出了分布式锁算法Redlock,在distlock话题下可以看到对Redlock的详细说明,下面是Redlock算法的一个中文说明(引用)
假设有N个独立的Redis节点
- 获取当前时间(毫秒数)。
- 按顺序依次向N个Redis节点执行获取锁的操作。这个获取操作跟前面基于单Redis节点的获取锁的过程相同,包含随机字符串myrandomvalue,也包含过期时间(比如PX 30000,即锁的有效时间)。为了保证在某个Redis节点不可用的时候算法能够继续运行,这个获取锁的操作还有一个超时时间(time out),它要远小于锁的有效时间(几十毫秒量级)。客户端在向某个Redis节点获取锁失败以后,应该立即尝试下一个Redis节点。这里的失败,应该包含任何类型的失败,比如该Redis节点不可用,或者该Redis节点上的锁已经被其它客户端持有(注:Redlock原文中这里只提到了Redis节点不可用的情况,但也应该包含其它的失败情况)。
- 计算整个获取锁的过程总共消耗了多长时间,计算方法是用当前时间减去第1步记录的时间。如果客户端从大多数Redis节点(>= N/2+1)成功获取到了锁,并且获取锁总共消耗的时间没有超过锁的有效时间(lock validity time),那么这时客户端才认为最终获取锁成功;否则,认为最终获取锁失败。
- 如果最终获取锁成功了,那么这个锁的有效时间应该重新计算,它等于最初的锁的有效时间减去第3步计算出来的获取锁消耗的时间。
- 如果最终获取锁失败了(可能由于获取到锁的Redis节点个数少于N/2+1,或者整个获取锁的过程消耗的时间超过了锁的最初有效时间),那么客户端应该立即向所有Redis节点发起释放锁的操作(即前面介绍的Redis Lua脚本)。
- 释放锁:对所有的Redis节点发起释放锁操作
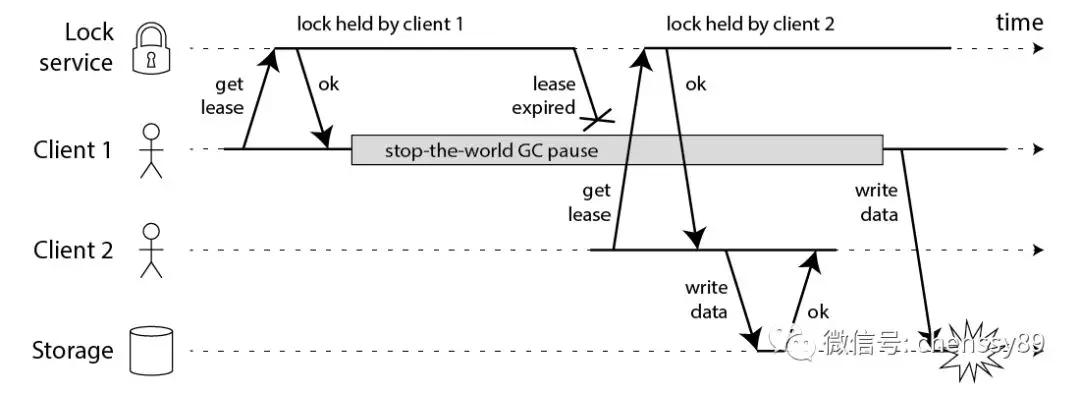
然而Martin Kleppmann针对这个算法提出了质疑,提出应该基于fencing token机制(每次对资源进行操作都需要进行token验证)
- Redlock在系统模型上尤其是在分布式时钟一致性问题上提出了假设,实际场景下存在时钟不一致和时钟跳跃问题,而Redlock恰恰是基于timing的分布式锁
- 另外Redlock由于是基于自动过期机制,依然没有解决长时间的gc pause等问题带来的锁自动失效,从而带来的安全性问题。 接着antirez又回复了Martin Kleppmann的质疑,给出了过期机制的合理性,以及实际场景中如果出现停顿问题导致多个Client同时访问资源的情况下如何处理。
针对Redlock的问题,基于Redis的分布式锁到底安全吗给出了详细的中文说明,并对Redlock算法存在的问题提出了分析。
总结
不论是基于SETNX版本的Redis单实例分布式锁,还是Redlock分布式锁,都是为了保证下特性
安全性:在同一时间不允许多个Client同时持有锁
活性 死锁:锁最终应该能够被释放,即使Client端crash或者出现网络分区(通常基于超时机制) 容错性:只要超过半数Redis节点可用,锁都能被正确获取和释放 所以在开发或者使用分布式锁的过程中要保证安全性和活性,避免出现不可预测的结果。
另外每个版本的分布式锁都存在一些问题,在锁的使用上要针对锁的实用场景选择合适的锁,通常情况下锁的使用场景包括:
Efficiency(效率):只需要一个Client来完成操作,不需要重复执行,这是一个对宽松的分布式锁,只需要保证锁的活性即可;
Correctness(正确性):多个Client保证严格的互斥性,不允许出现同时持有锁或者对同时操作同一资源,这种场景下需要在锁的选择和使用上更加严格,同时在业务代码上尽量做到幂等
在Redis分布式锁的实现上还有很多问题等待解决,我们需要认识到这些问题并清楚如何正确实现一个Redis 分布式锁,然后在工作中合理的选择和正确的使用分布式锁。
















