对于任何应用服务和组件,都需要一套完善可靠谱监控方案。
尤其redis这类敏感的纯内存、高并发和低延时的服务,一套完善的监控告警方案,是精细化运营的前提。
本文分几节,细说Redis的监控和告警:
1.Redis监控告警的价值
2.Redis监控的数据采集
3.Redis告警策略
4.基于Open Falcon的Redis监控告警方案
Redis监控告警的价值
Redis监控告警的价值对每个角色都不同,重要的几个方面:
redis故障快速通知,定位故障点;对于DBA,redis的可用性和性能故障需快速发现和定位解决。
分析redis故障的Root cause
redis容量规划和性能管理
redis硬件资源利用率和成本
redis故障快速发现,定位故障点和解决故障
当redis出现故障时,DBA应在尽可能短时间内发现告警;如果故障对服务是有损的(如大面积网络故障或程序BUG),需立即通知SRE和RD启用故障预案(如切换机房或启用emergency switch)止损。
如果没完善监控告警;假设由RD发现服务故障,再排查整体服务调用链去定位;甚于用户发现用问题,通过客服投诉,再排查到redis故障的问题;整个redis故障的发现、定位和解决时间被拉长,把一个原本的小故障被”无限”放大。
分析redis故障的Root cause
任何一个故障和性能问题,其根本“诱因”往往只有一个,称为这个故障的Root cause。
一个故障从DBA发现、止损、分析定位、解决和以后规避措施;最重要一环就是DBA通过各种问题表象,层层分析到Root cause;找到问题的根据原因,才能根治这类问题,避免再次发生。
完善的redis监控数据,是我们分析root cause的基础和证据。
备注:Troubleshtooing定位Root cause,就像医生通过病人的病历和检查报告找到“真正的病灶”,让病人康复和少受苦,一样有意思和复杂;或像刑警通过案件的证据分析和推理,寻找那个唯一的真相,一样惊心动魄。(快看DBA又在吹牛了),其实在大型商业系统中,一次故障轻松就达直接损失数十万(间接损失更大),那“抓住元凶”,避免它再次“作案”,同样是“破案”。
问题表现是综合情的,一般可能性较复杂,这里举2个例子:
服务调用Redis响应时间变大的性能总是;可能网络问题,redis慢查询,redis QPS增高达到性能瓶颈,redis fork阻塞和请求排队,redis使用swap, cpu达到饱和(单核idle过低),aof fsync阻塞,网络进出口资源饱和等等
redis使用内存突然增长,快达到maxmemory; 可能其个大键写入,键个数增长,某类键平均长度突增,fork COW, 客户端输入/输出缓冲区,lua程序占用等等
Root cause是要直观的监控数据和证据,而非有技术支撑的推理分析。
redis响应抖动,分析定位root casue是bgsave时fork导致阻塞200ms的例子。而不是分析推理:redis进程rss达30gb,响应抖动时应该有同步,fork子进程时,页表拷贝时要阻塞父进程,估计页表大小xx,再根据内存copy连续1m数据要xx 纳秒,分析出可能fork阻塞导致的。(要的不是这种分析)
说明:粮厂有个习惯,在分析root cause尽量能拿到直观证据。因为一旦引入推理步骤,每一步的推理结果都可能出现偏差,最终可能给出错误root cause. “元凶”又逃过一劫,它下次作案估计就会更大。所以建议任何小的故障或抖动,至少从个人或小组内部,深入分析找到root cause;这样个人或组织都会成长快; 形成良好的氛围。
Redis容量规划和性能管理
通过分析redis资源使用和性能指标的监控历史趋势数据;对集群进行合理扩容(Scale-out)、缩容(Scale-back);对性能瓶颈优化处理等。
Redis资源使用饱和度监控,设置合理阀值;
一些常用容量指标:redis内存使用比例,swap使用,cpu单核的饱和度等;当资源使用容量预警时,能及时扩容,避免因资源使用过载,导致故障。
另一方面,如果资源利用率持续过低,及时通知业务,并进行redis集群缩容处理,避免资源浪费。
进一步,容器化管理redis后,根据监控数据,系统能自动地弹性扩容和缩容。
Redis性能监控管理,及时发现性能瓶颈,进行优化或扩容,把问题扼杀在”萌芽期“,避免它”进化“成故障。
Redis硬件资源利用率和成本
从老板角度来看,最关心的是成本和资源利用率是否达标。
如果资源不达标,就得推进资源优化整合;提高硬件利用率,减少资源浪费。砍预算,减成本。
资源利用率是否达标的数据,都是通过监控系统采集的数据。
这一小节,扯了这么多; 只是强调redis不是只有一个端口存活监控就可以了。
下面进入主题,怎么采集redsis监控数。
老板曾说:监控告警和数据备份,是对DBA和SRE最基础也是最高的要求;
当服务和存储达到产品规模后,可认为“无监控,不服务;无备份,不存储”。
Redis监控数据采集
redis监控的数据采集,数据采集1分钟一次,分为下面几个方面:
服务器系统数据采集
Redis Server数据采集
Redis响应时间数据采集
Redis监控Screen
服务器系统监控数据采集
服务器系统的数据采集,这部分包含数百个指标. 采集方式现在监控平台自带的agent都会支持
如Zabbix和Open Falcon等,这里就不介绍采集方法。
我们从redis使用资源的特性,分析各个子系统的重要监控指标。
服务器存活监控
ping监控告警
CPU
平均负载 (Load Average): 综合负载指标(暂且归类cpu子系统),当系统的子系统出现过度使用时,平均负载会升高。可说明redis的处理性能下降(平均响应时间变长、吞吐量降低)。
CPU整体利用率或饱和度 (cpu.busy): redis在高并发或时间复杂度高的指令,cpu整体资源饱和,导致redis性能下降,请求堆积。
CPU单核饱和度 (cpu.core.idle/core=0): redis是单进程模式,常规情况只使用一个cpu core, 单某个实例出现cpu性能瓶颈,导致性能故障,但系统一般24线程的cpu饱和度却很低。所以监控cpu单核心利用率也同样重样。
CPU上下文切换数 (cpu.switches):context swith过高xxxxxx
内存和swap
系统内存余量大小 (mem.memfree):redis是纯内存系统,系统内存必须保有足够余量,避免出现OOM,导致redis进程被杀,或使用swap导致redis性能骤降。
系统swap使用量大小 (mem.swapused):redis的”热数据“只要进入swap,redis处理性能就会骤降; 不管swap分区的是否是SSD介质。OS对swap的使用材质还是disk store. 这也是作者早期redis实现VM,后来又放弃的原因。
说明:系统内存余量合理,给各种缓冲区,fork cow足够的内存空间。
另一个问题:我的系统使用Redis缓存集群,”不怕挂,就怕慢“,或redis集群高可用做得厉害;这样redis的服务器是否能关闭swap呢?
磁盘
磁盘分区的使用率 (df.bytes.used.percent):磁盘空间使用率监控告警,确保有足磁盘空间用AOF/RDB, 日志文件存储。不过 redis服务器一般很少出现磁盘容量问题
磁盘IOPS的饱和度(disk.io.util):如果有AOF持久化时,要注意这类情况。如果AOF持久化,每秒sync有堆积,可能导致写入stall的情况。 另外磁盘顺序吞吐量还是很重要,太低会导致复制同步RDB时,拉长同步RDB时间。(期待diskless replication)
网络
网络吞吐量饱和度(net.if.out.bytes/net.if.in.bytes):如果服务器是千兆网卡(Speed: 1000Mb/s),单机多实例情况,有异常的大key容量导致网卡流量打滿。redis整体服务等量下降,苦于出现故障切换。
丢包率 :Redis服务响应质量受影响
Redis Server监控数据采集
通过redis实例的状态数据采集,采集监控数据的命令
ping,info all, slowlog get/len/reset/cluster info/config get
Redis存活监控
redis存活监控 (redis_alive):redis本地监控agent使用ping,如果指定时间返回PONG表示存活,否则redis不能响应请求,可能阻塞或死亡。
redis uptime监控 (redis_uptime):uptime_in_seconds
Redis 连接数监控
连接个数 (connected_clients):客户端连接个数,如果连接数过高,影响redis吞吐量。常规建议不要超过5000.参考 官方benchmarks
连接数使用率(connected_clients_pct): 连接数使用百分比,通过(connected_clients/macclients)计算;如果达到1,redis开始拒绝新连接创建。
127.0.0.1:6380> set mykey myvalue
(error) ERR max number of clients reached
127.0.0.1:6380>
- 1.
- 2.
- 3.
拒绝的连接个数(rejected_connections): redis连接个数达到maxclients限制,拒绝新连接的个数。
新创建连接个数 (total_connections_received): 如果新创建连接过多,过度地创建和销毁连接对性能有影响,说明短连接严重或连接池使用有问题,需调研代码的连接设置。
list阻塞调用被阻塞的连接个数 (blocked_clients): BLPOP这类命令没使用过,如果监控数据大于0,还是建议排查原因。
Redis内存监控
redis分配的内存大小 (used_memory): redis真实使用内存,不包含内存碎片;单实例的内存大小不建议过大,常规10~20GB以内。
redis内存使用比例(used_memory_pct): 已分配内存的百分比,通过(used_memory/maxmemory)计算;对于redis存储场景会比较关注,未设置淘汰策略(maxmemory_policy)的,达到maxmemory限制不能写入数据。
127.0.0.1:6380> setmykey myvalue
(error) OOM commandnot allowed when used memory >'maxmemory'.
127.0.0.1:6380>
- 1.
- 2.
- 3.
redis进程使用内存大小(used_memory_rss): 进程实际使用的物理内存大小,包含内存碎片;如果rss过大导致内部碎片大,内存资源浪费,和fork的耗时和cow内存都会增大。
redis内存碎片率 (mem_fragmentation_ratio): 表示(used_memory_rss/used_memory),碎片率过大,导致内存资源浪费;
说明:
1、如果内存使用很小时,mem_fragmentation_ratio可以远大于1的情况,这个告警值不好设置,需参考used_memory大小。
2、如果mem_fragmentation_ratio小于1,表示redis已使用swap分区
Redis综合性能监控
Redis Keyspace
redis键空间的状态监控
键个数 (keys): redis实例包含的键个数。建议控制在1kw内;单实例键个数过大,可能导致过期键的回收不及时。
设置有生存时间的键个数 (keys_expires): 是纯缓存或业务的过期长,都建议对键设置TTL; 避免业务的死键问题. (expires字段)
估算设置生存时间键的平均寿命 (avg_ttl): redis会抽样估算实例中设置TTL键的平均时长,单位毫秒。如果无TTL键或在Slave则avg_ttl一直为0
LRU淘汰的键个数 (evicted_keys): 因used_memory达到maxmemory限制,并设置有淘汰策略的实例;(对排查问题重要,可不设置告警)
过期淘汰的键个数 (expired_keys): 删除生存时间为0的键个数;包含主动删除和定期删除的个数。
Redis qps
redis处理的命令数 (total_commands_processed): 监控采集周期内的平均qps,
redis单实例处理达数万,如果请求数过多,redis过载导致请求堆积。
redis当前的qps (instantaneous_ops_per_sec): redis内部较实时的每秒执行的命令数;可和total_commands_processed监控互补。
Redis cmdstat_xxx
这小节讲解,redis记录执行过的所有命令; 通过info all的Commandstats节采集数据.
每类命令执行的次数 (cmdstat_xxx): 这个值用于分析redis抖动变化比较有用
以下表示:每个命令执行次数,总共消耗的CPU时长(单个微秒),平均每次消耗的CPU时长(单位微秒)
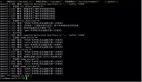
# Commandstatscmdstat_set:calls=6,usec=37,usec_per_call=6.17cmdstat_lpush:calls=4,usec=32,usec_per_call=8.00cmdstat_lpop:calls=4,usec=33,usec_per_call=8.25
- 1.
Redis Keysapce hit ratio
redis键空间请求命中率监控,通过此监控来度量redis缓存的质量,如果未命中率或次数较高,可能因热点数据已大于redis的内存限制,导致请求落到后端存储组件,可能需要扩容redis缓存集群的内存容量。当然也有可能是业务特性导致。
请求键被命中次数 (keyspace_hits): redis请求键被命中的次数
请求键未被命中次数 (keyspace_misses): redis请求键未被命中的次数;当命中率较高如95%,如果请求量大,未命中次数也会很多。可参考Baron大神写的 Why you should ignore MySQL’s key cache hit ratio
请求键的命中率 (keyspace_hit_ratio):使用keyspace_hits/(keyspace_hits+keyspace_misses)计算所得,是度量Redis缓存服务质量的标准
Redis fork
redis在执行BGSAVE,BGREWRITEAOF命令时,redis进程有 fork 操作。而fork会对redis进程有个短暂的卡顿,这个卡顿redis不能响应任务请求。所以监控fork阻塞时长,是相当重要。
如果你的系统不能接受redis有500ms的阻塞,那么就要监控fork阻塞时长的变化,做好容量规划。
最近一次fork阻塞的微秒数 (latest_fork_usec): 最近一次Fork操作阻塞redis进程的耗时数,单位微秒。
redis network traffic
redis一般单机多实例部署,当服务器网络流量增长很大,需快速定位是网络流量被哪个redis实例所消耗了; 另外redis如果写流量过大,可能导致slave线程“客户端输出缓冲区”堆积,达到限制后被Maser强制断开连接,出现复制中断故障。所以我们需监控每个redis实例网络进出口流量,设置合适的告警值。
说明:网络监控指标 ,需较高的版本才有,应该是2.8.2x以后
redis网络入口流量字节数 (total_net_input_bytes)
redis网络出口流量字节数 (total_net_output_bytes)
redis网络入口kps (instantaneous_input_kbps)
redis网络出口kps (instantaneous_output_kbps)
前两者是累计值,根据监控平台1个采集周期(如1分钟)内平均每秒的流量字节数。
Redis慢查询监控
redis慢查询 是排查性能问题关键监控指标。因redis是单线程模型(single-threaded server),即一次只能执行一个命令,如果命令耗时较长,其他命令就会被阻塞,进入队列排队等待;这样对程序性能会较大。
redis慢查询保存在内存中,最多保存slowlog-max-len(默认128)个慢查询命令,当慢查询命令日志达到128个时,新慢查询被加入前,会删除最旧的慢查询命令。因慢查询不能持久化保存,且不能实时监控每秒产生的慢查询个数。
我们建议的慢查询监控方法:
设置合理慢查询日志阀值,slowlog-log-slower-than, 建议1ms(如果平均1ms, redis qps也就只有1000)
设置全理慢查询日志队列长度,slowlog-max-len建议大于1024个,因监控采集周期1分钟,建议,避免慢查询日志被删除;另外慢查询的参数过多时,会被省略,对内存消耗很小
每次采集使用slowlog len获取慢查询日志个数
每次彩集使用slowlog get 1024 获取所慢查询,并转存储到其他地方,如MongoDB或MySQL等,方便排查问题;并分析当前慢查询日志最长耗时微秒数。
然后使用slowlog reset把慢查询日志清空,下个采集周期的日志长度就是最新产生的。
redis慢查询的监控项:
redis慢查询日志个数 (slowlog_len):每个采集周期出现慢查询个数,如1分钟出现10次大于1ms的慢查询
redis慢查询日志最长耗时值 (slowlog_max_time):获取慢查询耗时最长值,因有的达10秒以下的慢查询,可能导致复制中断,甚至出来主从切换等故障。
Redis持久化监控
redis存储场景的集群,就得 redis持久化 保障数据落地,减少故障时数据丢失。这里分析redis rdb数据持久化的几个监控指标。
最近一次rdb持久化是否成功 (rdb_last_bgsave_status):如果持久化未成功,建议告警,说明备份或主从复制同步不正常。或redis设置有”stop-writes-on-bgsave-error”为yes,当save失败后,会导致redis不能写入操作
最近一次成功生成rdb文件耗时秒数 (rdb_last_bgsave_time_sec):rdb生成耗时反应同步时数据是否增长; 如果远程备份使用redis-cli –rdb方式远程备份rdb文件,时间长短可能影响备份线程客户端输出缓冲内存使用大小。
离最近一次成功生成rdb文件,写入命令的个数 (rdb_changes_since_last_save):即有多少个写入命令没有持久化,最坏情况下会丢失的写入命令数。建议设置监控告警
离最近一次成功rdb持久化的秒数 (rdb_last_save_time): 最坏情况丢失多少秒的数据写入。使用当前时间戳 - 采集的rdb_last_save_time(最近一次rdb成功持久化的时间戳),计算出多少秒未成功生成rdb文件
Redis复制监控
不论使用何种redis集群方案, redis复制 都会被使用。
复制相关的监控告警项:
redis角色 (redis_role):实例的角色,是master or slave
复制连接状态 (master_link_status): slave端可查看它与master之间同步状态;当复制断开后表示down,影响当前集群的可用性。需设置监控告警。
复制连接断开时间长度 (master_link_down_since_seconds):主从服务器同步断开的秒数,建议设置时长告警。
主库多少秒未发送数据到从库 (master_last_io_seconds):如果主库超过repl-timeout秒未向从库发送命令和数据,会导致复制断开重连。详细分析见文章: Redis复制中断和无限同步问题 。 在slave端可监控,建议设置大于10秒告警
从库多少秒未向主库发送REPLCONF命令 (slave_lag): 正常情况从库每秒都向主库,发送REPLCONF ACK命令;如果从库因某种原因,未向主库上报命令,主从复制有中断的风险。通过在master端监控每个slave的lag值。
从库是否设置只读 (slave_read_only):从库默认只读禁止写入操作,监控从库只读状态;
如果关闭从库只读,有写入数据风险。关于主从数据不一致,见文章分析: Redis复制主从数据不-致
主库挂载的从库个数 (connected_slaves):主库至少保证一个从库,不建议设置超过2个从库。
复制积压缓冲区是否开启 (repl_backlog_active):主库默认开启复制积压缓冲区,用于应对短时间复制中断时,使用 部分同步 方式。
复制积压缓冲大小 (repl_backlog_size):主库复制积压缓冲大小默认1MB,因为是redis server共享一个缓冲区,建议设置100MB.
说明: 关于根据实际情况,设置合适大小的复制缓冲区。可以通过master_repl_offset指标计算每秒写入字节数,同时乘以希望多少秒内闪断使用“部分同步”方式。
Redis集群监控
这里所写 redis官方集群方案 的监控指标
数据基本通过cluster info和info命令采集。
实例是否启用集群模式 (cluster_enabled): 通过info的cluster_enabled监控是否启用集群模式。
集群健康状态 (clusster_state):如果当前redis发现有failed的slots,默认为把自己cluster_state从ok个性为fail, 写入命令会失败。如果设置cluster-require-full-coverage为NO,则无此限制。
集群数据槽slots分配情况 (cluster_slots_assigned):集群正常运行时,默认16384个slots
检测下线的数据槽slots个数 (cluster_slots_fail):集群正常运行时,应该为0. 如果大于0说明集群有slot存在故障。
集群的分片数 (cluster_size):集群中设置的分片个数
集群的节点数 (cluster_known_nodes):集群中redis节点的个数
Redis响应时间监控
响应时间 是衡量一个服务组件性能和质量的重要指标。使用redis的服务通常对响应时间都十分敏感,比如要求99%的响应时间达10ms以内。
因redis的慢查询日志只计算命令的cpu占用时间,不会考虑排队或其他耗时。
最长响应时间 (respond_time_max):最长响应时间的毫秒数
99%的响应时间长度 (respond_time_99_max):
99%的平均响应时间长度 (respond_time_99_avg):
95%的响应时间长度 (respond_time_95_max):
95%的平均响应时间长度 (respond_time_95_avg):
响应时间监控的方式建议,最简单方法,使用 Percona tcprstat