或许你曾经去面试的时候被问到过关于mysql数据库的存储过程和触发器的问题,如果你还不懂可以看下这篇关于存储过程和触发器的文章,希望能帮助到有需要的朋友。
Mysql存储过程与触发器
本篇文章主要是简单解释mysql中存储过程的创建、调用以及介绍触发器和如何创建触发器。那么关于存储过程和触发器那些官方理论的介绍我就不在这里啰嗦了。
1数据表的准备
下面所有例子中用到的表的创建脚本。tb_user是下面例子中的用户表,tb_blog是博客表,tb_user_log是用户信息更新日记表。
- use db_mybatis;
- create table tb_user(
- id int(11) unsigned not null auto_increment,
- uname varchar(50) not null,
- pwd varchar(50) not null,
- primary key (id)
- )engine=InnoDB default charset=utf8;
- create table tb_blog(
- id int(11) unsigned not null auto_increment,
- title varchar(50) not null,
- details varchar(50) not null,
- create_date datetime not null,
- update_date datetime not null,
- primary key (id)
- )engine=InnoDB default charset=utf8;
- create table tb_user_log(
- id int(11) unsigned not null auto_increment,
- create_date datetime not null,
- details varchar(255) not null,
- primary key (id)
- )engine=InnoDB default charset=utf8;
2“delimiter //”的解释
mysql默认以';'作为语句结束符。我们都知道,在mysql命令行模式下,当输入一条语句时,如果不加‘;’回车是不会执行输入的sql语句的。如:
- mysql> select * from tb_blog
- ->
- ->
- ->
- ->
- -> ;
- +----+--------+--------------+---------------------+---------------------+
- | id | title | details | create_date | update_date |
- +----+--------+--------------+---------------------+---------------------+
- | 2 | dsssss | 这是内容 | 2018-08-13 02:42:44 | 2018-08-15 16:39:16 |
- | 3 | new1 | 这是内容 | 2018-08-13 02:42:44 | 2018-08-13 22:04:21 |
- | 4 | new2 | 这是内容 | 2018-08-13 02:42:44 | 2018-08-13 22:04:21 |
- | 5 | new3 | 这是内容 | 2018-08-13 02:42:44 | 2018-08-13 22:04:21 |
- | 6 | new4 | 这是内容 | 2018-08-13 02:42:44 | 2018-08-13 22:04:21 |
- +----+--------+--------------+---------------------+---------------------+
- 5 rows in set (0.01 sec)
而delimiter的作用就是修改语句结束符,如delimiter &就是将sql语句的结束为定义为'&'符号,当遇到'&'符号时,mysql判断为语句输入完成就会执行,看下面例子:
- mysql> delimiter &
- mysql> select * from tb_blog
- ->
- -> &
- +----+--------+--------------+---------------------+---------------------+
- | id | title | details | create_date | update_date |
- +----+--------+--------------+---------------------+---------------------+
- | 2 | dsssss | 这是内容 | 2018-08-13 02:42:44 | 2018-08-15 16:42:54 |
- | 3 | new1 | 这是内容 | 2018-08-13 02:42:44 | 2018-08-13 22:04:21 |
- | 4 | new2 | 这是内容 | 2018-08-13 02:42:44 | 2018-08-13 22:04:21 |
- | 5 | new3 | 这是内容 | 2018-08-13 02:42:44 | 2018-08-13 22:04:21 |
- | 6 | new4 | 这是内容 | 2018-08-13 02:42:44 | 2018-08-13 22:04:21 |
- +----+--------+--------------+---------------------+---------------------+
- 5 rows in set (0.00 sec)
所以,delimiter //的作用是将'//'作为语句的结束符,'//'可以是其他的字符,比如上面例子中使用'&';
那么为什么编写存储过程和触发器我们需要将默认的';'修改为'//'作为sql语句结束符呢?因为我们要在存储过程或触发器中执行sql语句,所以会用到';',如果不改其它符号而使用';'作为语句结束符的话,mysql遇到';'就当作一条语句完成了,而存储过程或触发器的sql语句都没写完全呢,这样只会ERROR。
注意,在使用delimiter //将sql语句结束符改为'//'用完后(如完成创建存储过程)记得要使用delimiter ;将sql语句结束符改回为默认。
3存储过程
先来看两个简单的存储过程实例,对存储过程的创建和调用有一个模糊的印象。
- #实例一:创建查询所有博客的存储过程
- drop procedure if exists select_procedure
- delimiter //
- create procedure select_procedure()
- begin
- select * from tb_blog;
- end //
- delimiter ;
- #调用
- call select_procedure;
- #实例二:更新博客修改时间的存储过程
- drop procedure if exists update_blog_updatedate;
- delimiter //
- create procedure update_blog_updatedate(blogid int(11))
- begin
- update tb_blog set update_date = sysdate() where id = blogid;#sysdate()获取当前日期+时间字符串(24小时格式)
- end //
- delimiter ;
- #调用
- call update_blog_updatedate(2);
好,下面我通过一个简单的存储过程实例来分析如何创建一个存储过程。先看例子:
- #创建更新博客标题的存储过程
- drop procedure if exists update_blog;#如果存在该存储过程先删除
- delimiter //
- create procedure update_blog(blogid int(11))
- begin
- start transaction;#开启事务
- update tb_blog set title='dsssss' where id=blogid;#要做的事情
- commit;#提交事务
- end //
- delimiter ;
上面实际创建存储过程的语句为
- create procedure update_blog(blogid int(11))#(参数1 参数类型(长度),参数2 参数类型(长度),...)
- begin
- start transaction;#开启事务
- update tb_blog set title='dsssss' where id=blogid;#要做的事情
- commit;#提交事务
- end //
end后面的'//'是sql语句结束符,就是前面用delimiter //修改的sql语句结束符,所以从create到//就是一条完整的创建存储过程的sql语句。那么为什么还要在前面加一条drop procedure if exists update_blog?其实你可以不加的,这条语句的作用只是当要创建的存储过程已经存在同名的存储过程时将已经存在的存储过程删除。
现在再来解析创建存储过程的这条语句,其中,update_blog时存储过程的名称,()内是调用该存储过程时要传递的参数,参数个数不限制,参数间用','分割,参数要声明类型,如blogid int(11),blogid就是参数名,int是类型,如果要指定长度则在类型后面加'(长度)'。
begin和end之间就是存储过程要做的事情。
使用call+存储过程名称来调用存储过程,如果存储过程定义了参数,那么需要在调用的时候传入参数,否则调用失败。
- call update_blog(2);#调用存储过程
下面来看一个稍微成型点的存储过程。
- # 创建批量更新的存储过程
- drop procedure if exists update_all_blog_date;
- delimiter //
- create procedure update_all_blog_date()
- begin
- declare id_index int(11) default 0;#定义变量id_index,类型为int,默认值为0
- declare blog_count int default 0;
- declare bid int;
- select count(*) into blog_count from tb_blog;#into blog_count 将查询结果赋值给blog_count变量
- if blog_count>0 then
- #start transaction;
- while id_index<=blog_count do
- #update tb_blog set update_date = sysdate() where id in
- #(select tb.id from (select id from tb_blog limit id_index,1) as tb);
- #set id_index=id_index+1;
- select id into bid from tb_blog limit id_index,1;
- update tb_blog set update_date = sysdate() where id = bid;
- set id_index=id_index+1;
- end while;
- #commit;
- end if;
- end //
- delimiter ;
- call update_all_blog_date;
解析:
declare是定义变量的关键字,可以理解为javascript中的var关键字。定义变量必须是在存储过程的内部,即begin和end之间。变量的定义方式是declare关键字加变量名加变量类型,如果想指定默认值就在类型后面加上“default 默认值”。
select count(*) into blog_count from tb_blog语句是获取tb_blog表的总数赋值给blog_count,将查询结果赋值给某个变量使用into关键字。
set关键字是修改变量的值,将一个新的值写给set指定的变量。其它的就不做解释了,看不懂就需要学一下mysql的条件语句与循环语句了。
4Mysql中的触发器
触发器是什么?
触发器就是一个函数,当满足某种条件时才会触发其执行。
什么情况下使用触发器?
比如我们要为用户所做的个人信息修改记录一条变更日记,那么是不是需要在修改完用户信息之后添加一条日记记录?如果不使用触发器我们就需要执行两条sql语句,***条是修改用户信息的sql语句,第二条是添加一个日记记录的sql语句。我们在写业务逻辑代码的时候如果在多处地方可能对用户信息修改,在某处忘记了写日记记录也不奇怪。而如果使用触发器,当用户信息修改时触发触发器执行添加一条日记记录,这样也会比在业务代码中执行两条sql语句效率要高。
那么如果创建一个触发器呢?
- create trigger 触发器名称 after|before insert|delete|update on 表名 for each row
- begin
- #触发器要做的事情
- end
- 表名:将改触发器的触发条件挂载在哪张表上,也就是指定哪张表的操作满足条件时触发该触发器。
- 触发器执行时机:after或者before,即之前还是之后。
- 触发的条件:insert|delete|update 即可选增删改时触发;比如alter insert,就是在添加完成之后触发,执行时机与触发条件可随意组合使用,即
before insert
before delete
before update
after insert
after delete
after update
- for each row表示任何一条记录的操作满足触发条件都会触发触发器执行。
下面来看一个实例:在用户信息表tb_user中的记录被修改之后添加一条日记记录,记录修改时间和修改内容。
- drop trigger if exists on_user_info_chang_log;
- delimiter //
- create trigger on_user_info_chang_log after update on tb_user for each row
- begin
- declare info varchar(255) charset utf8 default '';
- set info = '修改之前的信息为:[';
- set info = concat(info,NEW.uname);
- set info = concat(info,',');
- set info = concat(info,New.pwd);
- set info = concat(info,'],修改之前的信息为:[');
- set info = concat(info,OLD.uname);
- set info = concat(info,',');
- set info = concat(info,OLD.pwd);
- insert into tb_user_log (create_date,details) value(sysdate(),info);
- end //
- delimiter ;
解析:
- concat函数是字符串拼接函数
- NEW是修改后的新的记录
- OLD是修改前的旧的纪录
- sysdate函数是获取当前系统日期时间字符串
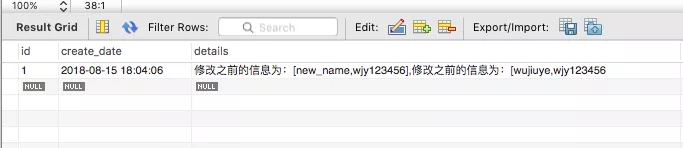
下面我们执行一条sql来触发该触发器
- update tb_user set uname='new_name' where id = 1;
查看日记表中是否添加了一条记录。