在互联网时代,数据是所有应用的基础,淘宝的商家可以基于商品历史的点击成交量来判断店内各个商品的情况,并做出相应的运营行为,淘宝的买家会根据商品历史的成交数据,评论数据等,来辅助自己判断是否进行购买,同时我们平台也会基于用户和商品的历史数据,来训练模型,预测各个商品的点击率,预测各个用户的偏好,使展示的结果更符合用户的需求。可以看出,数据对于各个不同的角色都有很重要的作用。
在互联网中,获取数据相对容易,反观线下零售场景,大部分数据都是缺失的,商家并不知道店内多少商品被浏览了,多少商品被试穿了,买家也不知道各件商品的历史数据。
因此,我们的客流数字化相关的探索,就是要将线下的用户和商品的行为数据收集起来,让线下的行为也能有迹可循,为商业决策和市场运营提供准确有效的数据支撑,将传统零售中的导购经验逐渐数字化成可量化和统计的数字指标,能够辅助商家运营,同时帮助用户进行决策。基于这些数据,也能够让算法在线下发挥更大的作用。
整体方案
整体方案如下图所示,方案涉及场外的选品策略指导,线下引流,进店的人群画像,顾客轨迹跟踪,人货交互数据沉淀,试衣镜互动/推荐,以及离店后的线上二次触达。从场外到场内再到线上,构成了整体全流程的产品方案。
客流数字化探索
在门店客流数字化的探索中,硬件部署上,我们使用了门店已有的监控摄像头和RFID标签,并结合视觉及射频相关技术,通过在门店部署GPU终端进行计算。技术方案上,我们基于人脸识别技术,识别进店用户的性别,年龄,新老客等基础属性,并通过行人检测跟踪与跨摄像头的行人重识别技术跟踪用户在门店内的动线变化,同时得到整体门店各个区域的热力图分布,此外,还通过摄像头与RFID 多传感器融合的技术识别用户在门店内的行为,包括翻动,试穿等,精确定位门店内各个商品的浏览与试穿频次以及用户在线下的偏好。下面会主要介绍其中的行人检测,行人重识别和动作识别这3个技术方向相关的优化。
行人检测
在新零售的客流数字化场景中,我们需要通过监控摄像头对门店客流的进店频次、性别、动作、行为轨迹、停留时间等全面的记录和分析。要达到我们的目标,首先需要能够检测并识别出摄像头中的行人。
虽然目前YOLO等目标检测算法可以做到近乎实时的计算性能,但其评估环境都是Titan X、M40等高性能GPU,且只能支持单路输入。无论从硬件成本或是计算能力方面考虑,这些算法都无法直接应用到真实场景中。当然YOLO官方也提供了像YOLOv3-Tiny这种轻量级的模型方案,但模型性能衰减过大,在COCO上mAP下降超过40%。同时现有目标检测方案的泛化能力还比较弱,不同场景的差异对模型性能会造成较大的影响。门店场景下的视角、光线、遮挡、相似物体干扰等情况与开源数据集差异较大,直接使用基于VOC、COCO数据集训练的模型对该场景进行检查,效果非常不理想。我们分别针对模型的性能和在实际数据集的效果两方面做了相应的优化。
网络结构精简与优化
我们在YOLO框架的基础上对模型进行改进,实现了一种轻量级实时目标检测算法,在服饰门店的真实场景下,和YOLOv3相比,模型性能下降不超过2%,模型大小缩小至原来的1/10,在Tesla P4上对比FPS提升268%,可直接部署到手机、芯片等边缘设备上,真实业务场景中一台GTX1070可以同时支持16路摄像机同时检测,有效节约了门店改造的经济成本。
标准YOLOv3的网络结构有106层,模型大小有237M,为了设计一个轻量级的目标检测系统,我们使用Tiny DarkNet来作为骨干网络,Tiny DarkNet是一个极简的网络结构,最大通道数为512,模型大小仅4M,该模型结构比YOLO官方的YOLOv3-Tiny的骨干网络还要精简,但精简网络会造成特征抽取能力的衰减,模型性能下降剧烈,在我们人工标注的2万多张服饰门店场景数据集上,替换后的Tiny DarkNet + FPN结构较原生结构的AP-50(IOU=0.5)下降30%。我们在特征抽取网络之后进行Spatial Pyramid Pooling[10],与原特征一起聚合,之后通过下采样与反卷积操作将不同层级特征合并,希望将底层的像素特征和高层的语义特征进行更充分的融合来弥补特征抽取能力的下降,整体网络结构如下图所示,精简后的检测模型大小约为原来的1/10。
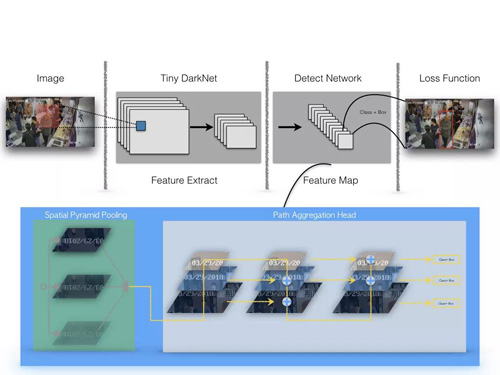
目标检测网络结构
知识蒸馏进一步优化
知识蒸馏[2]通过Teacher Network输出的Soft Target来监督Student Network学习网络中Dark Knowledge,以实现Knowledge Transfer的目的,与量化、剪枝、矩阵近似等方法常被用来实现对模型的压缩。但蒸馏与量化等方法之间又是可以互相结合的,而且蒸馏本身对模型的修改更加透明,无需特殊的依赖及执行框架。
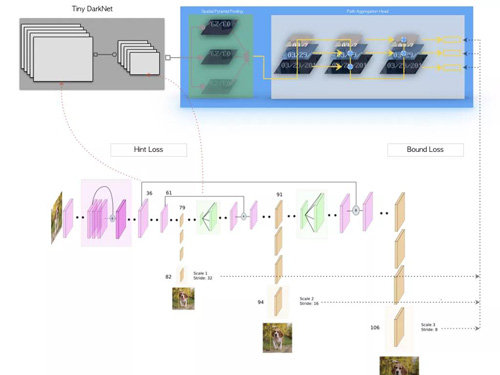
知识蒸馏网络结构
上图是我们网络蒸馏的模型结构设计,蒸馏时我们采用原生YOLOv3作为Teacher Network,虽然YOLOv3拥有较好的检测性能,且结构上与我们的模型比较相似,但直接在二者输出层之间建立L2约束,无法克服Teacher Network中的噪声及回归预测的波动,结果反而抑制了Student Network的学习。实验中发现Hint Layer的损失设计和回归预测的不确定性是蒸馏效果的核心问题,强行在对应Channel之间建立损失约束的方式过于严苛。对于普通卷积而言,我们无需要求Teacher / Student Network的Input Channel顺序保持一致,仅需要整个输入的分布是一致的。每个Channel相当于一次采样结果,相同的分布,采出的样本顺序可能多种多样,但整体结果符合相同分布,同时经过激活函数的Channel分布不再稳定,需要进行归一处理。为了避免Teacher Network回归预测本身的不稳定,回归损失设计时仍以Ground Truth为目标,将Teacher Network的Output作为Bound,仅对误差大于Teacher Network的部分进行约束,本质上是在借Teacher Network来进行Online Hard Example Mining。
行人重识别
行人重识别(Person Re-identification)问题是指在跨摄像头场景下,给定待查找的行人图片,查找在其他摄像头是否出现该人。一般用来解决跨摄像头追踪。在线下门店场景中,每个门店都会在各个不同的区域安装摄像头,当顾客在店内逛时,我们需要了解用户是如何在各个区域之间活动,了解各个区域客流的去向与来源,因此需要将各个不同摄像头中同一个行人进行关联。
行人特征提取
行人重识别的难点在于,多个摄像头下拍摄行人的角度不同,图像中的行人可能72变,同时还有可能会有不同程度的遮挡,导致直接使用整体的行人特征来做重识别非常具有挑战性,那能不能用人脸识别做行人重识别?理论上是可以的,但是在实际场景中非常难应用,首先,广泛存在后脑勺和侧脸的情况,做正脸的人脸识别难,其次,摄像头拍摄的像素可能不高,尤其是远景摄像头里面人脸截出来很可能都没有32x32的像素。所以人脸识别在实际的重识别应用中存在很大的限制。
行人重识别问题中,如何学得一个鲁棒的行人特征表示成为了一个很关键的问题。学得行人特征表示最直观的方式是直接以整张行人图片作为输入,提取一个全局特征,全局特征的目标是学到能够区分不同行人之间最突出的信息,比如衣服颜色等,来区分这个行人。然而监控场景的复杂性,使得这样的方法的准确性受到了很大的限制,比如,各个摄像头之间存在色差,并且门店的不同区域的光照条件会有差异,此外,还有很多穿相似服装的行人。同时由于目前行人重识别数据集在体量及丰富性上有比较大的欠缺,一些不突出,不频繁出现的细节特征在全局特征的训练中很容易被忽略。
要解决上面提到的问题,使用局部特征替换全局特征是一个比较好的解决方案,基于局部特征的行人重识别方法将原始输入表示成多个特征块,每一个特征块代表一个局部的特征,基于局部特征的方法能够更关注行人的局部细节方面的特征。
基于局部特征的方法,也存在一些问题,这一类方法将行人划分为各个独立的语义分块,并没有考虑各个局部特征之间的关联,因此,在我们的方案中,我们使用到了多级局部特征的融合方案,在考虑各个局部特征的同时考虑多个局部特征的关联关系,具体网络结构如下图所示,在原始的局部特征的基础之上增加了多个不同尺度的局部特征以及全局特征,学到的特征不仅能够表示各个部位的细节特征,还能表达不同部位融合在一起的特征,相较原始版本更加丰富化。
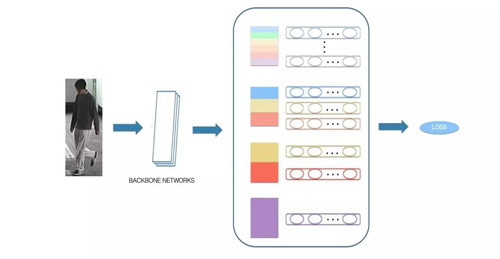
目前基于此版本模型还在持续优化中,在Market数据集上Rank@1能达到96.19%,使用同样骨干网络结构的情况下提取全局特征的版本的Rank@1只能达到89.9%,而仅使用local特征的版本Rank@1能够达到92.5%,融合的方案相比两个版本均有较明显的提升。
跨数据集的行人重识别的探索与尝试
由于线下场景的特殊性,我们的模型需要部署到各家不同的门店,各个门店的光线,环境存在很大的差异,不同门店的摄像头安装的角度也会有些许不同,因此我们在一个数据集上训练的模型可能并不适用于所有门店,然而我们又不可能逐家门店去做数据的标注,因此,我们想通过一种方式,让我们的模型能够自适应到新的门店的数据中。
在门店中,由于顾客是在一个封闭空间,因此顾客在各个摄像头之间的转移是存在一定的规律的,比如说:顾客肯定是最先出现在门口的摄像头,顾客只能在相邻的两个区域之间进行转移等,基于门店场景的特性,我们首先尝试了基于摄像头时空信息的混合模型,参考[7],模型结构如下图所示:
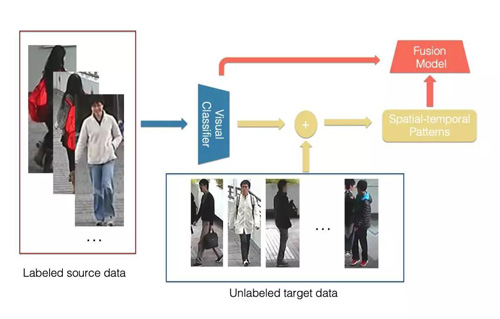
混合模型首先基于原始的视觉特征的分类器来计算各个摄像头以及不同时间间隔之间转移的概率分布,再使用时空信息与原始分类器结合得到最终的结果。
人货动作检测
除了基础的客流动线数据以外,顾客在门店中的行为数据也是非常有价值的,我们尝试使用视觉结合RFID射频信号的融合方案,试图解决顾客在门店中与货物的交互问题,即哪个顾客在什么地点翻动/拿起了哪一件商品,比较类似线上的点击数据。
人货交互的数据在线下是很重要的一个环节,人货交互的数据可以让商家知道哪些商品被翻动的多,了解哪些商品比较能够吸引顾客,哪一类顾客更喜欢哪些风格的商品,同时这一部分数据也完善了整个门店的漏斗转化,以前商家仅仅能根据成交来判定每个商品的受欢迎程度,而有些潜在畅销款可能是由于摆放的位置不恰当,导致可能根本没有顾客仔细看到,导致最终成交额较低,同时有的商品虽然成交笔数不少,但是实际上被顾客拿起的次数也特别多,可能是因为这件商品在一个更显眼的位置,相比同样成交笔数的拿起次数较少的商品,实际转化率更低。补全这个环节的数据对商家的线下运营有很关键的作用,同时这一部分行为数据在商家线上线下商品打通之后为线上服务起到最重要的作用。
人货交互的数据是目前线下数据缺失的比较严重的环节,商家一般都能很容易的拿到商品的成交的统计数据,而人货交互的数据由于发生更频繁,且不易判断,因此整体数据的收集难度比较高,此外人货交互的数据需要精确到具体的SKU,单纯的顾客发生了动作并没有太大的意义,因此在人货动作检测的方案上,我们设计了一套结合视觉技术和RFID射频信号的融合方案,得到最终的人货交互数据。下图为整体方案:
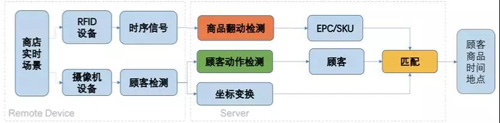
门店中装配有监控摄像机设备与RFID接收器器设备,分别录制实时视频与RFID标签受激反射的 时序信号,首先基于回传的RFID信号与检测哪些RFID标签可能被翻动了,由于店铺服务员已经将RFID标签的EPC编号与商品的 SKU编号关联入库,基于被翻动的标签EPC编号可以取到对应商品的SKU,同时,使用回传的顾客图片检测出疑似有在翻动商品的顾客,并根据顾客的图像坐标进行坐标变换,得到该顾客的真实物理坐标,最后,将检测出的疑似被翻动的商品与疑似有翻动商品动作的顾客进行关联,得到商品与行人的最佳匹配。
其中基于RFID射频技术的商品动作识别是一个比较新的尝试。当顾客翻动衣服时,衣服上的RFID标签会随之发生微小抖动,RFID接收机设备记录标签反射的信号RSSI,Phase等特征值的变化,回传到后台,算法通过对每个天线回传的信号值进行分析判断商品是否发生翻动。基于RFID信号判断商品翻动存在诸多问题,包括信号自身噪声、环境多径效应、偶然电磁噪声、货柜对信号遮挡的影响等。同时RFID反射信号的大小与接收器离标签距离远近存在非线性关系,
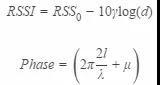
其中,d代表RFID标签与接收器之间距离, ,受Multipath和当前环境的影响
,受Multipath和当前环境的影响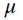 表示各种静态设备误差带来的偏移。从公式中可以看出,接收器安装的位置,商店环境等都会给RFID信号带来很大影响,寻找统一的可以适用于不同商店、不同位置接收器的翻动判断算法存在很大挑战。最初的版本我们使用RSSI和Phase的原始值作为特征值来训练模型,这样的模型存在一个问题,在我们的样本不充足的情况下,受环境的影响较大,在真实环境中往往不能达到离线测试的结果,因此,我们试图基于原始的信号值产生于空间位置不那么强相关的特征值来辅助动作的判断。
表示各种静态设备误差带来的偏移。从公式中可以看出,接收器安装的位置,商店环境等都会给RFID信号带来很大影响,寻找统一的可以适用于不同商店、不同位置接收器的翻动判断算法存在很大挑战。最初的版本我们使用RSSI和Phase的原始值作为特征值来训练模型,这样的模型存在一个问题,在我们的样本不充足的情况下,受环境的影响较大,在真实环境中往往不能达到离线测试的结果,因此,我们试图基于原始的信号值产生于空间位置不那么强相关的特征值来辅助动作的判断。
虽然频率信息中的幅度信息与空间位置存在关系,但是当我们只关注于频率分布(不同频率成份的占比)时,可以将频率信息也当成与空间位置信息无关的特征。频率信息的获取需要对RSSI信号与Phase信号进行离散傅利叶变换, 然后统计频率信号与相位信号的分布图。对得到的分布图,计算当前分布与前一个时刻分布的JS散度(相对于KL散度,JS散度具有加法的对称性,因此可以用来衡量多个分布之间的相对距离)。
基于相邻时刻前后两个样本的JS散差异的版本在我们的测试数据上能够达到94%的识别精度,相比最初版本基于原始的RSSI值和phase值作为特征的版本的91.9%的精度,有一定的提升。
基于图像的顾客动作检测是经典的分类问题,为了减小对计算能力的需求,我们使用了:MobileNet[12]对行人检测的图像进一步分类,并根据模型Logits输出进行了最优化参数寻优,在保持分类精度时,提高正例召回率,确保正例尽可能被召回,如下图所示。
我们通过时间关联程度与动作可疑程度两个维度同时进行匹配,使得最终的匹配行人与翻动商品的准确率达到85.8%。
客流数字化应用
客流数字化产出的客流相关数据不仅仅用于商家的线下运营,同时我们也基于这部分数据在线下场的流量分发上有一些初步应用,淘宝是线上的一个很大的流量分发的入口,淘宝的搜索和推荐决定了消费者当前能看到哪些商品,也同时影响了各个商家和商品的整体流量情况,搜索和推荐就是将商家、商品和用户做匹配,将适当的商品展示给合适的用户,满足消费者的购物体验的同时,也平衡各个商家商品的流量分配,避免流量的浪费,实现流量的最大化的价值。
在线下商场,也有一样的流量分发的需求。但是线下场相比线上,有两个比较大的挑战:1) 线下目前没有统一的入口,类似线上的搜索和推荐应用,无法触达到用户;2) 线下没有类似线上丰富的日志和行为数据,没有数据支撑比较难做到精准的个性化,无法优化效果。
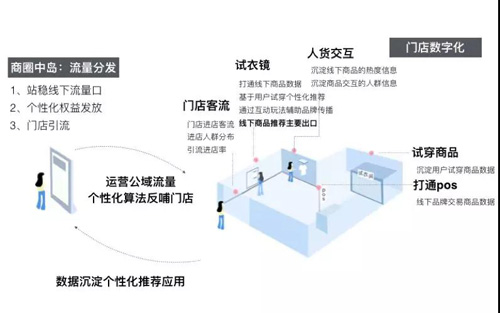
在线下场的流量分发的探索中,我们使用商场已有的互动屏幕、门店的互动屏幕作为流量分发的出口,同时,利用前文提到的客流数字化沉淀的数据来支撑线下场的个性化流量分发。
场外引流屏
场外引流屏的作用,是进行第一级的流量分发,首先需要通过不同的互动玩法,营销活动吸引用户,再通过屏幕对用户进行个性化的优惠券投放,引导用户进入不同的门店。
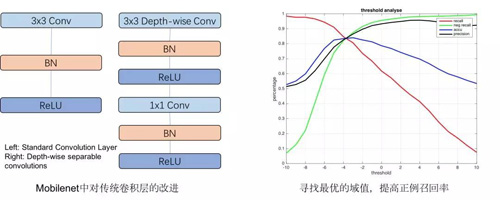
在传统商场中,用户刚进来商场,可能会随机地在这个楼层进行活动,当看到感兴趣的品牌完成进店的活动,或者用户会基于导览屏,大概了解商场楼层的品牌分布情况,再进行有一定针对性的浏览。而我们的引流屏的作用是将合适的优惠推荐给对应的人,从而引导用户进店,相当于在商场中岛进行整体的流量分发,将集中在中岛的用户往各个不同的方向进行引导。整体方案如下图所示:
整体方案依赖三部分的数据,分别是基于用户的图像特征产出的人群属性数据,以及各个店铺的进店人群分布数据和店铺的其他统计量的特征,基于用户当前的属性特征与店铺的人群分布进行匹配,可以得到初步的个性化的店铺推荐结果,此外,使用店铺本身的统计量特征作为辅助信息,在同等匹配条件下额外考虑各个店铺本身的热度,效率等维度特征,以及当前所提供的优惠券的力度信息,得到最终的优惠券的排序,并展示给用户。
场内试衣屏
场内试衣屏的作用是做第二层的流量分发,即用户进店后,需要推荐哪些商品展示给用户。在传统的门店中,用户进店后会在店内进行随机的浏览,对于感兴趣的衣服会找导购员提供试穿,试穿后导购员也会对顾客进行推荐。整个过程中存在一些问题,首先,用户对于商品的浏览和商品摆放的位置关系很大,橱窗的商品会更容易吸引用户注意,而部分较密集的衣架区,用户可能没有办法注意到部分货品;其次,试穿之后导购进行的推荐也会因人而异,和导购本身的素质关系也较大,有些经验丰富的导购员可以根据你个人的长相气质推荐更适合你的商品,而更多的导购员只能简单的基于当前的热销款来进行推荐,无法做到因人而异。
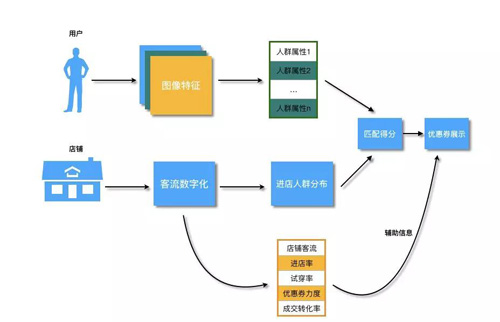
试衣屏推荐要解决的就是上述的两个问题,整体展现形式如下图:

在用户进行试穿时,会在镜子侧方显示商品的详情信息,包括目前商品是否有折扣等,同时会基于用户的试穿行为,推荐相关商品与搭配商品,给部分商品一次额外的展示机会,同时也能够基于用户的试穿以及用户当前的图像特征给出个性化的推荐结果,方便用户的选购,即使用户暂时没有这个消费习惯,镜子屏幕上的推荐结果也能对导购员进行一些辅助决策,能够帮助导购员给用户推荐更加个性化更加丰富的商品。
整体算法方案如下图所示:
考虑到隐私问题,在我们的应用中,我们不去尝试通过人脸关联到对应的id,仅在场内通过用户的行为和其他用户行为的相似性进行推荐。
工程实现
AI inference是GPU终端计算重要的一环,最开始探索的时候,AI inference采用串行模式:
通过观察测试数据,我们惊讶地发现,虽然程序已经处于视频流图片处理饱和的状态,但是6核心CPU的使用率才到150%,GPU的使用率才到30%,也就是说,超过一半的硬件资源处于闲置状态。 为了使得原本间歇性闲置的资源得到重新的利用,我们改造成了流水线模式,结构图如下所示:
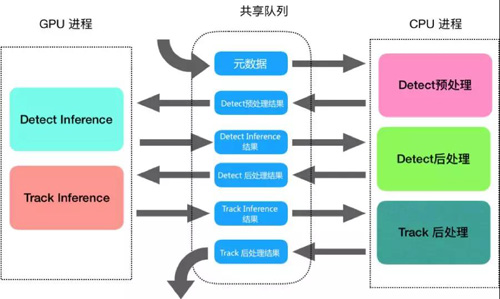
在多进程实现的流水线方案中,由于每个进程的数据都是相互独立的,一个进程产生或修改的数据对另一个进程而言它是无感知。如何提高进程间的数据传递是能否高效实现并发的关键点。 我们采用了基于mmap ctypes实现的共享内存,对比管道、socket多进程通讯机制,共享内存在多进程数据通讯方案中是非常高效和灵活,参考multiprocessing Value的解决方案,使用ctypes内置的基本数据结构来实现我们的数据模型,非常方便的进行内存切分并转换成可用的数据结构。
结合业务情况,我们的流水线工作模式会将各个阶段分割为子任务,我们还设计了图片共享队列,整个过程只需要写入一次图片数据,各个阶段只需要从这个共享队列读取图片即可,等所有流程都操作完之后再从图片队列删除这个图片数据,这样就能保证图片操作的正确性和高效性。通过测试发现,我们实现的共享内存队列在读取数据上比pipe方式快了300多倍。
业务效果
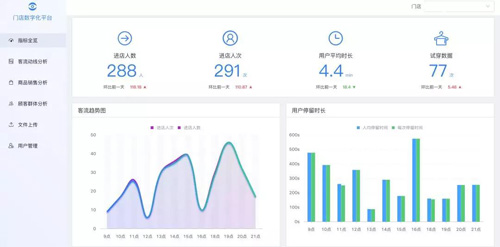
目前我们客流数字化的数据已经沉淀到相应的产品,以下是基础客流的示意图,品牌商可以看到门店每日的基础客流量以及分时段的客流情况,了解各个门店当前的经营状况。
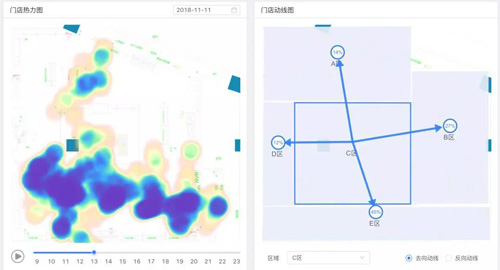
下图为区域热力图和区域动线图,区域热力图展示了门店在一天内各个小时各个区域的人流量密度情况,我们将各个不同摄像头的数据进行整合,最终映射到门店的平面CAD图上展示区域热力,让门店能够更直观的看到各个区域的热度,区域动线图展示了各个区域客流的去向和来源的占比,基于区域热力和动线数据,商家能够清晰的了解到门店各个区域的密度情况以及各个区域之间顾客的转移情况,目前合作的品牌商也会基于区域的数据对店内的陈列做适当的调整,甚至有门店基于动线的数据重新调整整个门店的区域分布情况。
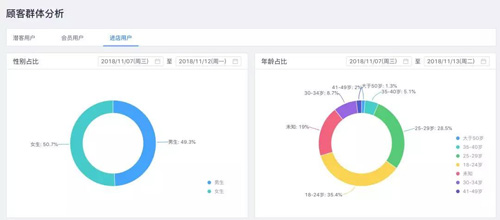
下图为门店进店客流的人群画像,展示了门店每天进店客流的性别和年龄的分布,商家会基于进店的人群画像数据与当前品牌的目标人群进行对比,并基于实际进店客流的分布调整门店陈列商品的品类结构以及不同类型商品的占比。
参考文献:
[1] Redmon J, Farhadi A. Yolov3: An incremental improvement[J]. arXiv preprint arXiv:1804.02767, 2018.
[2] Hinton G, Vinyals O, Dean J. Distilling knowledge in a neural network. In Deep Learning and Repre-sentation Learning Workshop, NIPS, 2014.
[3] Romero A, Ballas N, Kahou S E, et al. Fitnets: Hints for thin deep nets[J]. arXiv preprint arXiv:1412.6550, 2014.
[4] Chen G, Choi W, Yu X, et al. Learning efficient object detection models with knowledge distillation[C]//Advances in Neural Information Processing Systems. 2017: 742-751.
[5] Yifan Sun, Liang Zheng, Yi Yang, Qi Tian, Shengjin Wang. Beyond Part Models: Person Retrieval with Refined Part Pooling
[6] Wei Li, Xiatian Zhu, Shaogang Gong.Person Re-Identification by Deep Joint Learning of Multi-Loss Classification, IJCAI 2017
[7] Jianming Lv, Weihang Chen, Qing Li, Can Yang. Unsupervised Cross-dataset Person Re-identification by Transfer Learning of Spatial-Temporal Patterns, CVPR 2018
[8]Liang Zheng ; Liyue Shen ; Lu Tian ; Shengjin Wang ; Jingdong Wang ; Qi Tian. Scalable Person Re-identification: A Benchmark, ICCV 2015
[9] Guanshuo Wang, Yufeng Yuan, Xiong Chen, Jiwei Li, Xi Zhou.Learning Discriminative Features with Multiple Granularities for Person Re-Identification, MM 2018
[10] Liu S, Qi L, Qin H, et al. Path aggregation network for instance segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 8759-8768.
[11]Tianci Liu ; Lei Yang ; Xiang-Yang Li ; Huaiyi Huang ; Yunhao Liu,TagBooth: Deep shopping data acquisition powered by RFID tags. INFOCOM 2015
[12]https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet_v1.md
【本文为51CTO专栏作者“阿里巴巴官方技术”原创稿件,转载请联系原作者】