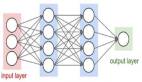
一:VGG介绍与模型结构
VGG全称是Visual Geometry Group属于牛津大学科学工程系,其发布了一些列以VGG开头的卷积网络模型,可以应用在人脸识别、图像分类等方面,分别从VGG16~VGG19。VGG研究卷积网络深度的初衷是想搞清楚卷积网络深度是如何影响大规模图像分类与识别的精度和准确率的,最初是VGG-16号称非常深的卷积网络全称为(GG-Very-Deep-16 CNN),VGG在加深网络层数同时为了避免参数过多,在所有层都采用3x3的小卷积核,卷积层步长被设置为1。VGG的输入被设置为224x244大小的RGB图像,在训练集图像上对所有图像计算RGB均值,然后把图像作为输入传入VGG卷积网络,使用3x3或者1x1的filter,卷积步长被固定1。VGG全连接层有3层,根据卷积层+全连接层总数目的不同可以从VGG11 ~ VGG19,最少的VGG11有8个卷积层与3个全连接层,最多的VGG19有16个卷积层+3个全连接层,此外VGG网络并不是在每个卷积层后面跟上一个池化层,还是总数5个池化层,分布在不同的卷积层之下,下图是VGG11 ~GVV19的结构图:

考虑到整个网络的精简结构显示,ReLU激活函数并没有被显示在上述结构中。上述结构中一些说明:
- conv表示卷积层
- FC表示全连接层
- conv3表示卷积层使用3x3 filters
- conv3-64表示 深度64
- maxpool表示***池化
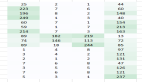
上述VGG11 ~ VGG19参数总数列表如下:

在实际处理中还可以对***个全连接层改为7x7的卷积网络,后面两个全连接层改为1x1的卷积网络,这个整个VGG就变成一个全卷积网络FCN。在VGG网络之前,卷积神经网络CNN很少有突破10层的,VGG在加深CNN网络深度方面首先做出了贡献,但是VGG也有自身的局限性,不能***制的加深网络,在网络加深到一定层数之后就会出现训练效果褪化、梯度消逝或者梯度爆炸等问题,总的来说VGG在刚提出的时候也是风靡一时,在ImageNet竞赛数据集上都取得了不错的效果
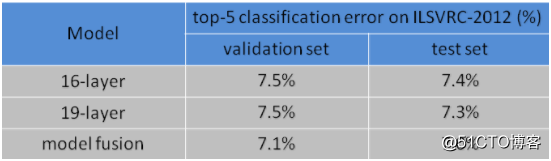
在其他类似数据上同样表现不俗:

二:预训练模型使用(Caffe)
VGG本身提供了预训练模型供大家可以自由使用,预训练的VGG-16模型与VGG-19模型下载地址可以在这里发现:
http://www.robots.ox.ac.uk/~vgg/research/very_deep/
下载VGG-16模型之后使用OpenCV DNN模块相关API,就可以实现一个图像分类器,支持1000种图像分类,基于ImageNet 2014-ILSVRC数据集训练。原图:

VGG-16预测分类结果:

稍微有点尴尬的是,OpenCL初始化内存不够了,只能说我的机器不给力:
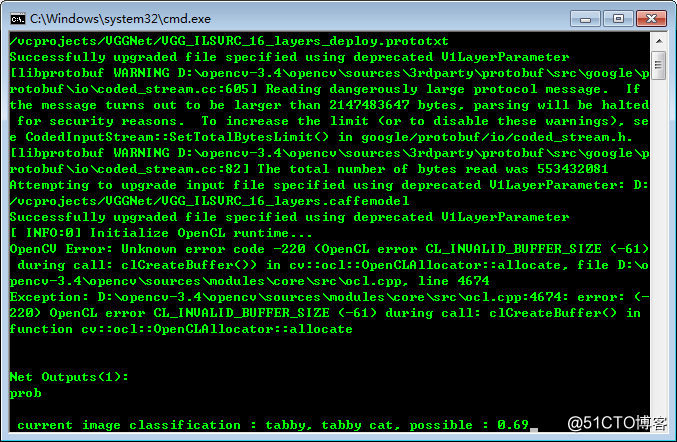
演示网络加载与图像分类的OpenCV程序代码如下:
Net net = readNetFromCaffe(model_txt_file, model_bin_file);
if (net.empty()) {
printf("read caffe model data failure...\n");
return -1;
}
Mat inputBlob = blobFromImage(src, 1.0, Size(w, h), Scalar(104, 117, 123));
Mat prob;
for (int i = 0; i < 10; i++) {
net.setInput(inputBlob, "data");
prob = net.forward("prob");
}
Mat probMat = prob.reshape(1, 1);
Point classNumber;
double classProb;
minMaxLoc(probMat, NULL, &classProb, NULL, &classNumber);
int classidx = classNumber.x;
printf("\n current image classification : %s, possible : %.2f", labels.at(classidx).c_str(), classProb);
putText(src, labels.at(classidx), Point(20, 20), FONT_HERSHEY_SIMPLEX, 1.0, Scalar(0, 0, 255), 2, 8);
imshow("Image Classification", src);
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
学习OpenCV 深度学习视频教程 点击下面: