人工智能时代的交互特色用一个词来概括就是“对话”,用人类最自然的交互方式,或者是语音或者是文字,给机器发送指令,与机器进行交互。当然,人机对话系统早在传统计算机时代就已经出现了,只是在人工智能时代,特别是由于各种机器学习技术尤其是深度学习技术的出现,使我们的系统实用性取得了质的飞跃。
对话系统种类繁多,划分方式多种多样。可根据用途分为任务型、问答型、闲聊型对话系统;也可根据场景分为封闭域、开放域对话系统;还可根据使用方法分为检索式、生成式对话系统。UINT平台能够帮助大家方便地构建任务型多轮对话系统。我们重点看任务型多轮对话系统。
任务型人机对话系统
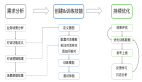
在对话过程中,机器人需执行的操作分为口语理解、对话管理、执行命令、语言生成四个过程。如下图所示对话系统的基本操作流程:

首先,对话系统需理解用户的自然语言请求,根据用户给出的查询输入先后经过口语理解、对话管理,然后决定进行语言生成还是指令执行,***给出系统答复。其中,核心模块为口语理解和对话管理。
口语理解
口语理解的功能为理解用户请求所包含的语义信息,用于信息查询或指令执行。其任务难点为自然语言的歧义性,表达方法的多样性及叙述风格的口语化。那么该如何攻破口语理解的任务难点呢?
UNIT平台提供两种经典模式解决:基于语义解析的口语理解模式,基于语义匹配的口语理解模式。
基于语义解析的口语理解模式,是将用户请求解析为所包含语义信息的结构化表达。其中,最典型的结构化表达是意图(描述用户的核心诉求)+ 词槽(描述意图的关键信息)的模式。常用方法有基于知识规则的方法,基于机器学习的方法,以及基于融合策略的方法。
基于语义匹配的口语理解模式,不需要解析出具体的语义格式化信息,而是需要寻找与其具有***语义匹配程度的问答对。
对话管理
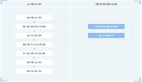
对话管理的功能为基于对话状态实施对话策略,从而实现多轮对话逻辑。其任务难点为状态计算的不确定性及不确定环境下的策略选择。相应的,对话管理存在两大核心任务:对话状态跟踪、对话策略选择。如下图为对话管理在整个对话流程中的位置,及状态位置和对话管理之间相互配合的关系。

对话状态跟踪,即根据对话历史计算当前对话状态,管理并更新对话历史。其常用方法为:基于人工规则的方法,基于机器学习的方法。通过建立映射,输入会话历史,然后输出当前对话状态。
对话策略选择,即根据当前对话状态,选择接下来最恰当的操作。其常用方法为:基于人工规则的方法,基于机器学习的方法,以及基于强化学习的方法。同样是通过建模映射的过程,输入当前对话状态,输出系统回复和指令执行。
对话系统如何搭建
简单介绍一下系统搭建的流程,以及每个流程当中开发者需要做什么,以及UINT平台为大家提供了什么。搭建流程如下:
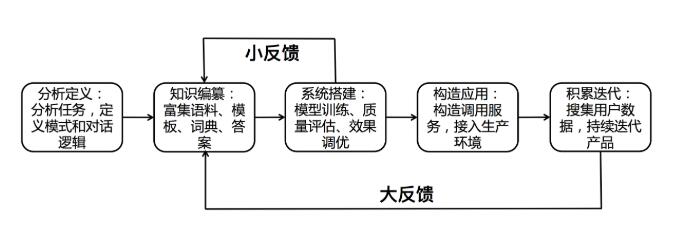
1)首先定义对话系统。就是说这个对话系统包含哪些意图,这个意图的关键信息是什么。
2)富集数据资源。就是收集、标注、扩充数据资源,包括需要哪些词典,标注哪些规则,需要写多少模板,需要标注多少样本。
3)配置对话逻辑。这个过程可以很方便的用UINT进行搭建,只要把这个对话系统按照UINT提供的方式配置到UINT平台中,把富集的数据资源输入到UINT中,点几个按钮就可以进行系统的搭建训练了。
4)训练模型,效果优化。可以在UNIT平台进行对话效果的调优。之后可以不断的重复一个小的循环过程。上线之后,大量的用户进来使用对话机器人,贡献了更多数据的样本,拿到这些样本之后,根据这些样本所产生的错误等等情况进行分析,再一次富集我们的资源对系统进行改进,使得效果不断变好。
在这个搭建的过程中,UNIT平台提供了很多能力,为开发者降低了开发成本。
- 预置技能:分析用户需求,定义对话系统阶段,UNIT平台直接推出多个场景的预置技能,也有富含资源的技能,开发者可以一键获取,不需再进行富集数据和模型训练的工作。
- 系统词槽:UNIT平台预置的词槽,包括人名、地名、时间、地点等22个大类的词槽词典值,开发者可以直接勾选复用,不需富集人名表、地名表和时间等等这些信息。
- 模板配置:UNIT提供了一套科学的对话理解模板的编撰机制,通过这种对话模板,可以快速实现对话的泛化效果。
- 推荐样本:UNIT平台提供了大量的推荐样本,减少开发者样本富集的工作,根据开发者提供的样本,能够推荐出一些相似的、可以复用的样本出来。
- 日志分析:UINT提供了数据回流的机制,数据存储的机制,数据服务加工的机制等,以及日志分析工具,帮助开发者优化对话效果。
系统评估
评估方法分为两大类:
1. 对单个系统的精度给出量化的指标数据,用于单个系统的精度评估
由于口语理解精度直接影响对话管理运行,进而影响对话系统效果,因此可以通过评估口语理解来评估对话系统。其中有三个指标:准确率(Precision),召回率(Recall),F 值(F-measure)
准确率 = 预测结果中正确的数量 / 预测结果中总的数量
召回率 = 预测结果中正确的数量 / 测试集中应该被识别的数量
2. 对两个系统的精度对比给出量化的指标数据,用于系统迭代时给出精度对比。
针对系统迭代需求,比较基线系统 X 和对比系统 Y 的优势。其中两个系统的定量对比涉及的指标:
- Diff 面:同一条 query 解析结果不一致的情况在抽样集合中的占比
- G(变好):针对同一条 query,Y 的结果比 X 好
- S(相同):针对同一条 query,Y 的结果与 X 差不多
- B(变差):针对同一条 query,Y 的结果比 X 差
如果 Y 要替换 X,至少 G>B;同时如果 Diff 面过大,则还需要考虑用户体验的波动。