一、什么是Table API
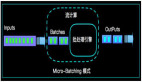
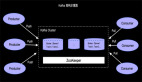
在《Apache Flink 漫谈系列(08) - SQL概览》中我们概要的向大家介绍了什么是好SQL,SQL和Table API是Apache Flink中的同一层次的API抽象,如下图所示:
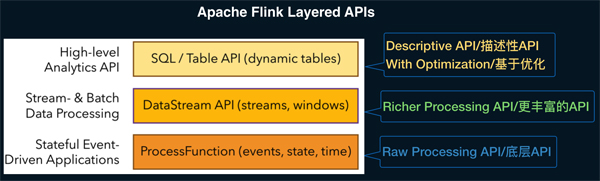
Apache Flink 针对不同的用户场景提供了三层用户API,最下层ProcessFunction API可以对State,Timer等复杂机制进行有效的控制,但用户使用的便捷性很弱,也就是说即使很简单统计逻辑,也要较多的代码开发。第二层DataStream API对窗口,聚合等算子进行了封装,用户的便捷性有所增强。最上层是SQL/Table API,Table API是Apache Flink中的声明式,可被查询优化器优化的高级分析API。
二、Table API的特点
Table API和SQL都是Apache Flink中最高层的分析API,SQL所具备的特点Table API也都具有,如下:
- 声明式 - 用户只关心做什么,不用关心怎么做;
- 高性能 - 支持查询优化,可以获取最好的执行性能;
- 流批统一 - 相同的统计逻辑,既可以流模式运行,也可以批模式运行;
- 标准稳定 - 语义遵循SQL标准,语法语义明确,不易变动。
当然除了SQL的特性,因为Table API是在Flink中专门设计的,所以Table API还具有自身的特点:
- 表达方式的扩展性 - 在Flink中可以为Table API开发很多便捷性功能,如:Row.flatten(), map/flatMap 等
- 功能的扩展性 - 在Flink中可以为Table API扩展更多的功能,如:Iteration,flatAggregate 等新功能
- 编译检查 - Table API支持java和scala语言开发,支持IDE中进行编译检查。
说明:上面说的map/flatMap/flatAggregate都是Apache Flink 社区 FLIP-29 中规划的新功能。
三、HelloWorld
在介绍Table API所有算子之前我们先编写一个简单的HelloWorld来直观了解如何进行Table API的开发。
1. Maven 依赖
在pom文件中增加如下配置,本篇以flink-1.7.0功能为准进行后续介绍。
- <properties>
- <table.version>1.7.0</table.version>
- </properties>
- <dependencies>
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-table_2.11</artifactId>
- <version>${table.version}</version>
- </dependency>
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-scala_2.11</artifactId>
- <version>${table.version}</version>
- </dependency>
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-streaming-scala_2.11</artifactId>
- <version>${table.version}</version>
- </dependency>
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-streaming-java_2.11</artifactId>
- <version>${table.version}</version>
- </dependency>
- </dependencies>
2. 程序结构
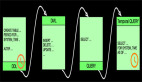
在编写第一Flink Table API job之前我们先简单了解一下Flink Table API job的结构,如下图所示:
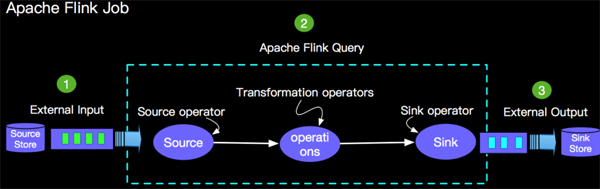
- 外部数据源,比如Kafka, Rabbitmq, CSV 等等;
- 查询计算逻辑,比如最简单的数据导入select,双流Join,Window Aggregate 等;
- 外部结果存储,比如Kafka,Cassandra,CSV等。
说明:1和3 在Apache Flink中统称为Connector。
3. 主程序
我们以一个统计单词数量的业务场景,编写第一个HelloWorld程序。
根据上面Flink job基本结构介绍,要Table API完成WordCount的计算需求,我们需要完成三部分代码:
- TableSoruce Code - 用于创建数据源的代码
- Table API Query - 用于进行word count统计的Table API 查询逻辑
- TableSink Code - 用于保存word count计算结果的结果表代码
(1) 运行模式选择
一个job我们要选择是Stream方式运行还是Batch模式运行,所以任何统计job的第一步是进行运行模式选择,如下我们选择Stream方式运行。
- // Stream运行环境
- val env = StreamExecutionEnvironment.getExecutionEnvironment
- val tEnv = TableEnvironment.getTableEnvironment(env)
(2) 构建测试Source
我们用最简单的构建Source方式进行本次测试,代码如下:
- // 测试数据
- val data = Seq("Flink", "Bob", "Bob", "something", "Hello", "Flink", "Bob")
- // 最简单的获取Source方式
- val source = env.fromCollection(data).toTable(tEnv, 'word)
(3) WordCount 统计逻辑
WordCount核心统计逻辑就是按照单词分组,然后计算每个单词的数量,统计逻辑如下:
- // 单词统计核心逻辑
- val result = source
- .groupBy('word) // 单词分组
- .select('word, 'word.count) // 单词统计
(4) 定义Sink
将WordCount的统计结果写入Sink中,代码如下:
- // 自定义Sink
- val sink = new RetractSink // 自定义Sink(下面有完整代码)
- // 计算结果写入sink
- result.toRetractStream[(String, Long)].addSink(sink)
(5) 完整的HelloWord代码
为了方便大家运行WordCount查询统计,将完整的代码分享大家(基于flink-1.7.0),如下:
- import org.apache.flink.api.scala._
- import org.apache.flink.configuration.Configuration
- import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
- import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
- import org.apache.flink.table.api.TableEnvironment
- import org.apache.flink.table.api.scala._
- import scala.collection.mutable
- object HelloWord {
- def main(args: Array[String]): Unit = {
- // 测试数据
- val data = Seq("Flink", "Bob", "Bob", "something", "Hello", "Flink", "Bob")
- // Stream运行环境
- val env = StreamExecutionEnvironment.getExecutionEnvironment
- val tEnv = TableEnvironment.getTableEnvironment(env)
- // 最简单的获取Source方式
- val source = env.fromCollection(data).toTable(tEnv, 'word)
- // 单词统计核心逻辑
- val result = source
- .groupBy('word) // 单词分组
- .select('word, 'word.count) // 单词统计
- // 自定义Sink
- val sink = new RetractSink
- // 计算结果写入sink
- result.toRetractStream[(String, Long)].addSink(sink)
- env.execute
- }
- }
- class RetractSink extends RichSinkFunction[(Boolean, (String, Long))] {
- private var resultSet: mutable.Set[(String, Long)] = _
- override def open(parameters: Configuration): Unit = {
- // 初始化内存存储结构
- resultSet = new mutable.HashSet[(String, Long)]
- }
- override def invoke(v: (Boolean, (String, Long)), context: SinkFunction.Context[_]): Unit = {
- if (v._1) {
- // 计算数据
- resultSet.add(v._2)
- }
- else {
- // 撤回数据
- resultSet.remove(v._2)
- }
- }
- override def close(): Unit = {
- // 打印写入sink的结果数据
- resultSet.foreach(println)
- }
- }
运行结果如下:
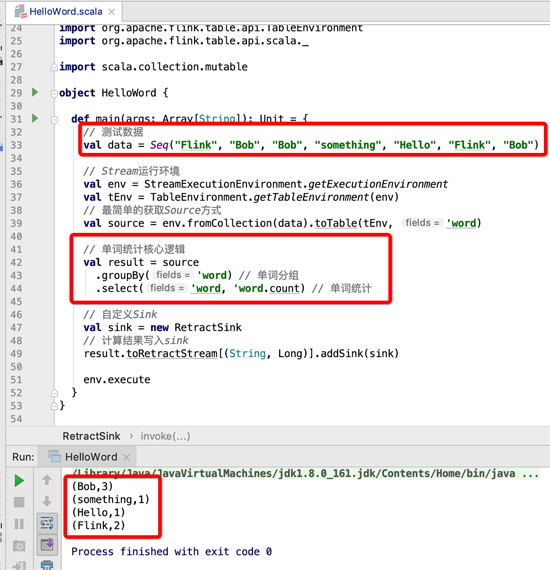
虽然上面用了较长的纸墨介绍简单的WordCount统计逻辑,但source和sink部分都是可以在学习后面算子中被复用的。本例核心的统计逻辑只有一行代码:
- source.groupBy('word).select('word, 'word.count)
所以Table API开发技术任务非常的简洁高效。
四、Table API 算子
虽然Table API与SQL的算子语义一致,但在表达方式上面SQL以文本的方式展现,Table API是以java或者scala语言的方式进行开发。为了大家方便阅读,即便是在《Apache Flink 漫谈系列(08) - SQL概览》中介绍过的算子,在这里也会再次进行介绍,当然对于Table API和SQL不同的地方会进行详尽介绍。
1. 示例数据及测试类
(1) 测试数据
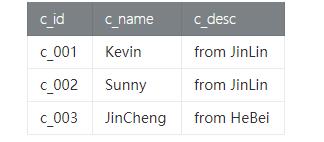
- customer_tab 表 - 客户表保存客户id,客户姓名和客户描述信息。字段及测试数据如下:
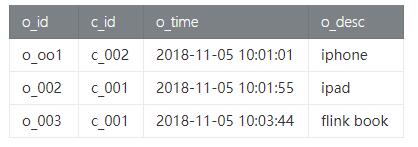
- order_tab 表 - 订单表保存客户购买的订单信息,包括订单id,订单时间和订单描述信息。 字段节测试数据如下:
- Item_tab商品表, 携带商品id,商品类型,出售时间,价格等信息,具体如下:
- PageAccess_tab页面访问表,包含用户ID,访问时间,用户所在地域信息,具体数据如下:
- PageAccessCount_tab页面访问表,访问量,访问时间,用户所在地域信息,具体数据如下:
- PageAccessSession_tab页面访问表,访问量,访问时间,用户所在地域信息,具体数据如下:
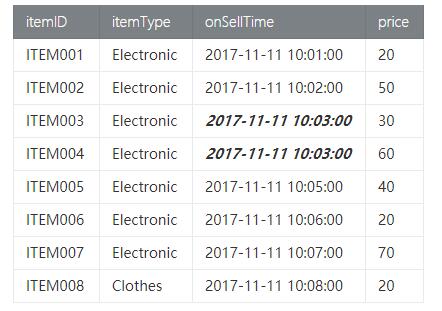
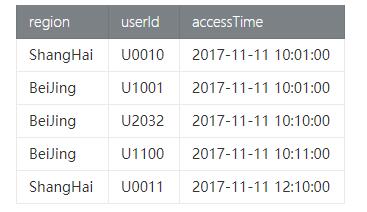
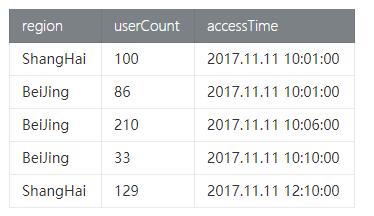
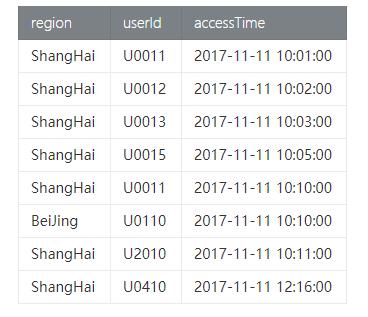
(2) 测试类
我们创建一个TableAPIOverviewITCase.scala 用于接下来介绍Flink Table API算子的功能体验。代码如下:
- import org.apache.flink.api.scala._
- import org.apache.flink.runtime.state.StateBackend
- import org.apache.flink.runtime.state.memory.MemoryStateBackend
- import org.apache.flink.streaming.api.TimeCharacteristic
- import org.apache.flink.streaming.api.functions.sink.RichSinkFunction
- import org.apache.flink.streaming.api.functions.source.SourceFunction
- import org.apache.flink.streaming.api.functions.source.SourceFunction.SourceContext
- import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
- import org.apache.flink.streaming.api.watermark.Watermark
- import org.apache.flink.table.api.{Table, TableEnvironment}
- import org.apache.flink.table.api.scala._
- import org.apache.flink.types.Row
- import org.junit.rules.TemporaryFolder
- import org.junit.{Rule, Test}
- import scala.collection.mutable
- import scala.collection.mutable.ArrayBuffer
- class Table APIOverviewITCase {
- // 客户表数据
- val customer_data = new mutable.MutableList[(String, String, String)]
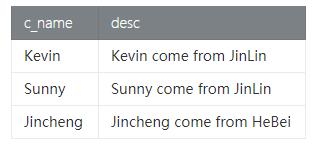
- customer_data.+=(("c_001", "Kevin", "from JinLin"))
- customer_data.+=(("c_002", "Sunny", "from JinLin"))
- customer_data.+=(("c_003", "JinCheng", "from HeBei"))
- // 订单表数据
- val order_data = new mutable.MutableList[(String, String, String, String)]
- order_data.+=(("o_001", "c_002", "2018-11-05 10:01:01", "iphone"))
- order_data.+=(("o_002", "c_001", "2018-11-05 10:01:55", "ipad"))
- order_data.+=(("o_003", "c_001", "2018-11-05 10:03:44", "flink book"))
- // 商品销售表数据
- val item_data = Seq(
- Left((1510365660000L, (1510365660000L, 20, "ITEM001", "Electronic"))),
- Right((1510365660000L)),
- Left((1510365720000L, (1510365720000L, 50, "ITEM002", "Electronic"))),
- Right((1510365720000L)),
- Left((1510365780000L, (1510365780000L, 30, "ITEM003", "Electronic"))),
- Left((1510365780000L, (1510365780000L, 60, "ITEM004", "Electronic"))),
- Right((1510365780000L)),
- Left((1510365900000L, (1510365900000L, 40, "ITEM005", "Electronic"))),
- Right((1510365900000L)),
- Left((1510365960000L, (1510365960000L, 20, "ITEM006", "Electronic"))),
- Right((1510365960000L)),
- Left((1510366020000L, (1510366020000L, 70, "ITEM007", "Electronic"))),
- Right((1510366020000L)),
- Left((1510366080000L, (1510366080000L, 20, "ITEM008", "Clothes"))),
- Right((151036608000L)))
- // 页面访问表数据
- val pageAccess_data = Seq(
- Left((1510365660000L, (1510365660000L, "ShangHai", "U0010"))),
- Right((1510365660000L)),
- Left((1510365660000L, (1510365660000L, "BeiJing", "U1001"))),
- Right((1510365660000L)),
- Left((1510366200000L, (1510366200000L, "BeiJing", "U2032"))),
- Right((1510366200000L)),
- Left((1510366260000L, (1510366260000L, "BeiJing", "U1100"))),
- Right((1510366260000L)),
- Left((1510373400000L, (1510373400000L, "ShangHai", "U0011"))),
- Right((1510373400000L)))
- // 页面访问量表数据2
- val pageAccessCount_data = Seq(
- Left((1510365660000L, (1510365660000L, "ShangHai", 100))),
- Right((1510365660000L)),
- Left((1510365660000L, (1510365660000L, "BeiJing", 86))),
- Right((1510365660000L)),
- Left((1510365960000L, (1510365960000L, "BeiJing", 210))),
- Right((1510366200000L)),
- Left((1510366200000L, (1510366200000L, "BeiJing", 33))),
- Right((1510366200000L)),
- Left((1510373400000L, (1510373400000L, "ShangHai", 129))),
- Right((1510373400000L)))
- // 页面访问表数据3
- val pageAccessSession_data = Seq(
- Left((1510365660000L, (1510365660000L, "ShangHai", "U0011"))),
- Right((1510365660000L)),
- Left((1510365720000L, (1510365720000L, "ShangHai", "U0012"))),
- Right((1510365720000L)),
- Left((1510365720000L, (1510365720000L, "ShangHai", "U0013"))),
- Right((1510365720000L)),
- Left((1510365900000L, (1510365900000L, "ShangHai", "U0015"))),
- Right((1510365900000L)),
- Left((1510366200000L, (1510366200000L, "ShangHai", "U0011"))),
- Right((1510366200000L)),
- Left((1510366200000L, (1510366200000L, "BeiJing", "U2010"))),
- Right((1510366200000L)),
- Left((1510366260000L, (1510366260000L, "ShangHai", "U0011"))),
- Right((1510366260000L)),
- Left((1510373760000L, (1510373760000L, "ShangHai", "U0410"))),
- Right((1510373760000L)))
- val _tempFolder = new TemporaryFolder
- // Streaming 环境
- val env = StreamExecutionEnvironment.getExecutionEnvironment
- val tEnv = TableEnvironment.getTableEnvironment(env)
- env.setParallelism(1)
- env.setStateBackend(getStateBackend)
- def getProcTimeTables(): (Table, Table) = {
- // 将order_tab, customer_tab 注册到catalog
- val customer = env.fromCollection(customer_data).toTable(tEnv).as('c_id, 'c_name, 'c_desc)
- val order = env.fromCollection(order_data).toTable(tEnv).as('o_id, 'c_id, 'o_time, 'o_desc)
- (customer, order)
- }
- def getEventTimeTables(): (Table, Table, Table, Table) = {
- env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
- // 将item_tab, pageAccess_tab 注册到catalog
- val item =
- env.addSource(new EventTimeSourceFunction[(Long, Int, String, String)](item_data))
- .toTable(tEnv, 'onSellTime, 'price, 'itemID, 'itemType, 'rowtime.rowtime)
- val pageAccess =
- env.addSource(new EventTimeSourceFunction[(Long, String, String)](pageAccess_data))
- .toTable(tEnv, 'accessTime, 'region, 'userId, 'rowtime.rowtime)
- val pageAccessCount =
- env.addSource(new EventTimeSourceFunction[(Long, String, Int)](pageAccessCount_data))
- .toTable(tEnv, 'accessTime, 'region, 'accessCount, 'rowtime.rowtime)
- val pageAccessSession =
- env.addSource(new EventTimeSourceFunction[(Long, String, String)](pageAccessSession_data))
- .toTable(tEnv, 'accessTime, 'region, 'userId, 'rowtime.rowtime)
- (item, pageAccess, pageAccessCount, pageAccessSession)
- }
- @Rule
- def tempFolder: TemporaryFolder = _tempFolder
- def getStateBackend: StateBackend = {
- new MemoryStateBackend()
- }
- def procTimePrint(result: Table): Unit = {
- val sink = new RetractingSink
- result.toRetractStream[Row].addSink(sink)
- env.execute()
- }
- def rowTimePrint(result: Table): Unit = {
- val sink = new RetractingSink
- result.toRetractStream[Row].addSink(sink)
- env.execute()
- }
- @Test
- def testProc(): Unit = {
- val (customer, order) = getProcTimeTables()
- val result = ...// 测试的查询逻辑
- procTimePrint(result)
- }
- @Test
- def testEvent(): Unit = {
- val (item, pageAccess, pageAccessCount, pageAccessSession) = getEventTimeTables()
- val result = ...// 测试的查询逻辑
- procTimePrint(result)
- }
- }
- // 自定义Sink
- final class RetractingSink extends RichSinkFunction[(Boolean, Row)] {
- var retractedResults: ArrayBuffer[String] = null
- override def open(parameters: Configuration): Unit = {
- super.open(parameters)
- retractedResults = mutable.ArrayBuffer.empty[String]
- }
- def invoke(v: (Boolean, Row)) {
- retractedResults.synchronized {
- val vvalue = v._2.toString
- if (v._1) {
- retractedResults += value
- } else {
- val idx = retractedResults.indexOf(value)
- if (idx >= 0) {
- retractedResults.remove(idx)
- } else {
- throw new RuntimeException("Tried to retract a value that wasn't added first. " +
- "This is probably an incorrectly implemented test. " +
- "Try to set the parallelism of the sink to 1.")
- }
- }
- }
- }
- override def close(): Unit = {
- super.close()
- retractedResults.sorted.foreach(println(_))
- }
- }
- // Water mark 生成器
- class EventTimeSourceFunction[T](
- dataWithTimestampList: Seq[Either[(Long, T), Long]]) extends SourceFunction[T] {
- override def run(ctx: SourceContext[T]): Unit = {
- dataWithTimestampList.foreach {
- case Left(t) => ctx.collectWithTimestamp(t._2, t._1)
- case Right(w) => ctx.emitWatermark(new Watermark(w))
- }
- }
- override def cancel(): Unit = ???
- }
2. SELECT
SELECT 用于从数据集/流中选择数据,语义是关系代数中的投影(Projection),对关系进行垂直分割,消去或增加某些列, 如下图所示:
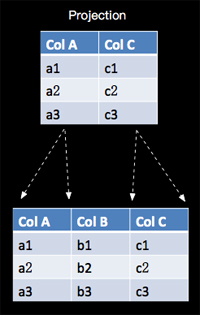
(1) Table API 示例
从customer_tab选择用户姓名,并用内置的CONCAT函数拼接客户信息,如下:
- val result = customer
- .select('c_name, concat_ws('c_name, " come ", 'c_desc))
(2) Result
(3) 特别说明
大家看到在 SELECT 不仅可以使用普通的字段选择,还可以使用ScalarFunction,当然也包括User-Defined Function,同时还可以进行字段的alias设置。其实SELECT可以结合聚合,在GROUPBY部分会进行介绍,一个比较特殊的使用场景是去重的场景,示例如下:
- Table API示例
在订单表查询所有的客户id,消除重复客户id, 如下:
- val result = order
- .groupBy('c_id)
- .select('c_id)
- Result
3. WHERE
WHERE 用于从数据集/流中过滤数据,与SELECT一起使用,语义是关系代数的Selection,根据某些条件对关系做水平分割,即选择符合条件的记录,如下所示:
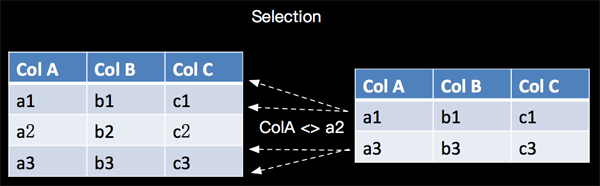
(1) Table API 示例
在customer_tab查询客户id为c_001和c_003的客户信息,如下:
- val result = customer
- .where("c_|| c_")
- .select( 'c_id, 'c_name, 'c_desc)
(2) Result
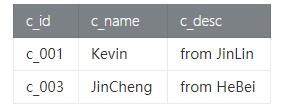
(3) 特别说明
我们发现WHERE是对满足一定条件的数据进行过滤,WHERE支持=, <, >, <>, >=, <=以及&&, ||等表达式的组合,最终满足过滤条件的数据会被选择出来。 SQL中的IN和NOT IN在Table API里面用intersect 和 minus描述(flink-1.7.0版本)。
- Intersect 示例
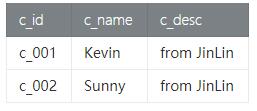
Intersect只在Batch模式下进行支持,Stream模式下我们可以利用双流JOIN来实现,如:在customer_tab查询已经下过订单的客户信息,如下:
- // 计算客户id,并去重
- val distinct_cids = order
- .groupBy('c_id) // 去重
- .select('c_id as 'o_c_id)
- val result = customer
- .join(distinct_cids, 'c_id === 'o_c_id)
- .select('c_id, 'c_name, 'c_desc)
- Result
- Minus 示例
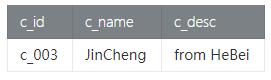
Minus只在Batch模式下进行支持,Stream模式下我们可以利用双流JOIN来实现,如:在customer_tab查询没有下过订单的客户信息,如下:
- // 查询下过订单的客户id,并去重
- val distinct_cids = order
- .groupBy('c_id)
- .select('c_id as 'o_c_id)
- // 查询没有下过订单的客户信息
- val result = customer
- .leftOuterJoin(distinct_cids, 'c_id === 'o_c_id)
- .where('o_c_id isNull)
- .select('c_id, 'c_name, 'c_desc)
说明上面实现逻辑比较复杂,我们后续考虑如何在流上支持更简洁的方式。
- Result
- Intersect/Minus与关系代数
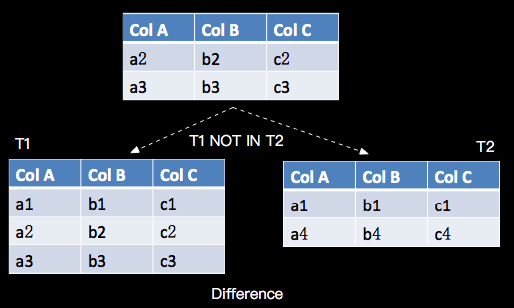
如上介绍Intersect是关系代数中的Intersection, Minus是关系代数的Difference, 如下图示意:
a. Intersect(Intersection):
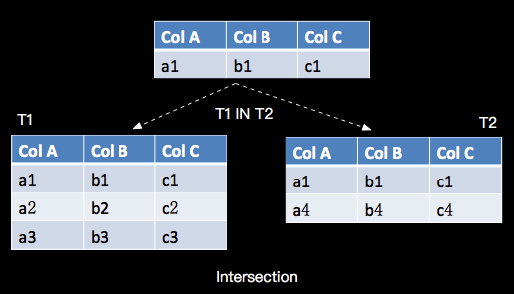
b. Minus(Difference):
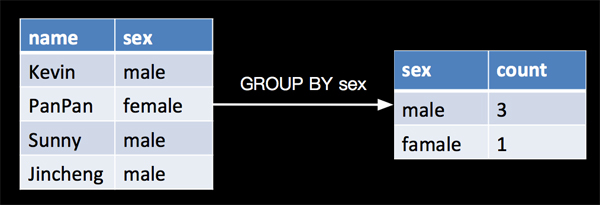
4. GROUP BY
GROUP BY 是对数据进行分组的操作,比如我需要分别计算一下一个学生表里面女生和男生的人数分别是多少,如下:
(1) Table API 示例
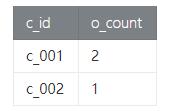
将order_tab信息按c_id分组统计订单数量,简单示例如下:
- val result = order
- .groupBy('c_id)
- .select('c_id, 'o_id.count)
(2) Result
(3) 特别说明
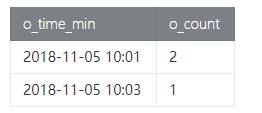
在实际的业务场景中,GROUP BY除了按业务字段进行分组外,很多时候用户也可以用时间来进行分组(相当于划分窗口),比如统计每分钟的订单数量:
- Table API 示例
按时间进行分组,查询每分钟的订单数量,如下:
- ```
- val result = order
- .select('o_id, 'c_id, 'o_time.substring(1, 16) as 'o_time_min)
- .groupBy('o_time_min)
- .select('o_time_min, 'o_id.count)
- ```
- Result
说明:如果我们时间字段是timestamp类型,建议使用内置的 DATE_FORMAT 函数。
5. UNION ALL
UNION ALL 将两个表合并起来,要求两个表的字段完全一致,包括字段类型、字段顺序,语义对应关系代数的Union,只是关系代数是Set集合操作,会有去重复操作,UNION ALL 不进行去重,如下所示:
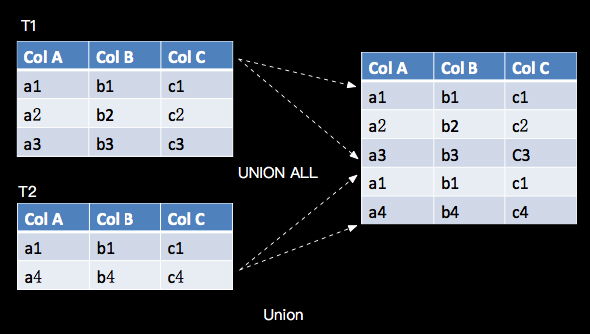
(1) Table API 示例
我们简单的将customer_tab查询2次,将查询结果合并起来,如下:
- val result = customer.unionAll(customer)
(2) Result
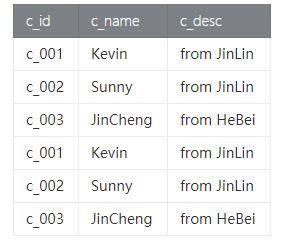
(3) 特别说明
UNION ALL 对结果数据不进行去重,如果想对结果数据进行去重,传统数据库需要进行UNION操作。
6. UNION
UNION 将两个流给合并起来,要求两个流的字段完全一致,包括字段类型、字段顺序,并其UNION 不同于UNION ALL,UNION会对结果数据去重,与关系代数的Union语义一致,如下:
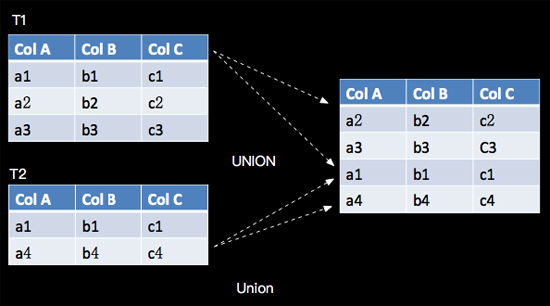
(1) Table API 示例
我们简单的将customer_tab查询2次,将查询结果合并起来,如下:
- val result = customer.union(customer)
我们发现完全一样的表数据进行 UNION之后,数据是被去重的,UNION之后的数据并没有增加。
(2) Result
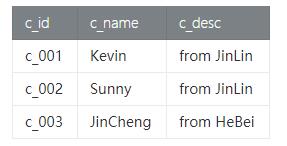
(3) 特别说明
UNION 对结果数据进行去重,在实际的实现过程需要对数据进行排序操作,所以非必要去重情况请使用UNION ALL操作。
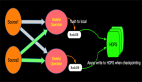
7. JOIN
JOIN 用于把来自两个表的行联合起来形成一个宽表,Apache Flink支持的JOIN类型:
- JOIN - INNER JOIN
- LEFT JOIN - LEFT OUTER JOIN
- RIGHT JOIN - RIGHT OUTER JOIN
- FULL JOIN - FULL OUTER JOIN
JOIN与关系代数的Join语义相同,具体如下:
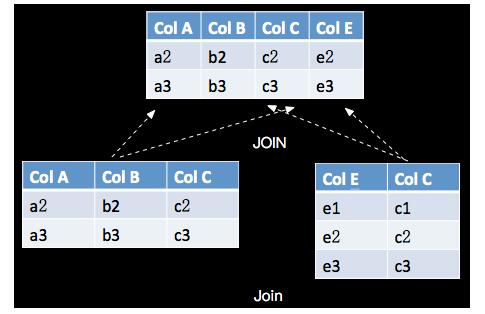
(1) Table API 示例 (JOIN)
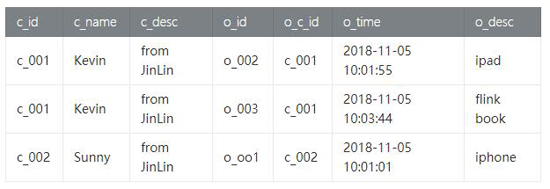
INNER JOIN只选择满足ON条件的记录,我们查询customer_tab 和 order_tab表,将有订单的客户和订单信息选择出来,如下:
- val result = customer
- .join(order.select('o_id, 'c_id as 'o_c_id, 'o_time, 'o_desc), 'c_id === 'o_c_id)
(2)Result:
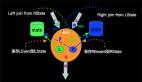
(3) Table API 示例 (LEFT JOIN)
LEFT JOIN与INNER JOIN的区别是当右表没有与左边相JOIN的数据时候,右边对应的字段补NULL输出,语义如下:
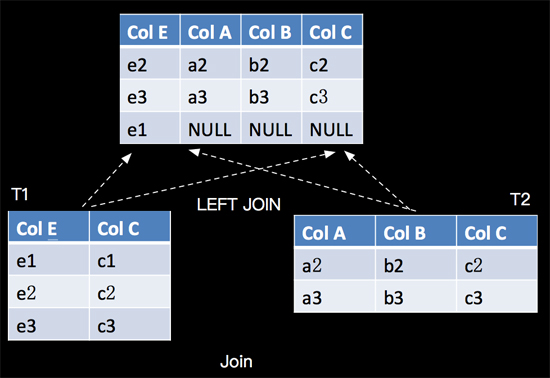
对应的SQL语句如下(LEFT JOIN):
- SELECT ColA, ColB, T2.ColC, ColE FROM TI LEFT JOIN T2 ON T1.ColC = T2.ColC ;
细心的读者可能发现上面T2.ColC是添加了前缀T2了,这里需要说明一下,当两张表有字段名字一样的时候,我需要指定是从那个表里面投影的。
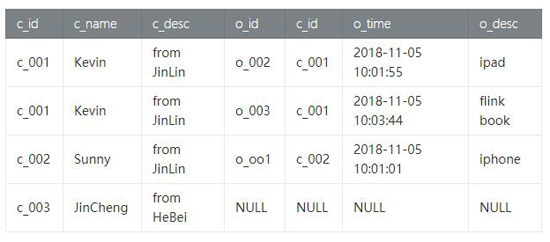
我们查询customer_tab 和 order_tab表,将客户和订单信息选择出来如下:
- val result = customer
- .leftOuterJoin(order.select('o_id, 'c_id as 'o_c_id, 'o_time, 'o_desc), 'c_id === 'o_c_id)
(4) Result
(5) 特别说明
RIGHT JOIN 相当于 LEFT JOIN 左右两个表交互一下位置。FULL JOIN相当于 RIGHT JOIN 和 LEFT JOIN 之后进行UNION ALL操作。
8. Time-Interval JOIN
Time-Interval JOIN 相对于UnBounded的双流JOIN来说是Bounded JOIN。就是每条流的每一条数据会与另一条流上的不同时间区域的数据进行JOIN。对应Apache Flink官方文档的 Time-windowed JOIN(release-1.7之前都叫Time-Windowed JOIN)。 Time-Interval JOIN的语义和实现原理详见《Apache Flink 漫谈系列(12) - Time Interval(Time-windowed) JOIN》。其Table API核心的语法示例,如下:
- ...
- val result = left
- .join(right)
- // 定义Time Interval
- .where('a === 'd && 'c >= 'f - 5.seconds && 'c < 'f + 6.seconds)
- ...
9. Lateral JOIN
Apache Flink Lateral JOIN 是左边Table与一个UDTF进行JOIN,详细的语义和实现原理请参考《Apache Flink 漫谈系列(10) - JOIN LATERAL》。其Table API核心的语法示例,如下:
- ...
- val udtf = new UDTF
- val result = source.join(udtf('c) as ('d, 'e))
- ...
10. Temporal Table JOIN
Temporal Table JOIN 是左边表与右边一个携带版本信息的表进行JOIN,详细的语法,语义和实现原理详见《Apache Flink 漫谈系列(11) - Temporal Table JOIN》,其Table API核心的语法示例,如下:
- ...
- val rates = tEnv.scan("versonedTable").createTemporalTableFunction('rowtime, 'r_currency)
- val result = left.join(rates('o_rowtime), 'r_currency === 'o_currency)...
11. Window
在Apache Flink中有2种类型的Window,一种是OverWindow,即传统数据库的标准开窗,每一个元素都对应一个窗口。一种是GroupWindow,目前在SQL中GroupWindow都是基于时间进行窗口划分的。
(1) Over Window
Apache Flink中对OVER Window的定义遵循标准SQL的定义语法。
按ROWS和RANGE分类是传统数据库的标准分类方法,在Apache Flink中还可以根据时间类型(ProcTime/EventTime)和窗口的有限和无限(Bounded/UnBounded)进行分类,共计8种类型。为了避免大家对过细分类造成困扰,我们按照确定当前行的不同方式将OVER Window分成两大类进行介绍,如下:
- ROWS OVER Window - 每一行元素都视为新的计算行,即,每一行都是一个新的窗口。
- RANGE OVER Window - 具有相同时间值的所有元素行视为同一计算行,即,具有相同时间值的所有行都是同一个窗口。
(a) Bounded ROWS OVER Window
Bounded ROWS OVER Window 每一行元素都视为新的计算行,即,每一行都是一个新的窗口。
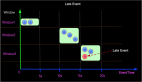
- 语义
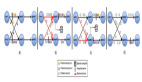
我们以3个元素(2 PRECEDING)的窗口为例,如下图:
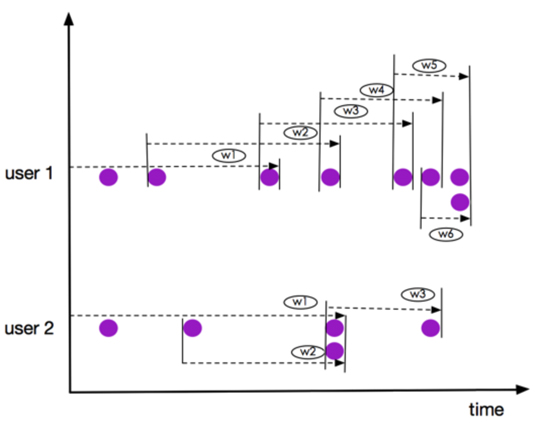
上图所示窗口 user 1 的 w5和w6, user 2的 窗口 w2 和 w3,虽然有元素都是同一时刻到达,但是他们仍然是在不同的窗口,这一点有别于RANGE OVER Window。
- Table API 示例
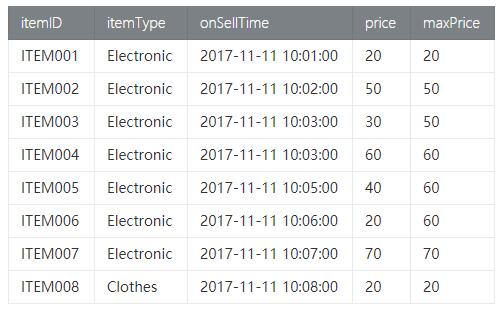
利用item_tab测试数据,我们统计同类商品中当前和当前商品之前2个商品中的最高价格。
- val result = item
- .window(Over partitionBy 'itemType orderBy 'rowtime preceding 2.rows following CURRENT_ROW as 'w)
- .select('itemID, 'itemType, 'onSellTime, 'price, 'price.max over 'w as 'maxPrice)
- Result
(b) Bounded RANGE OVER Window
Bounded RANGE OVER Window 具有相同时间值的所有元素行视为同一计算行,即,具有相同时间值的所有行都是同一个窗口。
- 语义
我们以3秒中数据(INTERVAL '2' SECOND)的窗口为例,如下图:
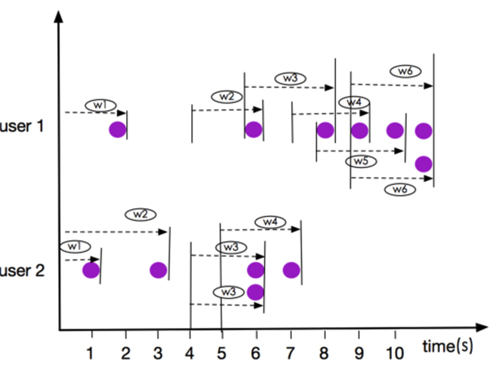
注意: 上图所示窗口 user 1 的 w6, user 2的 窗口 w3,元素都是同一时刻到达,他们是在同一个窗口,这一点有别于ROWS OVER Window。
- Tabel API 示例
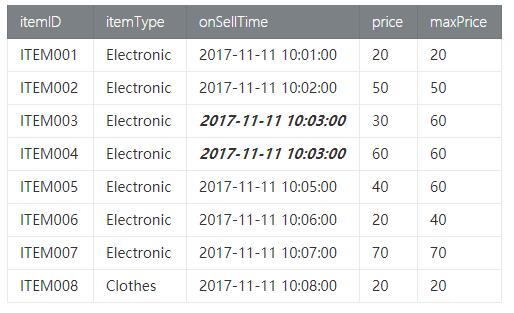
我们统计同类商品中当前和当前商品之前2分钟商品中的最高价格。
- val result = item
- .window(Over partitionBy 'itemType orderBy 'rowtime preceding 2.minute following CURRENT_RANGE as 'w)
- .select('itemID, 'itemType, 'onSellTime, 'price, 'price.max over 'w as 'maxPrice)
(c) Result(Bounded RANGE OVER Window)
- 特别说明
OverWindow最重要是要理解每一行数据都确定一个窗口,同时目前在Apache Flink中只支持按时间字段排序。并且OverWindow开窗与GroupBy方式数据分组最大的不同在于,GroupBy数据分组统计时候,在SELECT中除了GROUP BY的key,不能直接选择其他非key的字段,但是OverWindow没有这个限制,SELECT可以选择任何字段。比如一张表table(a,b,c,d)4个字段,如果按d分组求c的最大值,两种写完如下:
- GROUP BY - tab.groupBy('d).select(d, MAX(c))
- OVER Window = tab.window(Over.. as 'w).select('a, 'b, 'c, 'd, c.max over 'w)
如上 OVER Window 虽然PARTITION BY d,但SELECT 中仍然可以选择 a,b,c字段。但在GROUPBY中,SELECT 只能选择 d 字段。
(2) Group Window
根据窗口数据划分的不同,目前Apache Flink有如下3种Bounded Winodw:
- Tumble - 滚动窗口,窗口数据有固定的大小,窗口数据无叠加;
- Hop - 滑动窗口,窗口数据有固定大小,并且有固定的窗口重建频率,窗口数据有叠加;
- Session - 会话窗口,窗口数据没有固定的大小,根据窗口数据活跃程度划分窗口,窗口数据无叠加。
说明: Aapche Flink 还支持UnBounded的 Group Window,也就是全局Window,流上所有数据都在一个窗口里面,语义非常简单,这里不做详细介绍了。
(a) Tumble
- 语义
Tumble 滚动窗口有固定size,窗口数据不重叠,具体语义如下:
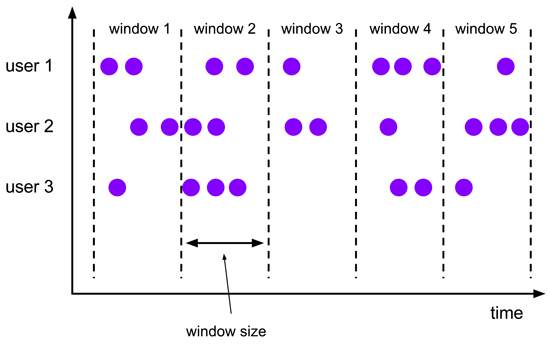
- Table API 示例
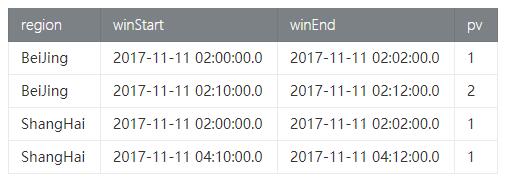
利用pageAccess_tab测试数据,我们需要按不同地域统计每2分钟的淘宝首页的访问量(PV)。
- val result = pageAccess
- .window(Tumble over 2.minute on 'rowtime as 'w)
- .groupBy('w, 'region)
- .select('region, 'w.start, 'w.end, 'region.count as 'pv)
- Result
(b) Hop
Hop 滑动窗口和滚动窗口类似,窗口有固定的size,与滚动窗口不同的是滑动窗口可以通过slide参数控制滑动窗口的新建频率。因此当slide值小于窗口size的值的时候多个滑动窗口会重叠。
- 语义
Hop 滑动窗口语义如下所示:
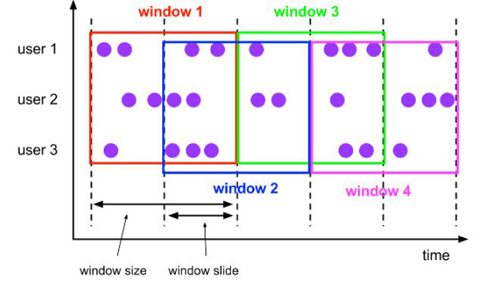
- Table API 示例
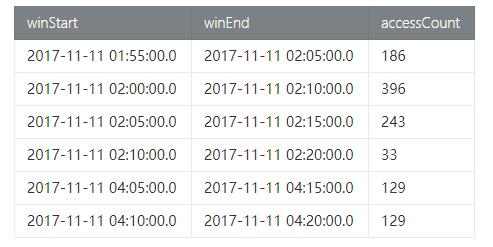
利用pageAccessCount_tab测试数据,我们需要每5分钟统计近10分钟的页面访问量(PV).
- val result = pageAccessCount
- .window(Slide over 10.minute every 5.minute on 'rowtime as 'w)
- .groupBy('w)
- .select('w.start, 'w.end, 'accessCount.sum as 'accessCount)
- Result
(c) Session
Seeeion 会话窗口 是没有固定大小的窗口,通过session的活跃度分组元素。不同于滚动窗口和滑动窗口,会话窗口不重叠,也没有固定的起止时间。一个会话窗口在一段时间内没有接收到元素时,即当出现非活跃间隙时关闭。一个会话窗口 分配器通过配置session gap来指定非活跃周期的时长.
- 语义
Session 会话窗口语义如下所示:
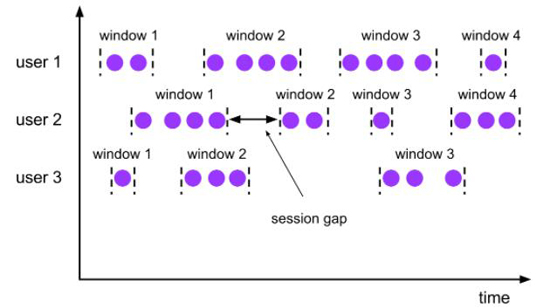
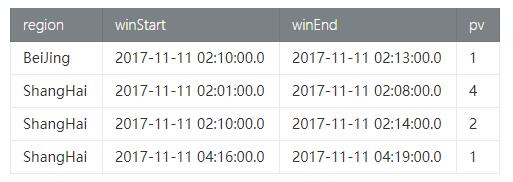
- val result = pageAccessSession
- .window(Session withGap 3.minute on 'rowtime as 'w)
- .groupBy('w, 'region)
- .select('region, 'w.start, 'w.end, 'region.count as 'pv)
- Result
(d) 嵌套Window
在Window之后再进行Window划分也是比较常见的统计需求,那么在一个Event-Time的Window之后,如何再写一个Event-Time的Window呢?一个Window之后再描述一个Event-Time的Window最重要的是Event-time属性的传递,在Table API中我们可以利用'w.rowtime来传递时间属性,比如:Tumble Window之后再接一个Session Window 示例如下:
- ...
- val result = pageAccess
- .window(Tumble over 2.minute on 'rowtime as 'w1)
- .groupBy('w1)
- .select('w1.rowtime as 'rowtime, 'col1.count as 'cnt)
- .window(Session withGap 3.minute on 'rowtime as 'w2)
- .groupBy('w2)
- .select('cnt.sum)
- ...
五、Source&Sink
上面我们介绍了Apache Flink Table API核心算子的语义和具体示例,这部分将选取Bounded EventTime Tumble Window为例为大家编写一个完整的包括Source和Sink定义的Apache Flink Table API Job。假设有一张淘宝页面访问表(PageAccess_tab),有地域,用户ID和访问时间。我们需要按不同地域统计每2分钟的淘宝首页的访问量(PV)。具体数据如下:
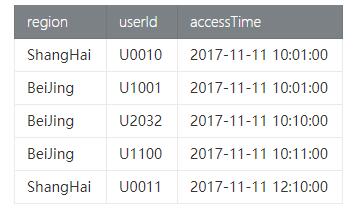
1. Source 定义
自定义Apache Flink Stream Source需要实现StreamTableSource, StreamTableSource中通过StreamExecutionEnvironment 的addSource方法获取DataStream, 所以我们需要自定义一个 SourceFunction, 并且要支持产生WaterMark,也就是要实现DefinedRowtimeAttributes接口。
(1) Source Function定义
支持接收携带EventTime的数据集合,Either的数据结构,Right表示WaterMark和Left表示数据:
- class MySourceFunction[T](dataWithTimestampList: Seq[Either[(Long, T), Long]])
- extends SourceFunction[T] {
- override def run(ctx: SourceContext[T]): Unit = {
- dataWithTimestampList.foreach {
- case Left(t) => ctx.collectWithTimestamp(t._2, t._1)
- case Right(w) => ctx.emitWatermark(new Watermark(w))
- }
- }
- override def cancel(): Unit = ???}
(2) 定义 StreamTableSource
我们自定义的Source要携带我们测试的数据,以及对应的WaterMark数据,具体如下:
- class MyTableSource extends StreamTableSource[Row] with DefinedRowtimeAttributes {
- val fieldNames = Array("accessTime", "region", "userId")
- val schema = new TableSchema(fieldNames, Array(Types.SQL_TIMESTAMP, Types.STRING, Types.STRING))
- val rowType = new RowTypeInfo(
- Array(Types.LONG, Types.STRING, Types.STRING).asInstanceOf[Array[TypeInformation[_]]],
- fieldNames)
- // 页面访问表数据 rows with timestamps and watermarks
- val data = Seq(
- Left(1510365660000L, Row.of(new JLong(1510365660000L), "ShangHai", "U0010")),
- Right(1510365660000L),
- Left(1510365660000L, Row.of(new JLong(1510365660000L), "BeiJing", "U1001")),
- Right(1510365660000L),
- Left(1510366200000L, Row.of(new JLong(1510366200000L), "BeiJing", "U2032")),
- Right(1510366200000L),
- Left(1510366260000L, Row.of(new JLong(1510366260000L), "BeiJing", "U1100")),
- Right(1510366260000L),
- Left(1510373400000L, Row.of(new JLong(1510373400000L), "ShangHai", "U0011")),
- Right(1510373400000L)
- )
- override def getRowtimeAttributeDescriptors: util.List[RowtimeAttributeDescriptor] = {
- Collections.singletonList(new RowtimeAttributeDescriptor(
- "accessTime",
- new ExistingField("accessTime"),
- PreserveWatermarks.INSTANCE))
- }
- override def getDataStream(execEnv: StreamExecutionEnvironment): DataStream[Row] = {
- execEnv.addSource(new MySourceFunction[Row](data)).returns(rowType).setParallelism(1)
- }
- override def getReturnType: TypeInformation[Row] = rowType
- override def getTableSchema: TableSchema = schema
- }
(3) Sink 定义
我们简单的将计算结果写入到Apache Flink内置支持的CSVSink中,定义Sink如下:
- def getCsvTableSink: TableSink[Row] = {
- val tempFile = File.createTempFile("csv_sink_", "tem")
- // 打印sink的文件路径,方便我们查看运行结果
- println("Sink path : " + tempFile)
- if (tempFile.exists()) {
- tempFile.delete()
- }
- new CsvTableSink(tempFile.getAbsolutePath).configure(
- Array[String]("region", "winStart", "winEnd", "pv"),
- Array[TypeInformation[_]](Types.STRING, Types.SQL_TIMESTAMP, Types.SQL_TIMESTAMP, Types.LONG))}
2. 构建主程序
主程序包括执行环境的定义,Source/Sink的注册以及统计查SQL的执行,具体如下:
- def main(args: Array[String]): Unit = {
- // Streaming 环境
- val env = StreamExecutionEnvironment.getExecutionEnvironment
- val tEnv = TableEnvironment.getTableEnvironment(env)
- // 设置EventTime
- env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
- //方便我们查出输出数据
- env.setParallelism(1)
- val sourceTableName = "mySource"
- // 创建自定义source数据结构
- val tableSource = new MyTableSource
- val sinkTableName = "csvSink"
- // 创建CSV sink 数据结构
- val tableSink = getCsvTableSink
- // 注册source
- tEnv.registerTableSource(sourceTableName, tableSource)
- // 注册sink
- tEnv.registerTableSink(sinkTableName, tableSink)
- val result = tEnv.scan(sourceTableName)
- .window(Tumble over 2.minute on 'accessTime as 'w)
- .groupBy('w, 'region)
- .select('region, 'w.start, 'w.end, 'region.count as 'pv)
- result.insertInto(sinkTableName)
- env.execute()
- }
3. 执行并查看运行结果
执行主程序后我们会在控制台得到Sink的文件路径,如下:
- Sink path : /var/folders/88/8n406qmx2z73qvrzc_rbtv_r0000gn/T/csv_sink_8025014910735142911tem
Cat 方式查看计算结果,如下:
- jinchengsunjcdeMacBook-Pro:FlinkTable APIDemo jincheng.sunjc$ cat /var/folders/88/8n406qmx2z73qvrzc_rbtv_r0000gn/T/csv_sink_8025014910735142911tem
- ShangHai,2017-11-11 02:00:00.0,2017-11-11 02:02:00.0,1
- BeiJing,2017-11-11 02:00:00.0,2017-11-11 02:02:00.0,1
- BeiJing,2017-11-11 02:10:00.0,2017-11-11 02:12:00.0,2
- ShangHai,2017-11-11 04:10:00.0,2017-11-11 04:12:00.0,1
表格化如上结果:
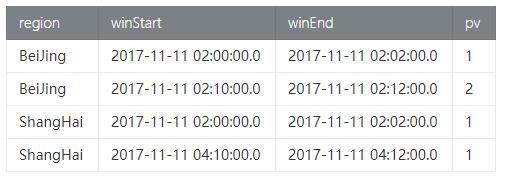
上面这个端到端的完整示例也可以应用到本篇前面介绍的其他算子示例中,只是大家根据Source和Sink的Schema不同来进行相应的构建即可!
六、小结
本篇首先向大家介绍了什么是Table API, Table API的核心特点,然后以此介绍Table API的核心算子功能,并附带了具体的测试数据和测试程序,最后以一个End-to-End的示例展示了如何编写Apache Flink Table API的Job收尾。希望对大家学习Apache Flink Table API 过程中有所帮助。
关于点赞和评论
本系列文章难免有很多缺陷和不足,真诚希望读者对有收获的篇章给予点赞鼓励,对有不足的篇章给予反馈和建议,先行感谢大家!
作者:孙金城,花名 金竹,目前就职于阿里巴巴,自2015年以来一直投入于基于Apache Flink的阿里巴巴计算平台Blink的设计研发工作。
【本文为51CTO专栏作者“金竹”原创稿件,转载请联系原作者】