













【51CTO.com原创稿件】2018年11月30日-12月1日,WOT2018全球人工智能技术峰会在北京•粤财JW万豪酒店盛大召开。60+国内外人工智能一线精英大咖与千余名业界人士齐聚现场,分享人工智能的平台工具、算法模型、语音视觉等技术内容,探讨人工智能如何赋予行业新的活力。两天会议涵盖通用技术、应用领域、行业赋能三大章节,开设13大技术专场,如机器学习、数据处理、AI平台与工具、推荐搜索、业务实践、优化硬件等,堪称人工智能技术盛会。

在《文本分析与NLP》分论坛,宜信技术研发中心数据科学家井玉欣、新浪微博研发中心机器学习研发部NLP负责人胥望军、贝壳找房资深算法专家陈开江和知乎AI团队技术负责人黄波,四位专家围绕文本分析与自然语言处理技术,就人机对话、问答系统等在企业中的应用展开论述。

NLP技术在宜信业务中的技术实践
自然语言数据作为重要的沟通形式以及信息载体,广泛存在于企业日常业务的各个环节之中,合理的NLP技术可以克服自然语言非形式化、不确定性等问题,发掘并捕获其中蕴含的有价值信息,进而用于业务咨询、决策支持、精准营销等方面,是企业重要的AI能力之一。
宜信技术研发中心数据科学家井玉欣在《NLP技术在宜信业务中的技术实践》的演讲中,围绕基于机器学习的NLP技术在宜信内部各业务领域的应用实践展开,分享了相关的实践经验,包括智能机器人在业务支持、客户服务中的探索,基于文本语义分析的用户画像构建,以及NLP算法服务平台化实施思路等。
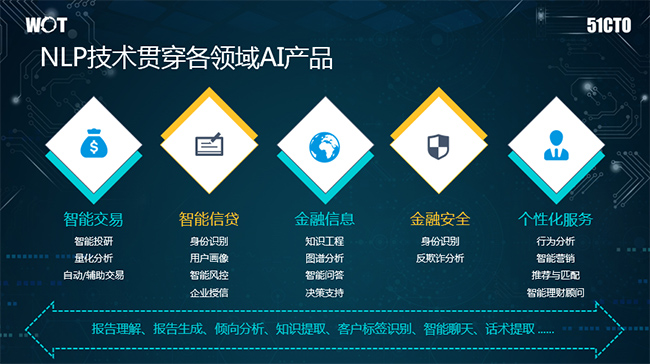
宜信于2006年在北京成立,是一家从事普惠金融以及财富管理的金融科技企业,目前AI技术已广泛应用于宜信的各大产品线,这些AI产品背后都有自然语言处理技术的缩影。例如,在智能交易中有很多投研方面的报告,需要报告理解方面的NLP技术。
自然语言数据存在数据非结构化、语言歧义性、语法不规则、未知语言现象四大缺陷,但也有数据量丰富、信息表述多样性、信息完整性、符合用户习惯四大优点。结合宜信自身的金融数据也有四大特点:词汇专业性强、数据来源广泛、数据形式多样、数据量大但不均衡。

宜信技术研发中心数据科学家井玉欣
由于结构化数据可被挖掘的潜力有限,企业业务越来越关注那些大量的非结构化数据蕴含的高价值信息,如客户信息、产品数据、舆论倾向和策略反馈等。此外,自然语言理解和自然语言生成给人们带来了一种新的会话交互方式,且更加自然、高效,更吸引人,也更符合用户的习惯,这也是NLP技术被广泛应用于各个领域的重要原因。自然语言的特点决定了NLP技术的必要性,NLP承担了各业务领域内自然语言数据的分类、提取、转换、生成任务,是业务领域内重要、基础的技术服务之一。

现代企业对智能聊天机器人有着非常广泛的业务需求。以信贷业务咨询机器人为例,业务的核心是基于检索的问答模型,核心问题是文本语义的相似度问题,涉及语义相似度函数和文本表征函数。对于用户的问题,要在数据库中找出最相似的答案反馈给用户,可以通过构建Dual LSTM神经网络或是拆分成子问题这两种方法来解决。随后,井玉欣介绍了DSSM模型与迁移学习,QA匹配模型、基于NN的匹配模型、知识库检索,模糊 Query 造成的精度下降的解决办法,以及基于文本语义分析的用户画像构建思路等。
自然语言处理在新浪微博中的应用
微博作为国内超大的社交媒体平台,用户每天更新的微博内容达上亿条。由于微博内容的文本短且表达形式丰富,为内容理解带来了较大难度。新浪微博研发中心机器学习研发部NLP负责人胥望军在主题为《自然语言处理(NLP)在微博中的应用》的分享中,介绍了微博内容理解的场景、难点、解决思路和算法,以及在微博兴趣推荐场景下的应用。
微博的推荐场景包括内容推荐和用户推荐两大类,有基于关注关系推荐内容的关注流、基于兴趣推荐内容的热门流、按频道领域推荐内容的频道流,以及基于用户兴趣和关注关系的个性化推送等等。微博的内容推荐框架由物料库、召回(常规/实时)、粗排序、精排序、业务策略及展示、行为收集,以及离线训练模型、常规模型和实时模型等构成。

新浪微博研发中心机器学习研发部NLP负责人胥望军
微博构建了全领域的知识图谱和标签体系,其中一级标签覆盖五十余个领域,二级标签一千余个,三级标签高达一千余万个,标签体系的建立在推荐场景中发挥着重要作用。微博内容通过标签分类解决内容的可解释性,通过主题模型解决内容的匹配问题。此外,新浪微博基于内容理解构建了用户画像,包括用户的兴趣偏好,性别、年龄等自然属性,以及职业、公司、学历等社会属性。
随后,胥望军主要介绍了BERT(Bidirectional Encoder Representations from Transformers)和多模态融合两种算法,BERT用于结合语义本身的信息,表达时间维度;多模态融合用于结合微博富媒体内容信息进行分类,表达空间维度。此外,新浪微博在短文本分类方面也进行了较多尝试,从最初的朴素贝叶斯到深度模型,不断进行对比、更新,进行模型演进。
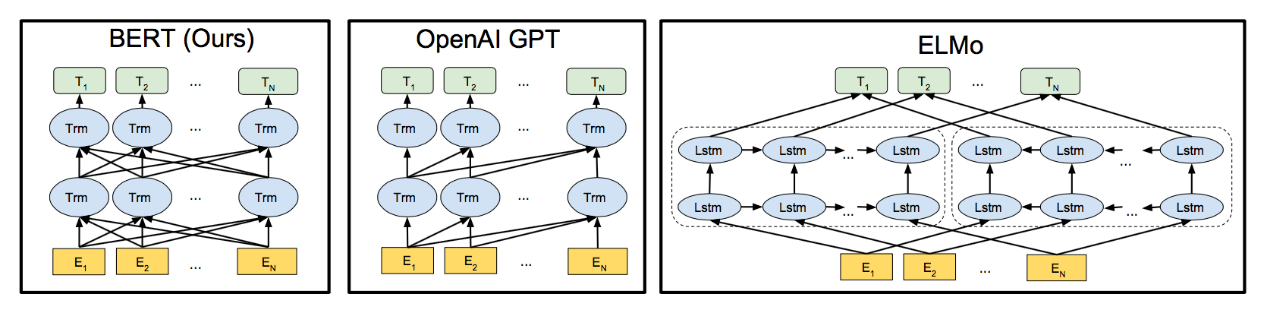
BERT模型几乎能应用于所有的NLP任务。BERT预训练最关键的两点:一是特征抽取器采用Transformer;第二点是预训练时采用双向语言模型。Transformer特征提取器的效果高,能进行分布式处理,采用self attention机制能够捕获远距离特征信息。
微博具有丰富的表达方式,如文字、图片、视频、语音,甚至是用户互动等,都是用来理解内容的各种模态。因此,除了在纯文本方面尝试前沿的算法,新浪微博也在内容的多模态方面进行尝试,例如文本和图片的双端attention融合方式等。
对话系统在房产行业的应用
对话系统是NLP领域常见的技术方向,也是未完全解决的技术难点。近年来,深度学习的兴盛把对话系统带到了一个新高度。贝壳找房作为行业超大规模的居住服务平台,一直在对话系统方面进行长期的探索尝试。常规的对话系统试图取代传统的人工服务,而贝壳找房的对话系统有自己的创新,人工智能和人工知识可以共同学习演化,借助深度学习和传统NLP技术为行业赋能。贝壳找房资深算法专家陈开江分享了贝壳找房在语义理解、对话系统、语音助手和VR看房协同工作方面的相关技术和产品实践。

贝壳找房资深算法专家陈开江
对话系统的难点包含五个方面:一是很难用单一模型解决问题;二是很难获得高质量、低成本的大量标注数据;三是很多人人皆知的常识需要机器去理解;四是对话系统的沟通很难进行量化、标准的评测;五是对话系统很难通用,一个行业、一个场景做到很好的效果,也很难复制到其他行业或场景中直接使用。
贝壳找房作为居住服务平台,在对话系统上有着长期的探索尝试。贝壳找房利用深度学习和传统NLP技术,为众多经纪人赋能,使其作业效率提升3到5倍。房产行业都是高额消费,如果直接人机对话很难建立信任,因此贝壳找房通过用户端的贝壳APP与经纪人端的Link APP进行直接对话,对话系统在对话过程中是一个潜在角色,系统将对话发送给经纪人,经纪人可以对文本进行修饰,也可直接发送给用户。
贝壳找房的对话系统在技术上分为三个阶段:一阶段不断获取对话数据,第二阶段是MVP(Model-View-Presenter ),第三阶段是反复迭代。从对话数据中得到初级知识,首先进行数据的预处理,抽取出Q&A问答的对话体系,对话体系包括流程、意图和槽位(类似函数的参数)三大要素。随后,陈开江重点介绍了单意图单轮会话和多意图多轮对话的主要流程、算法和实验结果等。他透露,目前贝壳找房正在将一些科技元素融入房产行业,例如通过4D看房,提升了经纪人和用户的看房效率,通过AI平台将贝壳的能力开放给内部,服务更多场景,通过行业数仓加房产知识图谱的建设形成行业全景图,助力4D看房及AI平台的建设。
知乎:应用AI打造智能社区
作为国内知名知识分享平台,知乎已拥有 2 亿注册用户,回答数超过 1 亿,目前 AI 已经全面参与知乎的各个环节,大幅提升了社区的运营效率。知乎AI团队技术负责人黄波带来了《知乎AI技术及应用》的精彩演讲,分享了知乎在知识图谱、内容理解、用户分析方面的具体技术及相关应用。
知识图谱分两步;一是知识图谱的构建,包括将结构化与半结构的知识融合,通过数据挖掘知识之间的关系,进行知识表示与建模;第二步是知识图谱的应用,包括语义搜索和推荐,问答和对话系统,大数据分析与决策三部分。

知乎AI团队技术负责人黄波
知识图谱的构建与具体业务场景强相关,目前,知乎构建了以话题、实体为核心的百万级节点,构建了话题相关性图谱、话题上下位图谱、话题与实体的关系图谱等。从长远来看,知乎会将用户作为知识图谱的一个节点,和话题、实体等语义节点建立连接关系。
知识图谱的知识表示分为离散表示和连续表示两种。离散表示的优点是可解释性强,表示能力强,能处理复杂知识结构,缺点是稀疏、扩展性差;连续表示的优点是低维稠密、模型友好,缺点是可解释性差,表示能力弱,复杂知识结构支持较差。因此,在选择知识表示方法时需要根据各自优缺点进行慎重选择。
目前,知乎内容平台有25 万个话题,2700 万个问题,1.2 亿个回答。知乎内容分析包括语义标签、质量标签和时效标签三类。
多种粒度语义标签要求:
- 一二级领域:粒度粗,尽量完备正交的分类体系,保证任一问题或文章能分到某个类别;
- 话题:高准确度,同一个问题或文章可打上多个话题;
- 实体/关键词:高准确度,优先保证热门实体/关键词被召回;
- 语义聚类:语义类簇粒度均,源于数据。
话题匹配方面,由于端到端深度学习模型的效果较差,因此知乎采用基于召回+排序的多策略融合,准确率高达93%,召回率达83%。其中,召回策略包括AC多模匹配、基于点互信息(PMI)两趟对齐算法和基于知识图谱三种召回方式。多策略融合排序模型,分别为基于深度学习模型的语义相似度得分,与候选话题集合的相似度得分,基于话题图谱的权重得分,和基于规则的权重得分四种。
在用户分析方面,分为用户基础画像,用户兴趣画像,和用户社交表示与挖掘三类。其中,用户表示与聚类使用用户搜索内容、关注、收藏、点赞、阅读的回答、文章等对应的话题,作为用户的特征,整理成 one-hot 的向量;使用变分自编码器(Variational Auto-Encoder,VAE) 重建用户话题向量,将 encoder 层输出映射为概率分布,并作为用户的 Embedding 表示。
以上内容是51CTO记者根据WOT2018全球人工智能技术峰会的《文本分析与NLP》分论坛演讲内容整理,更多关于WOT的内容请关注51cto.com。

【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】



























