晚上,RESTful发明人罗伊悄悄来到了咖啡馆,他想看看自己引以为傲的RESTful到底用得怎么样。
(RESTful的故事参见《RPC发展简史》)
靠着门的那张桌子有一帮人,他们居然还在讨论老掉牙的Java RMI,似乎遇到了什么技术难题。
看来无论是什么技术,都会有非常古老的遗留系统需要维护,真是苦逼的程序员啊, 罗伊感慨。
这边的一群人在讨论Google的Protobuf , 看来在序列化这一块儿已经有了长足的进展,都可以实现跨语言序列化了。
再往里边走,终于有人讨论RESTful了! 罗伊心中一阵激动。
只听到一个人说道:“我们领导刚开始强制用RESTful的面向资源的风格,大家还挺新奇的,可是用着用着,我们就‘退回’到那种面向函数的方式了。”
“是啊是啊,我还是更习惯传统的RPC方式,更加直观,尤其是用了Dubbo以后,面向函数的风格不要太爽。”
罗伊心中有点失望。
RESTful的硬伤
“其实吧,RESTful有个硬伤,你们发现没有?” 有个叫做格拉夫的人突然来了一句。
“什么硬伤?”
“我给你们举个例子,” 格拉夫说道,“比如我有两个资源,一个叫做Article ,一个叫做User。”
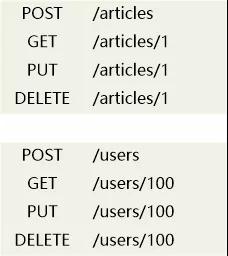
“这很正常啊,对资源可以增删改查。” 罗伊说道,他的话也引起了周围人的附和。
“听我说完,我现在要开发一个手机端,要展示一个文章的列表,假设界面原型是这个样子:”

“***步,我需要获得这些文章列表,可以这么做 GET /articles ”

“这也没问题啊!不就是一个普通的获取资源表示的方式吗?” 人群中有人说道。
可是罗伊敏锐地发现,界面中需要一个“作者头像”, 很明显,这个作者头像并不在Article这个资源中保存, 而是在User中。
在返回的结果中只有author_id, 如果想要获得作者头像,需要对返回的文章列表做循环,取出author_id ,然后在通过/users这个资源进行查询。
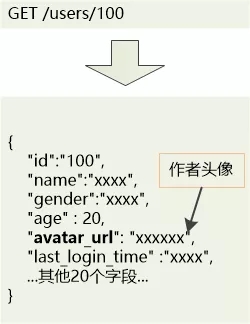
当罗伊把这个查询展示出来以后,周围人群就炸了锅:“有多少个文章,就额外发出多少次查询,这怎么行?! 实际中肯定不能这么干!”
还有人说:“我们仅仅需要头像信息(avatar_url),你返回这么多乱七八糟的gender, age,last_login_time干嘛! ”
“这RESTful真是糟糕啊!”
罗伊有点尬尴,没想到我的RESTful会存在这么两个问题:
1. 发送请求过多 (对每个文章,都得额外查询作者信息)
2. 太多的额外信息(其实只想要avatar_url这个字段)
想到此处,罗伊的心一下子就沉了下去,怎么解决这个问题呢?
中间层
老祖宗教导我们: 计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决!
这个中间层是什么? 罗伊想到了前后端还没有分离的时候,页面都是在后端渲染的,程序员会创建一个VO(View Object),在这个VO中,会把界面展示所需要的信息都封装起来,然后再发给JSP去使用。
在RESTful当中,也可以搞一个类似VO的资源出来啊, 想到此处,他对格拉夫说道:“你为什么不搞一个HotArticle这样的资源出来呢? ”

这个HotArticle可以把文章和作者做个组合,只返回那些界面需要的数据。
格拉夫说道:“这样可不好, 这个HotArticle资源相当于和界面深度绑定了。界面如果要变化,这个HotArticle也得变化,很麻烦啊。”
罗伊说:“那就一起变化呗,反正两个是一致的。”
“不,还有更复杂的情况, 假设界面发生了变化,需要把作者头像替换成文章的封面图, 这时候怎么办呢?”
罗伊说:“我明白你的意思,不就是说要同时支持老的手机端和新的手机端吗?简单,有两种方案。”
(1) 复用HotArticle, 保留原来的avatar_url, 添加一个新的字段 article_img_url, 不同的手机端各取所需。
(2) 给HotArticle做个新版本。老的手机端用老版本,新的手机端用新版本。
“***种方案好!很简单!” 人群中有人说道。
“好啥啊,如果手机界面持续变化,你用***种办法,那个HotArticle很快就成了垃圾堆了,要是没有准确无误的文档,都不知道哪个字段被谁使用!”
“第二种方案会搞出很多版本来,假设要改个公共的东西,比如要增加一个文章的阅读数,那岂不是所有的都得改? ”
可见两种办法各有优劣, 在应对手机端界面持续变化时都有问题,都不***。这也是后端资源和前端界面绑定后的恶果啊。
灵活查询
罗伊陷入了沉思: 能不能让手机端按需查询呢?
服务器端保持最简单的Article 和 User的概念,把他们看成两张表,手机端发出像SQL 那样的查询,把自己需要的给查出来,***能类似于Join的功能。
想到此处,他就写了这么一个SQL :
select a.id, a.title, a.abstract, a.liked_count, u.avatar_url from Article a , User u where a.author_id = u.id

看到这个图,人群轰然叫好:“还是SQL大法好!”
只有格拉夫冷冷地说道:“SQL的局限性太大, 比如我还要把作者的朋友同时显示到手机端,这SQL就不好写了,文章和作者是一一对应的,但是作者的朋友可能有多个,这样SQL的结果集中就会有重复的文章id , title , abstract了。”
罗伊说:“那你说怎么办?”
“关系模型在表示这样的关联的时候,非常不方便,我发明了一个新的模型和新的查询语言, 大家看看吧。”
古怪的查询
格拉夫展示了一个查询的方法:
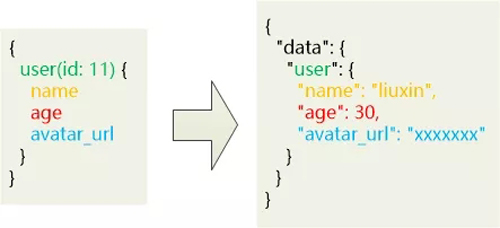
大家猛地一看, 这个查询太古怪了啊,这是什么语法?
虽然古怪,却非常实用,精确地描述了这个需求:我需要一个id 为11的用户, 把他的name, age, avatar_url等字段给我取过来,其他字段就不用发过来了。
查询结果也是标准的JSON格式,和要查询的内容一一对应,非常容易理解。
罗伊问道:“这也没啥啊,你怎么解决之前的问题?”
格拉夫又展示了一个查询,这一次复杂了一些:
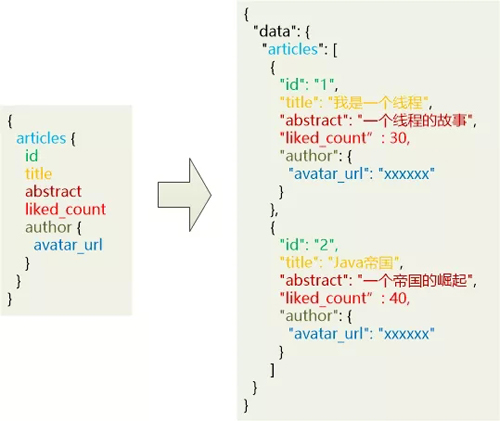
“看到没有? 这次表示一个article列表,每个article元素里边有id, title, abstract,liked_count等字段。 还有一个特殊字段叫做author,相当于在article中嵌套了一个元素,这个author元素还有一个字段叫做avatar_url。 ”
众人一看,觉得非常有意思,用这种方式***地解决了之前的问题。
只需要一次查询,文章和作者的头像一起就发回来了,更重要的是,没有什么乱七八糟的额外信息。
如果想加上作者的朋友信息,可以把查询改成下面这个样子,非常灵活。

看到此处,罗伊就明白了几分,这是一种新的查询方式,不同于关系数据库的SQL, 也不同于RESTful, 很明显,后端的数据模型也得发生变化。
他问道:“你后端的数据模型难道是图Graph吗?”
格拉夫赞道:“被你看出来了,真是厉害,为了支持这样的查询,在后台的数据模型就是一张图:”
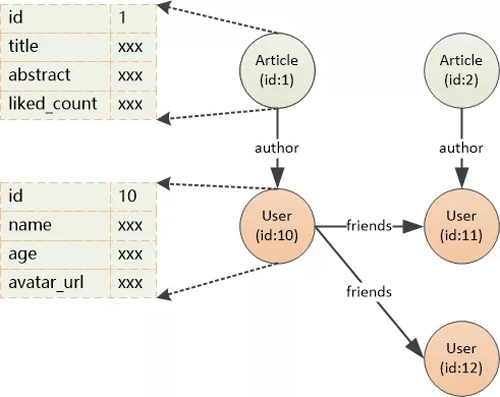
“根据这张图,我就可以查找出任意的数据了,从Article找到作者, 从作者找到相关的朋友......, 只要你把关联做好,没有什么做不到的。”
“那些Article, User类型及其属性是不是也得明确地定义下来?” 罗伊又问道。
格拉夫对罗伊投去赞叹的目光, 说道:“没错,可以这么定义。”

一目了然,大家都非常喜欢!
“这个新的查询语言叫什么名字?”
“我叫格拉夫(Graph),所以这个查询语言叫做GraphQL!”

【本文为51CTO专栏作者“刘欣”的原创稿件,转载请通过作者微信公众号coderising获取授权】