一、说什么
JOIN 算子是数据处理的核心算子,前面我们在《Apache Flink 漫谈系列(09) - JOIN 算子》介绍了UnBounded的双流JOIN,在《Apache Flink 漫谈系列(10) - JOIN LATERAL》介绍了单流与UDTF的JOIN操作,在《Apache Flink 漫谈系列(11) - Temporal Table JOIN》又介绍了单流与版本表的JOIN,本篇将介绍在UnBounded数据流上按时间维度进行数据划分进行JOIN操作 - Time Interval(Time-windowed)JOIN, 后面我们叫做Interval JOIN。
二、实际问题
前面章节我们介绍了Flink中对各种JOIN的支持,那么想想下面的查询需求之前介绍的JOIN能否满足?需求描述如下:
比如有一个订单表Orders(orderId, productName, orderTime)和付款表Payment(orderId, payType, payTime)。 假设我们要统计下单一小时内付款的订单信息。
1. 传统数据库解决方式
在传统刘数据库中完成上面的需求非常简单,查询sql如下::
- SELECT
- o.orderId,
- o.productName,
- p.payType,
- o.orderTime,
- payTime
- FROM
- Orders AS o JOIN Payment AS p ON
- o.orderId = p.orderId AND p.payTime >= orderTime AND p.payTime < orderTime + 3600 // 秒
上面查询可以***的完成查询需求,那么在Apache Flink里面应该如何完成上面的需求呢?
2. Apache Flink解决方式
(1) UnBounded 双流 JOIN
上面查询需求我们很容易想到利用《Apache Flink 漫谈系列(09) - JOIN 算子》介绍了UnBounded的双流JOIN,SQL语句如下:
- SELECT
- o.orderId,
- o.productName,
- p.payType,
- o.orderTime,
- payTime
- FROM
- Orders AS o JOIN Payment AS p ON
- o.orderId = p.orderId AND p.payTime >= orderTime AND p.payTime as timestamp < TIMESTAMPADD(SECOND, 3600, orderTime)
UnBounded双流JOIN可以解决上面问题,这个示例和本篇要介绍的Interval JOIN有什么关系呢?
(2) 性能问题
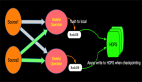
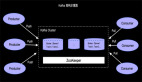
虽然我们利用UnBounded的JOIN能解决上面的问题,但是仔细分析用户需求,会发现这个需求场景订单信息和付款信息并不需要长期存储,比如2018-12-27 14:22:22的订单只需要保持1小时,因为超过1个小时的订单如果没有被付款就是无效订单了。同样付款信息也不需要长期保持,2018-12-27 14:22:22的订单付款信息如果是2018-12-27 15:22:22以后到达的那么我们也没有必要保存到State中。 而对于UnBounded的双流JOIN我们会一直将数据保存到State中,如下示意图:
这样的底层实现,对于当前需求有不必要的性能损失。所以我们有必要开发一种新的可以清除State的JOIN方式(Interval JOIN)来高性能的完成上面的查询需求。
(3) 功能扩展
目前的UnBounded的双流JOIN是后面是没有办法再进行Event-Time的Window Aggregate的。也就是下面的语句在Apache Flink上面是无法支持的:
- SELECT COUNT(*) FROM (
- SELECT
- ...,
- payTime
- FROM Orders AS o JOIN Payment AS p ON
- o.orderId = p.orderId
- ) GROUP BY TUMBLE(payTime, INTERVAL '15' MINUTE)
因为在UnBounded的双流JOIN中无法保证payTime的值一定大于WaterMark(WaterMark相关可以查阅<
3. Interval JOIN
为了完成上面需求,并且解决性能和功能扩展的问题,Apache Flink在1.4开始开发了Time-windowed Join,也就是本文所说的Interval JOIN。接下来我们详细介绍Interval JOIN的语法,语义和实现原理。
三、什么是Interval JOIN
Interval JOIN 相对于UnBounded的双流JOIN来说是Bounded JOIN。就是每条流的每一条数据会与另一条流上的不同时间区域的数据进行JOIN。对应Apache Flink官方文档的 Time-windowed JOIN(release-1.7之前都叫Time-Windowed JOIN)。
1. Interval JOIN 语法
- SELECT ... FROM t1 JOIN t2 ON t1.key = t2.key AND TIMEBOUND_EXPRESSION
TIMEBOUND_EXPRESSION 有两种写法,如下:
- L.time between LowerBound(R.time) and UpperBound(R.time)
- R.time between LowerBound(L.time) and UpperBound(L.time)
- 带有时间属性(L.time/R.time)的比较表达式。
2. Interval JOIN 语义
Interval JOIN 的语义就是每条数据对应一个 Interval 的数据区间,比如有一个订单表Orders(orderId, productName, orderTime)和付款表Payment(orderId, payType, payTime)。 假设我们要统计在下单一小时内付款的订单信息。SQL查询如下:
- SELECT
- o.orderId,
- o.productName,
- p.payType,
- o.orderTime,
- cast(payTime as timestamp) as payTime
- FROM
- Orders AS o JOIN Payment AS p ON
- o.orderId = p.orderId AND
- p.payTime BETWEEN orderTime AND
- orderTime + INTERVAL '1' HOUR
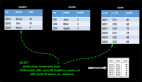
- Orders订单数据
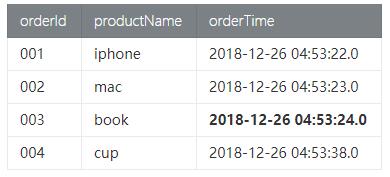
- Payment付款数据
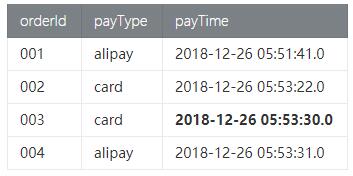
符合语义的预期结果是 订单id为003的信息不出现在结果表中,因为下单时间2018-12-26 04:53:24.0, 付款时间是 2018-12-26 05:53:30.0超过了1小时付款。
那么预期的结果信息如下:

这样Id为003的订单是无效订单,可以更新库存继续售卖。
接下来我们以图示的方式直观说明Interval JOIN的语义,我们对上面的示例需求稍微变化一下: 订单可以预付款(不管是否合理,我们只是为了说明语义)也就是订单 前后 1小时的付款都是有效的。SQL语句如下:
- SELECT
- ...
- FROM
- Orders AS o JOIN Payment AS p ON
- o.orderId = p.orderId AND
- p.payTime BETWEEN orderTime - INTERVAL '1' HOUR AND
- orderTime + INTERVAL '1' HOUR
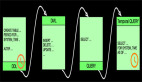
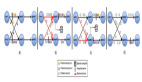
这样的查询语义示意图如下:
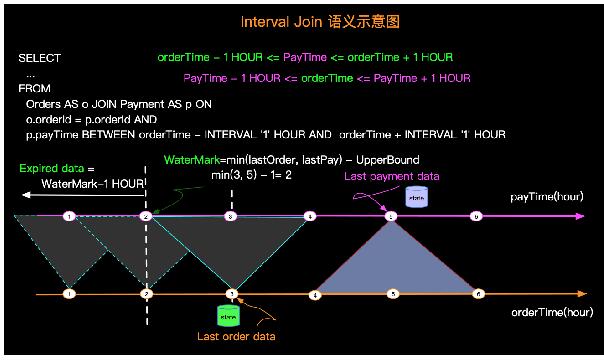
上图有几个关键点,如下:
- 数据JOIN的区间 - 比如Order时间为3的订单会在付款时间为[2, 4]区间进行JOIN。
- WaterMark - 比如图示Order***一条数据时间是3,Payment***一条数据时间是5,那么WaterMark是根据实际最小值减去UpperBound生成,即:Min(3,5)-1 = 2
- 过期数据 - 出于性能和存储的考虑,要将过期数据清除,如图当WaterMark是2的时候时间为2以前的数据过期了,可以被清除。
3. Interval JOIN 实现原理
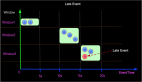
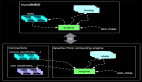
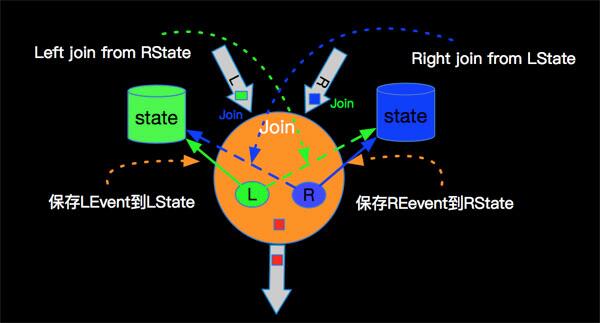
由于Interval JOIN和双流JOIN类似都要存储左右两边的数据,所以底层实现中仍然是利用State进行数据的存储。流计算的特点是数据不停的流入,我们可以不停的进行增量计算,也就是我们每条数据流入都可以进行JOIN计算。我们还是以具体示例和图示来说明内部计算逻辑,如下图:
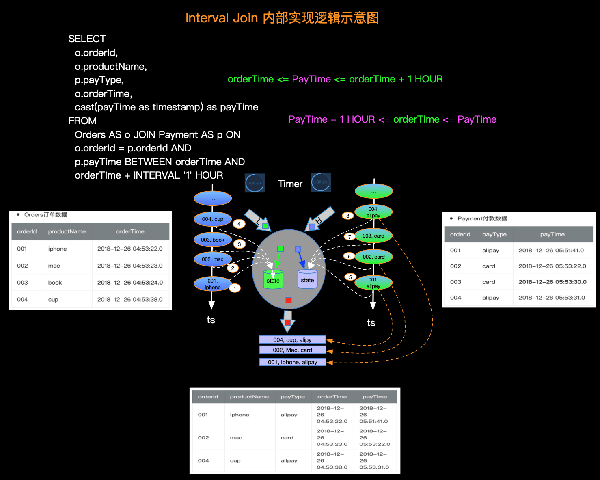
简单解释一下每条记录的处理逻辑如下:

实际的内部逻辑会比描述的复杂的多,大家可以根据如上简述理解内部原理即可。
四、示例代码
我们还是以订单和付款示例,将完整代码分享给大家,具体如下(代码基于flink-1.7.0):
- import java.sql.Timestamp
- import org.apache.flink.api.scala._
- import org.apache.flink.streaming.api.TimeCharacteristic
- import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
- import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
- import org.apache.flink.streaming.api.windowing.time.Time
- import org.apache.flink.table.api.TableEnvironment
- import org.apache.flink.table.api.scala._
- import org.apache.flink.types.Row
- import scala.collection.mutable
- object SimpleTimeIntervalJoin {
- def main(args: Array[String]): Unit = {
- val env = StreamExecutionEnvironment.getExecutionEnvironment
- val tEnv = TableEnvironment.getTableEnvironment(env)
- env.setParallelism(1)
- env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
- // 构造订单数据
- val ordersData = new mutable.MutableList[(String, String, Timestamp)]
- ordersData.+=(("001", "iphone", new Timestamp(1545800002000L)))
- ordersData.+=(("002", "mac", new Timestamp(1545800003000L)))
- ordersData.+=(("003", "book", new Timestamp(1545800004000L)))
- ordersData.+=(("004", "cup", new Timestamp(1545800018000L)))
- // 构造付款表
- val paymentData = new mutable.MutableList[(String, String, Timestamp)]
- paymentData.+=(("001", "alipay", new Timestamp(1545803501000L)))
- paymentData.+=(("002", "card", new Timestamp(1545803602000L)))
- paymentData.+=(("003", "card", new Timestamp(1545803610000L)))
- paymentData.+=(("004", "alipay", new Timestamp(1545803611000L)))
- val orders = env
- .fromCollection(ordersData)
- .assignTimestampsAndWatermarks(new TimestampExtractor[String, String]())
- .toTable(tEnv, 'orderId, 'productName, 'orderTime.rowtime)
- val ratesHistory = env
- .fromCollection(paymentData)
- .assignTimestampsAndWatermarks(new TimestampExtractor[String, String]())
- .toTable(tEnv, 'orderId, 'payType, 'payTime.rowtime)
- tEnv.registerTable("Orders", orders)
- tEnv.registerTable("Payment", ratesHistory)
- var sqlQuery =
- """
- |SELECT
- | o.orderId,
- | o.productName,
- | p.payType,
- | o.orderTime,
- | cast(payTime as timestamp) as payTime
- |FROM
- | Orders AS o JOIN Payment AS p ON o.orderId = p.orderId AND
- | p.payTime BETWEEN orderTime AND orderTime + INTERVAL '1' HOUR
- |""".stripMargin
- tEnv.registerTable("TemporalJoinResult", tEnv.sqlQuery(sqlQuery))
- val result = tEnv.scan("TemporalJoinResult").toAppendStream[Row]
- result.print()
- env.execute()
- }
- }
- class TimestampExtractor[T1, T2]
- extends BoundedOutOfOrdernessTimestampExtractor[(T1, T2, Timestamp)](Time.seconds(10)) {
- override def extractTimestamp(element: (T1, T2, Timestamp)): Long = {
- element._3.getTime
- }
- }
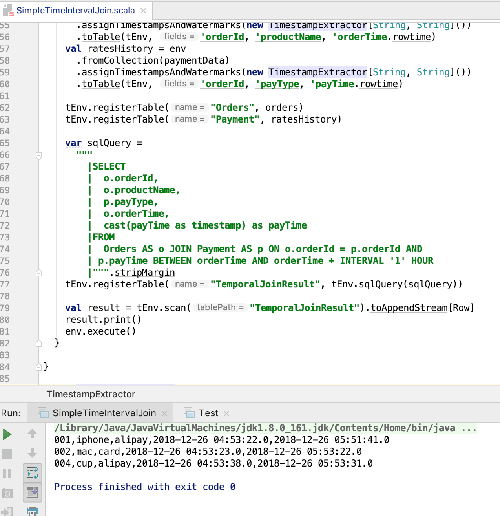
运行结果如下:
五、小节
本篇由实际业务需求场景切入,介绍了相同业务需求既可以利用Unbounded 双流JOIN实现,也可以利用Time Interval JOIN来实现,Time Interval JOIN 性能优于UnBounded的双流JOIN,并且Interval JOIN之后可以进行Window Aggregate算子计算。然后介绍了Interval JOIN的语法,语义和实现原理,***将订单和付款的完整示例代码分享给大家。期望本篇能够让大家对Apache Flink Time Interval JOIN有一个具体的了解!
关于点赞和评论
本系列文章难免有很多缺陷和不足,真诚希望读者对有收获的篇章给予点赞鼓励,对有不足的篇章给予反馈和建议,先行感谢大家!
作者:孙金城,花名 金竹,目前就职于阿里巴巴,自2015年以来一直投入于基于Apache Flink的阿里巴巴计算平台Blink的设计研发工作。
【本文为51CTO专栏作者“金竹”原创稿件,转载请联系原作者】