近日,Facebook 人工智能研究院 ( FAIR ) 宣布开源首个全卷积语音识别工具包 wav2letter++。系统基于全卷积方法进行语音识别,训练语音识别端到端神经网络的速度是其他框架的 2 倍多。他们在博客中对此次开源进行了详细介绍。
由于端到端语音识别技术能够轻易扩展至多种语言,同时能在多变的环境下保证识别质量,因此被普遍认为是一种高效且稳定的语音识别技术。虽说递归卷积神经网络在处理具有远程依赖性的建模任务上很占优势,如语言建模、机器翻译和语音合成等,然而在端到端语音识别任务上,循环架构才是业内的主流。
有鉴于此,Facebook 人工智能研究院 (FAIR) 的语音小组上周推出首个全卷积语音识别系统,该系统完全由卷积层组成,取消了特征提取步骤,仅凭端到端训练对音频波形中的转录文字进行预测,再通过外部卷积语言模型对文字进行解码。随后 Facebook 宣布开源 wav2letter ++——这种高性能框架的出现,让端到端语音识别技术得以实现快速迭代,为技术将来的优化工作和模型调优打下夯实的基础。
与 wav2letter++ 一同宣布开源的,还有机器学习库 Flashlight。Flashlight 是建立在 C++基础之上的机器学习库,使用了 ArrayFire 张量库,并以 C++进行实时编译,目标是最大化 CPU 与 GPU 后端的效率和规模,而 wave2letter ++工具包建立在 Flashlight 基础上,同样使用 C++进行编写,以 ArrayFire 作为张量库。
这里着重介绍一下 ArrayFire,它可以在 CUDA GPU 和 CPU 支持的多种后端上被执行,支持多种音频文件格式(如 wav、flac 等),此外还支持多种功能类型,其中包括原始音频、线性缩放功率谱、log 梅尔谱 (MFSC) 和 MFCCs 等。
Github 开源地址:
在 Facebook 对外发布论文中,wav2letter++被拿来与其他主流开源语音识别系统进行对比,发现 wav2letter++训练语音识别端到端神经网络速度是其他框架的 2 倍还多。其使用了 1 亿个参数的模型测试,使用从 1~64 个 GPU,且训练时间是线性变化的。
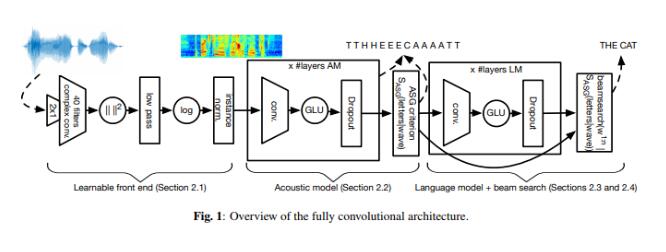
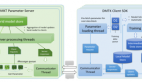
图片来源:Facebook
上面为系统的网络结构图,主要由 4 个部分组成:
可学习前端(Learnable front end):这部分包含宽度为 2 的卷积(用于模拟预加重流程)和宽度为 25 ms 的复卷积。在计算完平方模数后,由低通滤波器和步长执行抽取任务。最后应用于 log-compression 和 per-channel mean-variance normalization 上。
声学模型:这是一款带有门线性单元(GLU)的卷积神经网络,负责处理可学习前端的输出内容。基于自动分割准则,该模型在字母预测任务上进行训练。
语言模型:该卷积语言模型一共包含 14 个卷积残差块,并将门线性单元作为激活函数,主要用来对集束搜索解码器中语言模型的预备转录内容进行评分。
集束搜索解码器(Beam-search decoder):根据声学模型的输出内容生成词序列。
文章转载自:https://www.leiphone.com/news/201812/t4K6BSfiYXkruwZb.html 作者:黄善清