【51CTO.com原创稿件】随着公司业务增长迅速,数据量越来越大,数据的种类也越来越丰富,分析人员对数据处理的响应延时要求也越来越高,传统的大数据处理工具已经无法满足业务的需求。
特别是 OLAP 分析场景,需要对各种维度和度量进行上卷、下钻、切片和切块分析,并要求分析结果能够实时返回。
因此我们调研和对比了一些目前主流的 OLAP 分析工具,针对聚合计算的实时分析,我们引入了开源分析工具 Druid。
Druid 介绍
说起 Druid,大家首先想到的是阿里的 Druid 数据库连接池,而本文介绍的 Druid 是一个在大数据场景下的解决方案,是需要在复杂的海量数据下进行交互式实时数据展现的 BI/OLAP 工具。
它有三个特点:
- 处理的数据量规模较大。
- 可以进行数据的实时查询展示。
- 它的查询模式是交互式的,这也说明其查询并发能力有限。
目前 Druid 广泛应用在国内外各个公司,比如阿里,滴滴,知乎,360,eBay,Hulu 等。
Druid 之所以能够在 OLAP 家族中占据一席之地,主要依赖其强大的 MPP 架构设计,关于它的架构,这里就不展开描述了,感兴趣的同学可以登陆官网 druid.io 进行了解。
除了 MPP 架构外,它还运用到了四点重要的技术,分别是:
- 预聚合
- 列式存储
- 字典编码
- 位图索引
预聚合算是 Druid 的一个非常大的亮点,通过预聚合可以减少数据的存储以及避免查询时很多不必要的计算。
由于 OLAP 的分析场景大多只关心某个列或者某几个列的指标计算,因此数据非常适合列式存储。
在列式存储的基础之上,再加上字段编码,能够有效的提升数据的压缩率,然后位图索引让很多查询最终直接转化成计算机层面的位计算,提升查询效率。
Druid 既然是 OLAP 工具,那它和其他 OLAP 工具有哪些差异呢?
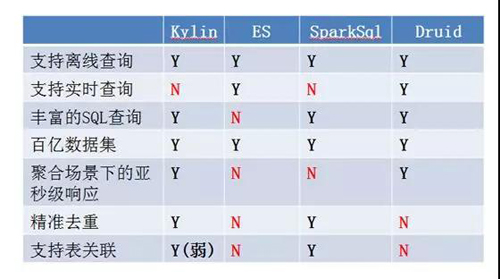
图 1:OLAP 工具的对比
从上图可以看出,Kylin 和 Druid 整体上相比较其他两个还是很有优势的:
相比较 Kylin,Druid 没有模型管理和 cube 管理的能力,Kylin 无法提供实时查询。
相比较 ES,Druid 的优势在于聚合计算,ES 的优势在于查明细,在苏宁,对 Druid 的使用,一般应用在需要对数据进行实时聚合查询的场景。
Druid 在苏宁的应用场景
苏宁很多业务场景都使用到了 Druid,本文将列举两个例子,分别是门店 App 系统以及诸葛系统。
门店 App 系统
门店 App 系统是一款集数据服务、销售开单、会员营销、收发盘退、绩效管理、V 购用户沟通、学习中心等于一体的门店店员移动工作平台,其销售界面如下所示:

图 2:销售界面
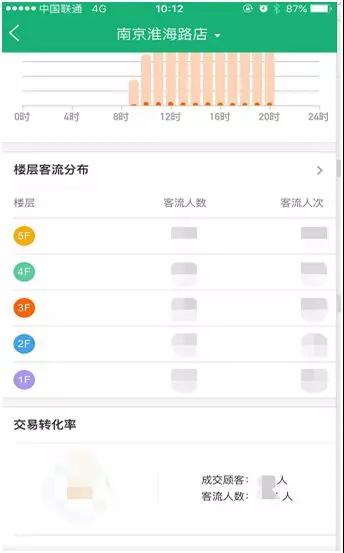
图 3:客流界面
门店 App 业务大致情况如下:
- 数据量:保存近几年的数据。
- 数据接入方式:Kafka 实时数据接入,隔天离线数据覆盖昨天数据。
- 查询方式:实时查询。
- 业务实现:topN 实现销售额曲线展示,groupby 分组楼层客流分布,timeserise 做天汇总。
诸葛报表系统
诸葛报表系统是苏宁重要的系统之一,能够帮助业务做出决策分析,减少手工分析成本,帮助提高销售,该系统可以主动给业务发送销售数据,推动业务进行销售关注和分析。
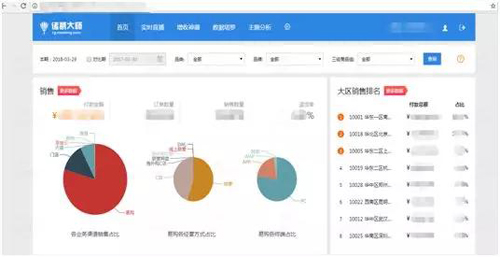
图 4:诸葛报表系统
诸葛业务大致情况如下:
- 数据量:保存近几年数据。
- 数据接入方式:Kafka 实时数据接入。
- 查询方式:实时查询。
- 业务实现:topN 实现销售饼图展示,groupby 分组实现大区销售排名。
上文简单介绍了一下什么是 Druid 以及 Druid 在苏宁的两个业务场景应用,那 Druid 在苏宁的平台建设是怎样的呢?
Druid 在苏宁的平台建设
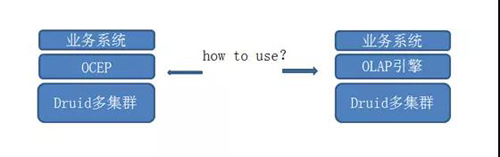
图 5:两种架构
Druid 的平台建设在苏宁主要有两种:
- 通过 OCEP(提供负载均衡,查询路由功能等),使用 Druid 原生的能力,满足业务一系列的需求。
- 结合苏宁的天工系统和百川系统,Druid 作为 OLAP 引擎的底层加速系统,提供统一报表的查询能力。
目前,大部分的业务使用 Druid 的方式主要还是第一种,有少量的业务使用的是第二种方式,随着第二种方式的逐渐成熟,后面大家的业务会逐渐从第一种方式迁移到第二种上去,实现资源统一。
基于 OCEP 的平台架构
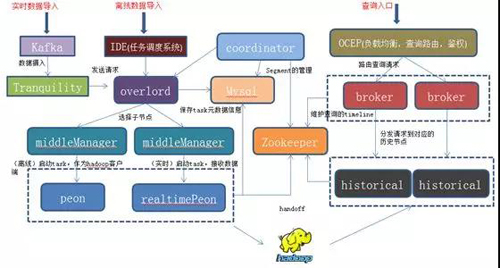
图 6:基于 OCEP 的平台架构
该平台主要依赖 OCEP,对外提供一系列的 OLAP 查询服务,满足集团内部各种业务的维度指标分析需求:
- 通过 tranquility 实时消费业务数据,发送到 Druid 的 realtime peon,并进行 handoff 持久化到 HDFS 上,由 coordinator 进行加载到 historical 中,提供查询服务。
- 通过苏宁自研的 IDE 任务调度系统,将 HDFS 上的离线数据(一般是数仓数据)经过 mapreduce 任务处理完写入到 Druid 指定的 HDFS 路径下,同样由 coordinator 进行加载到 historical 中,提供查询服务。
- 最后通过 OCEP,将业务的查询路由到各个 broker 上,broker 再分发给 historical,经过 historical 计算后,再向上一层一层返回给业务。
基于 OLAP 引擎的平台架构
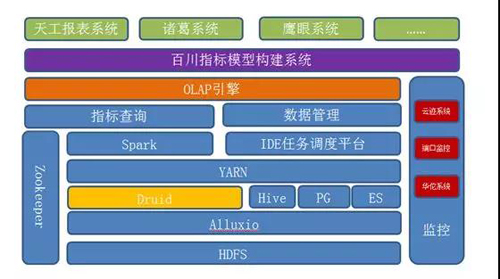
图 7:基于 OLAP 引擎的平台架构
为保证数据的一致性和统一性,该平台基于 OLAP 引擎,为集团各个业务提供统一的维度指标分析系统:
- 百川系统通过 OLAP 引擎构建模型,OLAP 引擎根据业务需求,将模型拆分成若干个 cube,存储到底层的 Druid,Hive,PG 和 ES。我们称这个过程为模型加速,另外,百川系统自身会构建各种各样的指标。
- 业务方,比如天工,诸葛等系统通过百川提供的指标,选择其中一个或多个进行报表的构建,其查询请求会发送到百川系统。
- 百川系统构造 SQL 语句,再把请求发送到 OLAP 引擎,OLAP 引擎通过底层的 Spark 平台,解析 SQL 语句,将请求路由到 Druid,ES,Hive 和 PG,其中,时序化数据的聚合查询,将路由到 Druid 平台,最后查询结果一层一层汇总到上层的业务系统。
- 整个系统的监控,通过云迹系统、华佗系统等进行监控,将系统日志接入云迹,将系统的 metric 信息接入华佗。
随着 Druid 平台建设的不断推进,使用 Druid 的业务也越来越多,在使用的过程中也会遇到各种各样的问题,下文总结了苏宁业务开发人员在使用 Druid 中遇到的一些问题,希望对正在阅读本文的读者有些帮助。
Druid 使用建议
本小节主要想结合实际问题,给大家提供一些 Druid 的使用建议,供大家参考。
①什么样的业务适合用 Druid?
建议如下:
- 时序化数据:Druid 可以理解为时序数据库,所有的数据必须有时间字段。
- 实时数据接入可容忍丢数据(tranquility):目前 tranquility 有丢数据的风险,所以建议实时和离线一起用,实时接当天数据,离线第二天把今天的数据全部覆盖,保证数据完备性。
- OLAP 查询而不是 OLTP 查询:Druid 查询并发有限,不适合 OLTP 查询。
- 非精确的去重计算:目前 Druid 的去重都是非精确的。
- 无 Join 操作:Druid 适合处理星型模型的数据,不支持关联操作。
- 数据没有 update 更新操作,只对 segment 粒度进行覆盖:由于时序化数据的特点,Druid 不支持数据的更新。
②如何设置合理的 Granularity?

图 8:Granularity 设置
首先解释下 segmentGranularity 和 queryGranularity,前者是 segment 的组成粒度,后者是 segment 的聚合粒度。
要求 queryGranularity 小于等于 segmentGranularity,然后在数据导入时,按照下面的规则进行设置。
segmentGranularity(离线数据导入的设置):
- 导入的数据是天级别以内的:“hour”或者“day”。
- 导入的数据是天级别以上的:“day”。
- 导入的数据是年级别以上的:“month”。
需要说明的是,这里我们仅仅是简单的通过 intervals 进行 segmentGranularity 的设置,更加合理的做法应该是结合每个 segment 的大小以及查询的复杂度进行综合衡量。
考虑到 tranquility 实时任务的特殊性和数据的安全性,我们建议实时数据导入时,segmentGranularity 设置成“hour”。
queryGranularity:根据业务查询最小粒度和查询复杂度来定,假设查询只需要到小时粒度,则该参数设置为“hour”。
③需要去重的维度到底需不需要定义到维度列中?
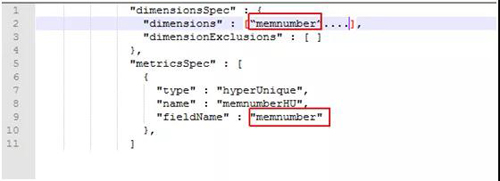
图 9:去重维度定义
如果去重的维度只需要去重计算,没有其他的作用,譬如进行过滤或者作为分组字段,我们建议不要添加到维度列中,因为不添加的话,这样数据的预聚合效果更好。
④如何选择查询方式?
常用的三种查询:
- select sum(A) from DS where time>? [timeseries]
- select sum(A) from DS where time>? group by B order by C limit 2 [topN]
- select sum(A) from DS where time>? group by B,C order by C limit 2[groupby]
没有维度分组的场景使用 timeseries,单维度分组查询的场景使用 topN,多维度分组查询场景使用 groupby。
由于 groupby 并不会将 limit 下推(Druid 新版本进行了优化,虽然可以下推,但是对于指标的排序是不准确的),所以单维度的分组查询,尽量用 topN 查询。
我们做的工作
从 Druid 引入苏宁之后,不久便承担起了 OLAP 分析的重任,作为底层核心引擎支撑模型和指标服务,并为集团各条业务线的 OLAP 分析服务,在过去的时间里,我们做了很多工作,本文列举一些进行说明。
①OCEP(Druid 集群前置 proxy)
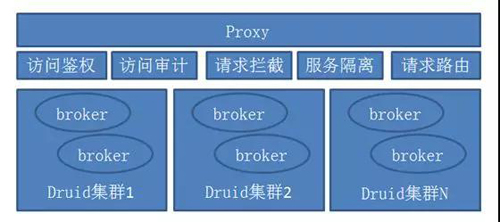
图 10:OCEP(Druid 集群前置 proxy)
OCEP 是 Druid 集群一个前置 proxy,通过它来提供更加完备的 Druid 集群化和服务化能力,并解决当前 Druid 服务存在的各种问题。
它提供的功能主要有:
- 访问鉴权(针对每个 datasource 提供 token 访问鉴权,保证数据安全)。
- 访问审计(对每个查询都会生成唯一的 queryId,提供完整的请求来源)。
- 请求拦截(对非预期的访问,制定拦截策略,细化到具体的 datasource 和查询语句)。
- 请求路由(根据集群名称和 datasource,将请求路由到指定的 Druid 集群,并根据后端 broker 的压力,将请求负载均衡各个 broker 上)。
- 服务隔离(可设置策略,对于不同的 datasource 的请求,可路由到指定的 broker 上,实现 broker 隔离)。
②Druid 查询客户端
官方提供的查询方式是通过编写 Json 文件,以 HTTP 的方式请求 Druid,然而这种方式的缺点也很明显,首先 Json 内容书写繁琐,格式极易写错,另外在 Java 开发时,出现问题不利于定位。

图 11:Json 语句
于是我们封装了一层 Java API,如下图:
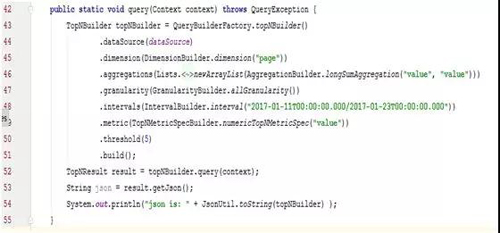
图 12:Druid Java Client
③资源隔离
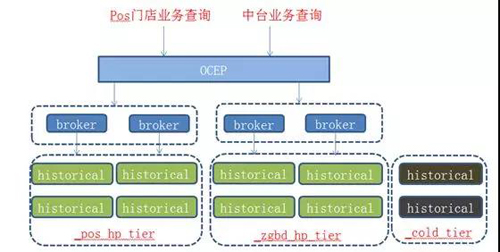
图 13:资源隔离
不同业务的数据量有大小之分以及对服务稳定性要求不一样,我们通过以下三点实现业务层面的隔离:
- Historical 分组:集群设置不同的 tier,存储不同的业务数据。
- Broker 隔离:通过 OCEP 设置 datasource 白名单,不同的 broker 只提供某个或某几个 datasource 的查询。
- 冷热数据隔离:通过设置 datasource 的 rule,将冷热数据分别存储在不同的 tier 中。
- Druid 白名单控制。
集群稳定性压倒一切,防止控制以外的机器对集群进行无效查询和攻击,我们通过增加一个 whitelist 的 extension,以模块的方式在服务端进行白名单的控制。
并且可以针对不同的服务进行控制,将 whitelist 的配置文件写在 Druid 的 metadata 的 config 表中,实现动态更新。
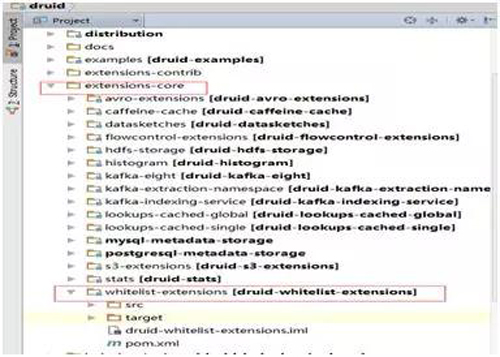
图 14:白名单 extension
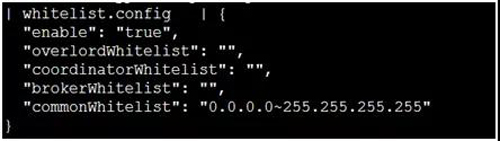
图 15:Druid 白名单配置
④Druid 离线导入时对 intervals 的控制
有些离线导入的任务,占用了 YARN 太多的资源,个别任务消耗了上千个或者上万的 container 资源,分析发现是由于业务设置的 segmentGranularity 不合理,最终会导致 segment 过多,产生很多 HDFS 小文件。
于是我们在 overlord 服务端,增加参数“druid.indexer.intervals.maxLimit”,对离线任务进行判断。
如果 segmentGranularity 和 interval 设置的不合理,将禁止提交。譬如,segmentGranularity 设置的是小时,interval 设置的间隔是 1 年,这种是不合理的,服务端将禁止数据导入。
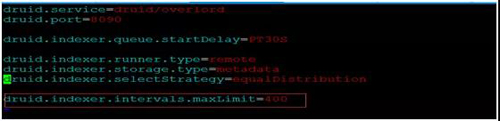
图 16:离线导入对 intervals 的控制参数配置
⑤Coordinator 自动 merge segment 时启动 task 的并发数控制
在集群中,我们打开了 coordinator 自动 merge segment 的功能,coordinator 默认每隔 30 分钟,启动 merge 线程,扫描所有的 datasource,将过小的 segment 按要求进行合并。
每当一批 segment 符合 merge 要求了,就会请求 overlord 进行启动 merge task。
如果集群内小 segment 很多,merge task 将启动无数个,堵塞 middleManager 的 peon 资源,我们增加限制 merge task 的并发数的参数,保证每次 merge 线程只启动一定数量的 task。
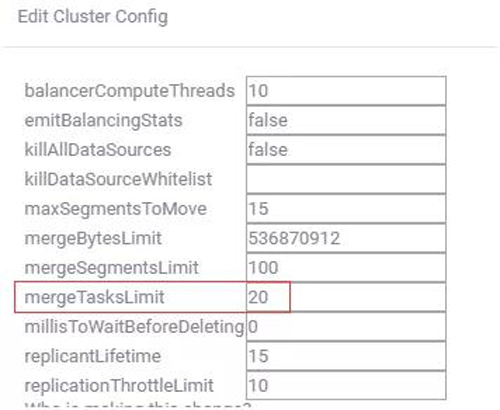
图 17:设置 merge task 的并发数
⑥Druid 监控
监控对于任何一个系统而言都是非常重要的,可以帮助我们提前预知系统的健康状况,Druid 的监控主要有两点,业务查询情况和平台运行情况。
前者主要包括 datasource 的查询量、查询耗时、网络流量等;后者主要包括各个服务的 gc 情况、cpu 和内存使用情况、空闲 Jetty 线程数等。
我们的监控方案是 Druid_Common 集群和 Druid_OLAP 集群相互监控,互相存储对方的 metric 信息,然后通过 superset 展示。
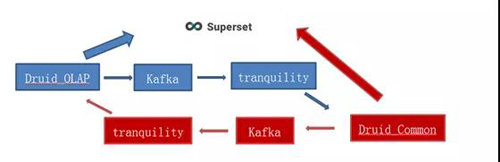
图 18:Druid 的监控方案
未来规划
Druid 在苏宁还有很长一段路要走,无论从查询优化方面还是集群管理方面,都有很多事情要做。
查询优化方面:
- 高基数问题:高基数查询一直是 OLAP 查询的一大痛点,新版本虽然支持 limit 下推,但也只是对维度进行排序的时候,才能保证准确性。
- SQL 支持:进行 Druid 版本升级,提供丰富的 SQL 查询接口。
- 精准去重:目前 Druid 对去重的计算,无论是 HyperLogLog、ThetaSketch 还是最新版本提供的 HLLSketch 都是非精确的,后面考虑是否可以通过集成 bitmap 解决。
集群管理方面:
- Kafkaindex service 使用:tranquility 的时间窗口限制会造成延迟很大的数据丢失,而且实时 peon 的管理不够灵活,某些场景下,也会造成数据丢失。
而 Kafka index service 的实时 peon 调用了 Kafka 底层的 API,管理更灵活,依赖 Kafka 实现数据的不丢不重。
- Datasource 跨集群迁移:Druid 无论是数据导入还是数据查询都非常依赖 Zookeeper,当集群规模越来越大,datasource 越来越多的时候,Zookeeper 也许会成为瓶颈。
这样的话,就需要做 datasource 的迁移,而迁移工作涉及到 datasource 元数据和 HDFS 数据的迁移,如何让迁移工作轻量化,是我们需要思考的。
作者:李成露
简介:苏宁易购 IT 总部大数据中心大数据平台研发工程师。多年大数据底层平台开发经验。现负责苏宁大数据底层平台的计算资源调度平台以及 Druid 平台的研发工作,提供离线计算平台和实时计算平台的资源调度方案,提供基于 Druid 的 OLAP 平台,为集团各种维度指标分析业务提供稳定保障。

【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】