Redis 是一个开源的使用 ANSI C 语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value 数据库,并提供多种语言的 API。
如今,互联网业务的数据正以更快的速度在增长,数据类型越来越丰富,这对数据处理的速度和能力提出了更高要求。Redis 是一种开源的内存非关系型数据库,给开发人员带来的体验是颠覆性的。在自始至终的设计过程中,都充分考虑高性能,这使得 Redis 成为当今速度最快的 NoSQL 数据库。
考虑高性能的同时,高可用也是很重要的考虑因素。互联网 7x24 无间断服务,在故障期间以最快的速度 Failover,能给企业带来最小的损失。
那么,在实际应用中,都有哪些高可用架构呢?架构之间有何优劣?我们应该怎么取舍?有哪些***实践?以下四个方面十个具有典型性和普遍性问题的解答,可以作为了解 Redis 高可用及 Redis 运维的参考。
一、高可用相关
1:Redis 常用高可用架构有哪些?
Redis 高可用架构如下:
- Redis Sentinel 集群 + 内网 DNS + 自定义脚本
- Redis Sentinel 集群 + VIP + 自定义脚本
- 封装客户端直连 Redis Sentinel 端口
JedisSentinelPool,适合 Java
PHP 基于 phpredis 自行封装
- Redis Sentinel 集群 + Keepalived/Haproxy
- Redis M/S + Keepalived
- Redis Cluster
- Twemproxy
- Codis
2:Redis 高可用架构优劣对比?
—Redis Sentinel 集群 + 内网 DNS + 自定义脚本
优点:
- 秒级切换
- 脚本自定义,架构可控
- 对应用透明
缺点:
- 维护成本略高
- 依赖 DNS,存在解析延时
- Sentinel 模式存在短时间的服务不可用
—Redis Sentinel 集群 + VIP + 自定义脚本
优点:
- 秒级切换
- 脚本自定义,架构可控
- 对应用透明
缺点:
- 维护成本略高
- Sentinel 模式存在短时间的服务不可用
—封装客户端直连 Redis Sentinel 端口
优点:
- 服务探测故障及时
- DBA 维护成本低
缺点:
- 依赖客户端支持 Sentinel
- Sentinel 服务器需要开放访问权限
- 对应用有侵入性
—Redis Sentinel 集群 + Keepalived/Haproxy
优点:
- 秒级切换
- 对应用透明
缺点:
- 维护成本高
- 存在脑裂
- Sentinel 模式存在短时间的服务不可用
—Redis M/S +Keepalived
优点:
- 秒级切换
- 对应用透明
- 部署简单,维护成本低
缺点:
- 需要脚本实现切换功能
- 存在脑裂
- (Redis Cluster、Twemproxy、Codis 优劣对比见下个问题)
3:常见的 Redis 集群方案有哪些优缺点?
Twemproxy:
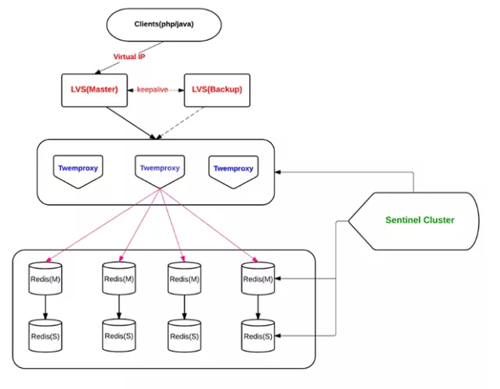
多个同构 Twemproxy(配置相同)同时工作,接受客户端的请求,根据 hash 算法,转发给对应的 Redis。
优点:
- 开发简单,对应用几乎透明
- 历史悠久,方案成熟
缺点:
- 代理影响性能
- LVS 和 Twemproxy 会有节点性能瓶颈
- Redis 扩容非常麻烦
- Twitter 内部已放弃使用该方案,新使用的架构未开源
Codis:
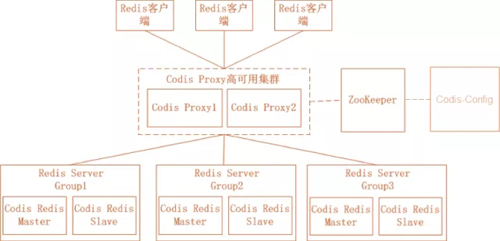
- ZooKeeper
存放路由表和代理节点元数据
分发Codis-Config的命令
- Codis-Config 集成管理工具,有web界面
- Codis-Proxy
无状态代理,兼容Redis协议
对业务透明
- Codis-Redis
基于2.8版本,二次开发
加入slot支持和迁移命令
优点:
- 开发简单,对应用几乎透明
- 性能比 Twemproxy 好
- 有图形化界面,扩容容易,运维方便
缺点:
- 代理依旧影响性能
- 组件过多,需要很多机器资源
- 修改了 Redis 代码,导致和官方无法同步,新特性跟进缓慢
- 开发团队准备主推基于 Redis 改造的 reborndb
Redis Cluster:
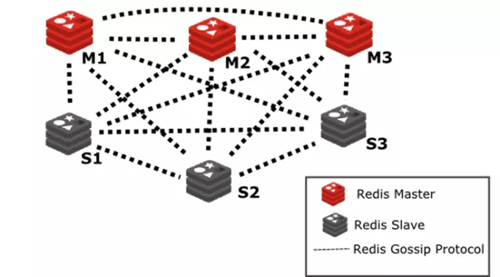
P2P模式,无中心化。把 key 分成 16384 个 slot,每个实例负责一部分 slot。客户端请求若不在连接的实例,该实例会转发给对应的实例。通过Gossip协议同步节点信息。
优点:
- 组件 all-in-box,部署简单,节约机器资源
- 性能比 proxy 模式好
- 自动故障转移、Slot 迁移中数据可用
- 官方原生集群方案,更新与支持有保障
缺点:
- 架构比较新,***实践较少
- 多键操作支持有限(驱动可以曲线救国)
- 为了性能提升,客户端需要缓存路由表信息
- 节点发现、reshard 操作不够自动化
二、Redis 通用
1:Redis 相对 MySQL、PostgreSQL 这些关系型数据库,有什么优缺点?
观点一:
Redis 主要是用来做缓存,它有持久化,但也只是为了缓存的可靠而已。优点是数据全放内存,速度快。缺点就是,数据大小不能超过内存大小。两个用在不同业务场景,Redis 无法取代传统关系型数据库。
观点二:
Redis 首先它是一种内存数据库,***的优势在于效率高。尤其在某些特定场合下,例如热点数据量非常大,而数据从内存和磁盘之间的换入换出代价比较高的情况下,Redis 就会体现它的价值。
传统关系型数据库在于它对数据的一致性保障,它的数据模型范式是遵循严格事务规则的结构化数据,由于其数据的高度抽象化,它调度到内存的数据一般场合下不会占用很大的内存空间。
总的来说,两种数据库各有各的优点和缺点。不同的业务场合有特定的追求目标,redis 首要的是效率,适用的是一些单纯二维结构化数据无法表达的数据模型,而关系型数据库处理的是可以用范式模型表达的二维数据,追求的是数据的高度一致性。随着 IT 的发展,每一类型的数据库都会在其特定的场合内发挥出无可比拟的优势,最终的趋势是大家趋于平衡,没有***,只有最适合。
观点三:
记住一句话:任何数据库都有自己的应用场景,应该关注数据流、数据属性。
个人的经验来说,Redis 不可能取代 MySQL 或者 PG。
2:Redis 有哪些应用场景,是否可以举例说明下哪个公司用了?
Redis 是一个高性能的缓存,一般应用在 Session 缓存、队列、排行榜、计数器、最近最热文章、最近最热评论、发布订阅等。
更多应用场景,可以参考此处。
可以这样讲,Redis 适用于 数据实时性要求高、数据存储有过期和淘汰特征的、不需要持久化或者只需要保证弱一致性、逻辑简单的场景。
国内的互联网公司,据我了解,基本是都在用,其中新浪对 Redis 在国内普及起了重要的作用。
另外,Redis 官网有「Who's using Redis?」的链接。
3:新接手一个复杂的 Redis 集群(Sentinel 模式),如何了解它
刚刚接手一套 Redis 集群,想要了解这套集群的相关配置。应该如何入手。难道只能通过 info 命令去查看各个配置吗?
这是笔者的建议:
- 通读 Sentinel 官方文档:https://redis.io/topics/sentinel
- Google 搜索 Redis Sentinel,找几篇中英文的文章看看
- 进入 Sentinel 集群后,使用 info 查看集群信息
- 查看 Sentinel 配置文件,配合文档搞清楚每个参数的含义
- 使用几台虚拟机模拟线上环境,然后做测试,在实践中深入理解
- 思考当前 Sentinel 集群是否有不合理的地方,如有,提出并改进
三、Redis 故障排查
1:Redis 实例中,存在大量的 FIN_WAIT2 连接
客户端 TCP 状态迁移:
CLOSED->SYN_SENT->ESTABLISHED->FIN_WAIT_1->FIN_WAIT_2->TIME_WAIT->CLOSED
服务器 TCP 状态迁移:
CLOSED->LISTEN->SYN 收到 ->ESTABLISHED->CLOSE_WAIT->LAST_ACK->CLOSED
这个状态存在于主动发起断开请求的一端,如果服务器存在大量的这个状态,那么这个服务器就充当客户端的角色,如网络爬虫,出现的原因是由于客户端发起 FIN 请求结束连接之后,收到了服务端的应答之后进入 FIN_WAIT2,之后就没收到服务端发送的 FIN 信号导致。
PS:线上 Web 客户端用的什么语言?
此问题的评论值得一看:http://www.aixchina.net/Question/231035-1406575
2:如何知道,当前 Redis 实例是处于阻塞状态?
请问大神们, 通过什么方式,能够知道,当前某个 Redis 实例是处于阻塞状态啊? 能不能通过某个命令查询出来 ? 求解, 谢谢!
解答一:
随便 get 一个 key,然后卡着不动就行,简单粗暴。优雅一点是看 latency 的延迟,blocked_clients 的数量,rejected_connections 的数量等。
解答二:
方法一:登录 Redis,执行 info,查看 blocked_clients
方法二:执行 redis-cli --latency -h -p 查看延时情况
3:Redis 运维的故障有哪些?
回答一:
常见的运维故障
- 使用 keys * 把库堵死,——建议使用别名把这个命令改名
- 超过内存使用后,部分数据被删除——这个有删除策略的,选择适合自己的即可
- 没开持久化,却重启了实例,数据全掉——记得非缓存的信息需要打开持久化
- RDB 的持久化需要 vm.overcommit_memory=1,否则会持久化失败
- 没有持久化情况下,主从,主重启太快,从还没认为主挂的情况下,从会清空自己的数据——人为重启主节点前,先关闭从节点的同步
回答二:
- 我简单说下 Redis 故障的排查方法吧。
- 了解清楚业务数据流是怎么样的
- 结合 Redis 监控查看 QPS、缓存***率、内存使用率等信息
- 确认机器层面的资源是否有异常
- 故障时及时上机,使用 redis-cli monitor 打印出操作日志,然后分析(事后分析此条失效)
- 和研发沟通,确认是否有大 Key 在堵塞(大 Key 也可以在日常的巡检中获得)
- 和组内同事沟通,确实是否有误操作
- 和运维同事、研发一起排查流量是否正常,是否存在被刷的情况
更多的排查需要对线上系统的分析。
四、Redis 性能优化
1:提高 Redis 内存数据库的性能,有哪些措施?
这个问题有点偏题了,还是回答下吧。整理下工作中积累的经验:
- 根据不同业务选择数据类型,有必要时对数据结构进行审核,减少数据冗余
- 精简键名和键值,控制键值的大小
- 使用前缀管理好 key
- 使用 scan 代替 keys,将遍历 Redis DB 中所有 key 的操作放到客户端来做
- 避免使用 O(N) 复杂度的命令
- 配置使用 ziplist 来优化 list
- 合理配置 maxmemory
- 数据量大的情况,做好 key 和 value 的压缩
- 利用管道,批量处理命令
- 根据不同业务选择短链接或者长链接
- 定期使用 redis-cli --big-keys 检测大 Key