随着银行业务的拓展以及网点业务的需求量加大,在新一轮技术浪潮驱动下,各大商业银行也在纷纷推进智能网点的建设。其中,商业银行的柜面无纸化就是***推进的业务之一。
包括广发银行、民生银行在内的大型商业银行,已经于近几年陆续上线柜面无纸化业务,并开始在全国网点进行推广使用。今后,随着柜面无纸化、“一站式”综合店员、人工智能等系统的陆续应用,各大商业银行也将全面实现网点智能化转型建设。
大型商业银行,平均有超过300~400个业务系统,每一个业务系统既有完整技术栈,又和不同的业务之间存在许多的相互依赖和相关的关系,业务和技术复杂度远超其他行业。此外,银行对于平台可靠性要求最为严苛,核心数据需保证0丢失、0错误率,核心业务系统也有“5个9”以上的稳定性要求。这些要求给后台数据库带来了极大的要求,因此业界也戏称银行是企业级数据库的“试金石”。
“无纸化”业务作为商业银行的新一代应用业务,对于数据管理带来了新的挑战。针对银行在新一代柜面无纸化业务上的痛点需求,巨杉数据库在保证稳定安全的基础上,利用其所支持的非结构化存储、结构化事务、可弹性扩张、高可用、以及多数据中心灾备等能力,全面支持广发、民生银行的柜面无纸化业务,为业务带来巨大提升。
巨杉数据库分布式双活部署整体示意图
非结构化数据存储
作为一款分布式的交易型数据库,SequoiaDB数据库提供了同时存储结构和和非结构化引擎的机制,非结构化数据的存储在引擎中主要是以 LOB形式来实现的。SequoiaDB 3.0在对象存储API的基础之上提供了标准Posix文件系统接口,能够原生接入任何支持Posix协议标准的操作系统,用户对应用程序无需任何改造即可从NAS迁移至SequoiaDB。
在巨杉数据库中,LOB大对象存储引擎可将各种尺寸的非结构化文件切分成小存储块,按散列映射存放于集群的多个数据组,实现文件的高效并发存取,对外提供对象标识进行文件访问。
在巨杉数据库中,LOB存储结构分为元数据文件(lobm)与数据文件(lobd)。其中,元数据文件存储整个LOB数据文件的元数据模型,包括每个页的空闲状况、散列桶、以及数据映射表等一系列数据结构。而数据文件则存储用户真实数据,数据头之后所有数据页按照page size进行切分,每个数据页不包含任何元数据信息。

与结构化数据的记录引擎完全不同,巨杉数据库的非结构化存储提供了原生的对象文件块存储机制,同时适用于影像类大文件与票据类小文件。在巨杉数据库对小文件存储与检索的过程当中,每个数据块均使用散列算法判断其所处的物理位置,因此不会进行任何物理查表操作,数据库也不需要维护每个对象文件的物理位置表,因此不论从安全性、吞吐量、以及响应速度都远远高于其他同类对象存储。
多活与灾备
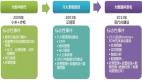
巨杉数据库的原生分布式架构,一方面提供了引擎级别的内部数据多副本和高可用以及基于Raft算法的数据一致性的保证。同时,在跨数据中心层面,可以做到分布式集群为单位的容灾和多活机制,在满足数据安全要求下减少了数据安全方面的部署和运维难度。
从多活架构的角度看,巨杉数据库都秉承着计算存储分离的设计思路,因此其SQL解析与执行器往往与数据存储和事务控制分别运行在不同的进程中。在这种情况下,利用数据库自身分布式与三副本复制的特性,将数据打散放置在多个数据中心内,每个数据中心配置本地SQL服务节点,从应用程序的角度看不需要关注底层数据库的主从架构,仅需要通过JDBC连接到本地的SQL服务节点进行读写操作即可。在这种架构下,每个SQL节点完全对等,并均可以处理读写操作。所有的事务控制、一致性控制、锁等待等机制都由底层的分布式数据库直接提供。
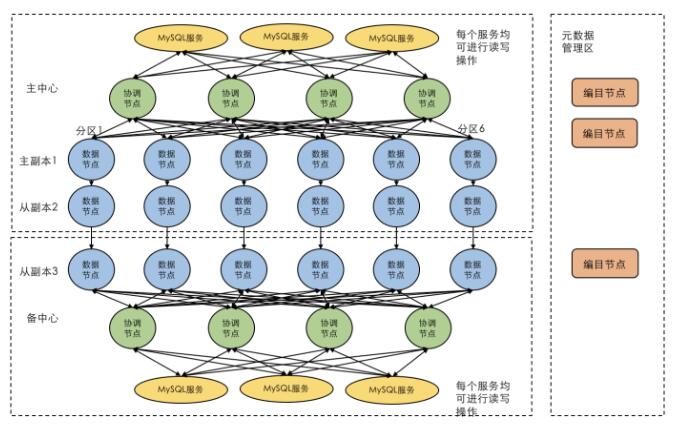
以两地三中心为例,在该架构中,城市A机房1作为主机房,提供与同城的机房2之间的同步数据复制。而对于城市B的机房来说,在带宽足够的情况下可以选择使用同步机制与城市A的机房进行数据复制。而在带宽不足时则可以选择异步的复制方式。
同时,巨杉也支持异地灾备机房的定期追加更新。用户可以通过定义异地灾备机房的同步策略,使灾备机房定期进行日志文件的同步,以做到灾备机房与主机房的数据拥有一定的时间差异,避免手工误操作。
高性能实时性能响应
通过分布式架构,多维数据分区,高性能索引,以及数据压缩等机制,影像平台无论非结构化数据还是结构化数据在大数据量下依旧保持性能的平滑扩展,实时响应。在性能测试对比中,对比巨杉数据库,传统NAS方案想要达到同样吞吐量至少需要3倍以上的磁盘数量。
以下是巨杉数据库在实际测试环境中,对于非结构化数据管理这块的测试数据:
- 2GB/s的整体吞吐量,分布式架构
- 6节点x86服务器、整个集群共36块SAS盘
- 传统方案,高端配置:1.5GB/s 120块盘以上
- 100%写入场景
|
吞吐量(MB/秒) |
50KB |
200KB |
1MB |
10MB |
|
整个集群(6节点) |
353.3 |
1232.8 |
2223.3 |
2077.5 |
|
平均单物理节点 |
58.9 |
205.5 |
370.5 |
346.3 |
|
数据写入平均时延(ms) |
14 |
16 |
44 |
466 |
- 100%读取场景
|
吞吐量(MB/秒) |
50KB |
200KB |
1MB |
10MB |
|
整个集群(6节点) |
352.9 |
1225.1 |
2410.9 |
2653.3 |
|
平均单物理节点 |
58.8 |
204.2 |
401.8 |
442.2 |
|
数据写入平均时延(ms) |
14 |
16 |
41 |
369 |
- 混合业务场景
|
吞吐量(MB/秒) |
50KB |
200KB |
1MB |
10MB |
|
整个集群(6节点) |
363.7 |
1266.0 |
1872.8 |
2323.8 |
|
平均单物理节点 |
60.6 |
211.0 |
312.1 |
387.3 |
|
数据写入平均时延(ms) |
写:14 读:16 |
写:14 读:15 |
写:35 读:106 |
写:293 读:749 |
巨杉数据库为底层数据引擎的分布式非结构化数据管理平台,已经在包括民生银行、广发银行在内的超过50家大型银行业务应用。在某大型股份制商业银行业务系统中,巨杉数据库总集群部署节点数达到122台物理服务器,部署逻辑节点1530个,平台服务银行网点数超过840个 ,性能响应在毫秒级别,数据实现了同城数据中心灾备和双活。