












挑战
随着数据量的快速增长,越来越多的企业迎来业务数据化时代,数据成为了最重要的生产资料和业务升级依据。伴随着业务对海量数据实时分析的需求越来越多,数据分析技术这两年也迎来了一些新的挑战和变革:
- 在线化和高可用,离线和在线的边界越来越模糊,一切数据皆服务化、一切分析皆在线化。
- 高并发低延时,越来越多的数据系统直接服务终端客户,对系统的并发和处理延时提出了新的交互性挑战。
- 混合负载, 一套实时分析系统既要支持数据加工处理,又要支持高并发低延时的交互式查询。
- 融合分析, 随着对数据新的使用方式探索,需要解决结构化与非结构化数据融合场景下的数据检索和分析问题。
阿里巴巴最初通过单节点Oracle进行准实时分析, 后来转到Oracle RAC,随着业务的飞速发展, 集中式的Shared Storage架构需要快速转向分布式,迁移到了Greenplum,但不到一年时间便遇到扩展性和并发的严重瓶颈。为了迎接更大数据集、更高并发、更高可用、更实时的数据应用发展趋势,从2011年开始,在线分析这个技术领域,阿里实时数仓坚定的走上了自研之路。
分析型数据库AnalyticDB
AnalyticDB是阿里巴巴自主研发、唯一经过超大规模以及核心业务验证的PB级实时数据仓库。自2012年第一次在集团发布上线以来,至今已累计迭代发布近百个版本,支撑起集团内的电商、广告、菜鸟、文娱、飞猪等众多在线分析业务。
AnalyticDB于2014年在阿里云开始正式对外输出,支撑行业既包括传统的大中型企业和政府机构,也包括众多的互联网公司,覆盖外部十几个行业。AnalyticDB承接着阿里巴巴广告营销、商家数据服务、菜鸟物流、盒马新零售等众多核心业务的高并发分析处理, 每年双十一上述众多实时分析业务高峰驱动着AnalyticDB不断的架构演进和技术创新。
经过这2年的演进和创新,AnalyticDB已经成长为兼容MySQL 5.x系列、并在此基础上增强支持ANSI SQL:2003的OLAP标准(如window function)的通用实时数仓,跻身为实时数仓领域极具行业竞争力的产品。近期,AnalyticDB成功入选了全球权威IT咨询机构Forrester发布"The Forrester Wave™: CloudData Warehouse,Q4 2018"研究报告的Contenders象限,以及Gartner发布的分析型数据管理平台报告 (Magic Quadrant forData Management Solutions for Analytics),开始进入全球分析市场。AnalyticDB旨在帮客户将整个数据分析和价值化从传统的离线分析带到下一代的在线实时分析模式。
整体架构
经过过去2年的架构演进和功能迭代,AnalyticDB当前整体架构如下图。
AnalyticDB是一个支持多租户的Cloud Native Realtime Data Warehouse平台,每个租户DB的资源隔离,每个DB都有相应独立的模块(图中的Front Node, Compute Node, Buffer Node),在处理实时写入和查询时,这些模块都是资源(CPU, Memory)使用密集型的服务,需要进行DB间隔离保证服务质量。同时从功能完整性和成本优化层面考虑,又有一系列集群级别服务(图中绿色部分模块)。
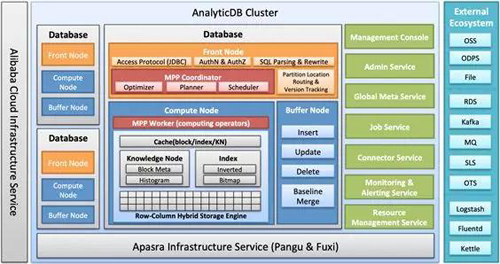
下面是对每个模块的具体描述:
DB级别服务组件:
- Front Node:负责JDBC, ODBC协议层接入,认证和鉴权,SQL解析、重写;分区地址路由和版本管理;同时优化器,执行计划和MPP计算的调度模块也在Front Node。
- Compute Node: 包含MPP计算Worker模块,和存储模块(行列混存,元数据,索引)。
- Buffer Node: 负责实时写入,并根据实时数据大小触发索引构建和合并。
集群级别服务组件:
- Management Console: 管理控制台。
- Admin Service:集群管控服务,负责计量计费,实例生命周期管理等商业化功能,同时提供OpenAPI和InnerAPI给Management Console和第三方调用。
- Global Meta Service:全局元数据管理,提供每个DB的元数据管理服务,同时提供分区分配,副本管理,版本管理,分布式DDL等能力。
- Job Service:作业服务,提供异步作业调度能力。异步作业包括索引构建、扩容、无缝升级、删库删表的后台异步数据清理等。
- Connector Service:数据源连接服务,负责外部各数据源(图中右侧部分)接入到AnalyticDB。目前该服务开发基本完成,即将上线提供云服务。
- Monitoring & Alerting Service:监控告警诊断服务,既提供面向内部人员的运维监控告警诊断平台,又作为数据源通过Management Console面向用户侧提供数据库监控服务。
- Resource Management Service:资源管理服务,负责集群级别和DB级别服务的创建、删除、DNS/SLB挂载/卸载、扩缩容、升降配,无缝升级、服务发现、服务健康检查与恢复。
数据模型
AnalyticDB中表组(Table Group)分为两类:事实表组和维度表组。
- 事实表组(Fact Table Group),表组在AnalyticDB里是一个逻辑概念,用户可以将业务上关联性比较多的事实表放在同一个事实表组下,主要是为了方便客户做众多数据业务表的管理,同时还可以加速Co-location Join计算。
- 维度表组(Dimension Table Group),用于存放维度表,目前有且仅有一个,在数据库建立时会自动创建,维度表特征上是一种数据量较小但是需要和事实表进行潜在关联的表。
AnalyticDB中表分为事实表(Fact Table)和维度表(Dimension Table)。
事实表创建时至少要指定Hash分区列和相关分区信息,并且指定存放在一个表组中,同时支持List二级分区。
- Hash Partition将数据按照分区列进行hash分区,hash分区被分布到多个Compute Node中。
- List Partition(如果指定List分区列的话)对一个hash分区进行再分区,一般按照时间(如每天一个list分区)。
- 一个Hash Partition的所有List Partition默认存放于同一个Compute Node中。每个Hash Partition配有多个副本(通常为双副本),分布在不同的Compute Node中,做到高可用和高并发。
维度表可以和任意表组的任意表进行关联,并且创建时不需要配置分区信息,但是对单表数据量大小有所限制,并且需要消耗更多的存储资源,会被存储在每个属于该DB的Compute Node中。
下图描述了从Database到List分区到数据模型:
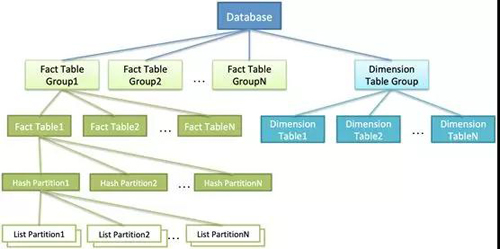
对于Compute Node 来说,事实表的每个List分区是一个物理存储单元(如果没有指定List分区列,可认为该Hash分区只有一个List分区)。一个分区物理存储单元采用行列混存模式,配合元数据和索引,提供高效查询。
海量数据
基于上述数据模型,AnalyticDB提供了单库PB级数据实时分析能力。以下是生产环境的真实数据:
- 阿里巴巴集团某营销应用单DB表数超过20000张
- 云上某企业客户单DB数据量近3PB,单日分析查询次数超过1亿
- 阿里巴巴集团内某单个AnalyticDB集群超过2000台节点规模
- 云上某业务实时写入压力高达1000w TPS
- 菜鸟网络某数据业务极度复杂分析场景,查询QPS 100+
导入导出
灵活的数据导入导出能力对一个实时数仓来说至关重要,AnalyticDB当前既支持通过阿里云数据传输服务DTS、DataWorks数据集成从各种外部数据源导入入库,同时也在不断完善自身的数据导入能力。整体导入导出能力如下图(其中导入部分数据源当前已支持,部分在开发中,即将发布)。
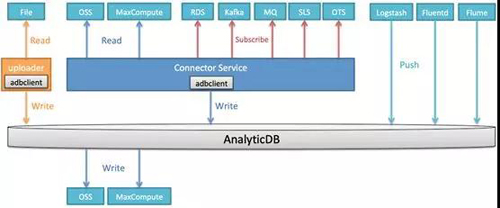
数据导入
首先,由于AnalyticDB兼容MySQL5.x系列,支持通过MySQL JDBC方式把数据insert入库。为了获得最佳写入性能,AnalyticDB提供了Client SDK,实现分区聚合写的优化,相比通过JDBC单条insert,写入性能有10倍以上提升。对于应用端业务逻辑需要直接写入AnalyticDB的场景,推荐使用AnalyticDB Client SDK。
同时,对于快速上传本地结构化的文本文件,可以使用基于AnalyticDB Client SDK开发的Uploader工具。对于特别大的文件,可以拆分后使用uploader工具进行并行导入。
另外,对于OSS,MaxCompute这样的外部数据源,AnalyticDB通过分布式的Connector Service数据导入服务并发读取并写入到相应DB中。Connector Service还将支持订阅模式,从Kafka,MQ,RDS等动态数据源把数据导入到相应DB中。AnalyticDB对大数据生态的Logstash,Fluentd,Flume等日志收集端、ETL工具等通过相应插件支持,能够快速把数据写入相应DB。
今天在阿里巴巴集团内,每天有数万张表从MaxCompute导入到AnalyticDB中进行在线分析,其中大量导入任务单表数据大小在TB级、数据量近千亿。
数据导出
AnalyticDB目前支持数据导出到OSS和MaxCompute,业务场景主要是把相应查询结果在外部存储进行保存归档,实现原理类似insert from select操作。insert from select是把查询结果写入到内部表,而导出操作则是写入外部存储, 通过改进实现机制,可以方便地支持更多的导出数据源。
核心技术
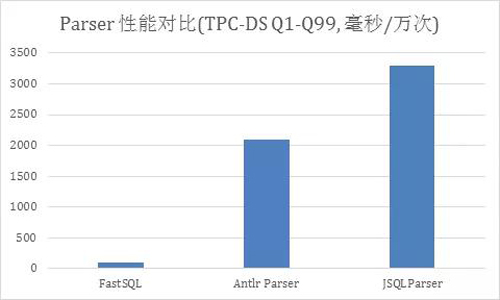
高性能SQL Parser
AnalyticDB经过数年的发展,语法解析器也经历了多次更新迭代。曾经使用过业界主流的 Antlr(http://www.antlr.org),JavaCC(https://javacc.org)等Parser生成器作为SQL 语法解析器,但是两者在长期、大规模、复杂查询场景下,Parser的性能、语法兼容、API设计等方面不满足要求,于是我们引入了自研的SQL Parser组件FastSQL。
领先业界的Parser性能
AnalyticDB主打的场景是高并发、低延时的在线化分析,对SQL Parser性能要求很高,批量实时写入等场景要求更加苛刻。FastSQL通过多种技术优化提升Parser性能,例如:
- 快速对比:使用64位hash算法加速关键字匹配,使用fnv_1a_64 hash算法,在读取identifier的同时计算好hash值,并利用hash64低碰撞概率的特点,使用64位hash code直接比较,比常规Lexer先读取identifier,在查找SymbolTable速度更快。
- 高性能的数值Parser:Java自带的Integer.parseInt()/Float.parseFloat()需要构造字符串再做parse,FastSQL改进后可以直接在原文本上边读取边计算数值。
- 分支预测:在insert values中,出现常量字面值的概率比出现其他的token要高得多,通过分支预测可以减少判断提升性能。
以TPC-DS99个Query对比来看,FastSQL比Antlr Parser(使用Antlr生成)平均快20倍,比JSQLParser(使用JavaCC生成)平均快30倍,在批量Insert场景、多列查询场景下,使用FastSQL后速度提升30~50倍。
无缝结合优化器
在结合AnalyticDB的优化器的SQL优化实践中,FastSQL不断将SQL Rewrite的优化能力前置化到SQL Parser中实现,通过与优化器的SQL优化能力协商,将尽可能多的表达式级别优化前置化到SQL Parser中,使得优化器能更加专注于基于代价和成本的优化(CBO,Cost-Based Optimization)上,让优化器能更多的集中在理解计算执行计划优化上。FastSQL在AST Tree上实现了许多SQL Rewrite的能力,例如:
- 常量折叠:
- SELECT * FROM t1 t
- WHERE comm_week
- BETWEEN CAST(date_format(date_add('day',-day_of_week('20180605'),
- date('20180605')),'%Y%m%d') AS bigint)
- AND CAST(date_format(date_add('day',-day_of_week('20180605')
- ,date('20180605')),'%Y%m%d') AS bigint)
- ------>
- SELECT * FROM t1 t
- WHERE comm_week BETWEEN20180602AND20180602
- 函数变换:
- SELECT * FROM t1 t
- WHERE DATE_FORMAT(t."pay_time",'%Y%m%d')>='20180529'
- AND DATE_FORMAT(t."pay_time",'%Y%m%d')<='20180529'
- ------>
- SELECT * FROM t1 t
- WHERE t."pay_time">= TIMESTAMP'2018-05-29 00:00:00'
- AND t."pay_time"< TIMESTAMP'2018-05-30 00:00:00'
- 表达式转换:
- SELECT a, b FROM t1
- WHERE b +1=10;
- ------>
- SELECT a, b FROM t1
- WHERE b =9;
- 函数类型推断:
- -- f3类型是TIMESTAMP类型
- SELECT concat(f3,1)
- FROM nation;
- ------>
- SELECT concat(CAST(f3 AS CHAR),'1')
- FROM nation;
- 常量推断:
- SELECT * FROM t
- WHERE a < b AND b = c AND a =5
- ------>
- SELECT * FROM t
- WHERE b >5AND a =5AND b = c
- 语义去重:
- SELECT * FROM t1
- WHERE max_adate >'2017-05-01'
- AND max_adate !='2017-04-01'
- ------>
- SELECT * FROM t1
- WHERE max_adate > DATE '2017-05-01'
玄武存储引擎
为保证大吞吐写入,以及高并发低时延响应,AnalyticDB自研存储引擎玄武,采用多项创新的技术架构。玄武存储引擎采用读/写实例分离架构,读节点和写节点可分别独立扩展,提供写入吞吐或者查询计算能力。在此架构下大吞吐数据写入不影响查询分析性能。同时玄武存储引擎构筑了智能全索引体系,保证绝大部分计算基于索引完成,保证任意组合条件查询的毫秒级响应。
读写分离架构支持大吞吐写入
传统数据仓库并没有将读和写分开处理,即这些数据库进程/线程处理请求的时候,不管读写都会在同一个实例的处理链路上进行。因此所有的请求都共享同一份资源(内存资源、锁资源、IO资源),并相互影响。在查询请求和写入吞吐都很高的时候,会存在严重的资源竞争,导致查询性能和写入吞吐都下降。
为了解决这个问题,玄武存储引擎设计了读写分离的架构。如下图所示,玄武存储引擎有两类关键的节点:Buffer Node和Compute Node。Buffer Node专门负责处理写请求,Compute Node专门负责查询请求,Buffer Node和Compute Node完全独立并互相不影响,因此,读写请求会在两个完全不相同的链路中处理。上层的Front Node会把读写请求分别路由给Buffer Node和Compute Node。
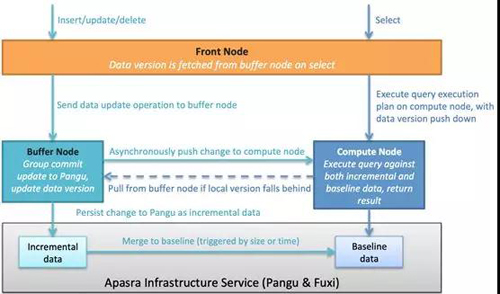
实时写入链路:
- 业务实时数据通过JDBC/ODBC协议写入到Front Node。
- Front Node根据实时数据的hash分区列值,路由到相应Buffer Node。
- Buffer Node将该实时数据的内容(类似于WAL)提交到盘古分布式文件系统,同时更新实时数据版本,并返回Front Node,Front Node返回写入成功响应到客户端。
- Buffer Node同时会异步地把实时数据内容推送到Compute Node,Compute Node消费该实时数据并构建实时数据轻量级索引。
- 当实时数据积攒到一定量时,Buffer Node触发后台Merge Baseline作业,对实时数据构建完全索引并与基线数据合并。
实时查询链路:
- 业务实时查询请求通过JDBC/ODBC协议发送到Front Node。
- Front Node首先从Buffer Node拿到当前最新的实时数据版本,并把该版本随执行计划一起下发到Compute Node。
- Compute Node检查本地实时数据版本是否满足实时查询要求,若满足,则直接执行并返回数据。若不满足,需先到Buffer Node把指定版本的实时数据拖到本地,再执行查询,以保证查询的实时性(强一致)。
AnalyticDB提供强实时和弱实时两种模式,强实时模式执行逻辑描述如上。弱实时模式下,Front Node查询请求则不带版本下发,返回结果的实时取决于Compute Node对实时数据的处理速度,一般有秒极延迟。所以强实时在保证数据一致性的前提下,当实时数据写入量比较大时对查询性能会有一定的影响。
高可靠性
玄武存储引擎为Buffer Node和Compute Node提供了高可靠机制。用户可以定义Buffer Node和Compute Node的副本数目(默认为2),玄武保证同一个数据分区的不同副本一定是存放在不同的物理机器上。Compute Node的组成采用了对等的热副本服务机制,所有Compute Node节点都可以参与计算。另外,Computed Node的正常运行并不会受到Buffer Node节点异常的影响。如果Buffer Node节点异常导致Compute Node无法正常拉取最新版本的数据,Compute Node会直接从盘古上获取数据(即便这样需要忍受更高的延迟)来保证查询的正常执行。数据在Compute Node上也是备份存储。如下图所示,数据是通过分区存放在不同的ComputeNode上,具有相同hash值的分区会存储在同一个Compute Node上。数据分区的副本会存储在其他不同的Compute Node上,以提供高可靠性。

高扩展性
玄武的两个重要特性设计保证了其高可扩展性:1)Compute Node和Buffer Node都是无状态的,他们可以根据业务负载需求进行任意的增减;2)玄武并不实际存储数据,而是将数据存到底层的盘古系统中,这样,当Compute Node和Buffer Node的数量进行改变时,并不需要进行实际的数据迁移工作。
为计算而生的存储
数据存储格式
传统关系型数据库一般采用行存储(Row-oriented Storage)加B-tree索引,优势在于其读取多列或所有列(SELECT *)场景下的性能,典型的例子如MySQL的InnoDB引擎。但是在读取单列、少数列并且行数很多的场景下,行存储会存在严重的读放大问题。
数据仓库系统一般采用列存储(Column-oriented Storage),优势在于其单列或少数列查询场景下的性能、更高的压缩率(很多时候一个列的数据具有相似性,并且根据不同列的值类型可以采用不同的压缩算法)、列聚合计算(SUM, AVG, MAX, etc.)场景下的性能。但是如果用户想要读取整行的数据,列存储会带来大量的随机IO,影响系统性能。
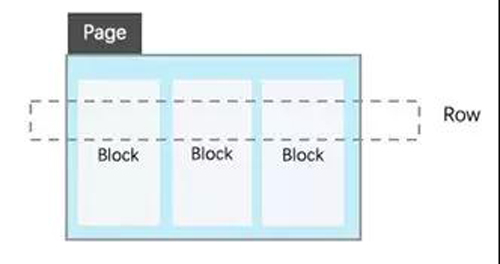
为了发挥行存储和列存储各自的优势,同时避免两者的缺点,AnalyticDB设计并实现了全新的行列混存模式。如下图所示:
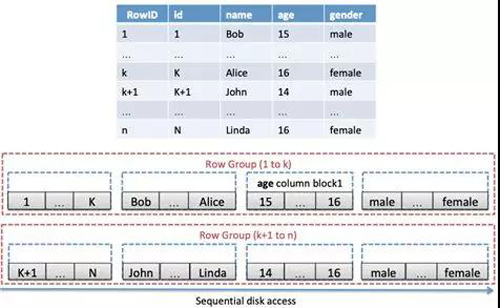
- 对于一张表,每k行数据组成一个Row Group。在每个Row Group中,每列数据连续的存放在单独的block中,每Row Group在磁盘上连续存放。
- Row Group内列block的数据可按指定列(聚集列)排序存放,好处是在按该列查询时显著减少磁盘随机IO次数。
- 每个列block可开启压缩。
行列混存存储相应的元数据包括:分区元数据,列元数据,列block元数据。其中分区元数据包含该分区总行数,单个block中的列行数等信息;列元数据包括该列值类型、整列的MAX/MIN值、NULL值数目、直方图信息等,用于加速查询;列block元数据包含该列在单个Row Group中对应的MAX/MIN/SUM、总条目数(COUNT)等信息,同样用于加速查询。
全索引计算
用户的复杂查询可能会涉及到各种不同的列,为了保证用户的复杂查询能够得到秒级响应,玄武存储引擎在行列混合存储的基础上,为基线数据(即历史数据)所有列都构建了索引。玄武会根据列的数据特征和空间消耗情况自动选择构建倒排索引、位图索引或区间树索引等,而用的最多的是倒排索引。
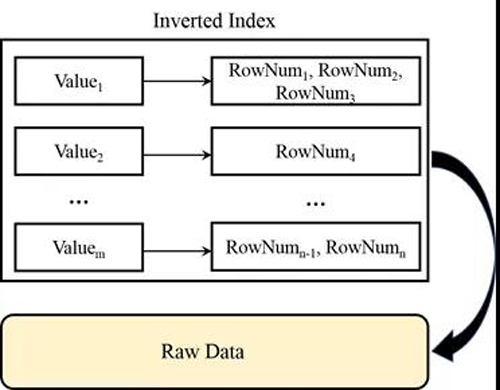
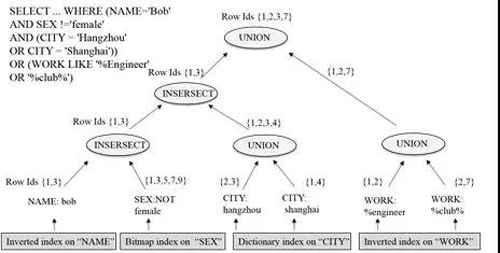
如上图所示,在倒排索引中,每列的数值对应索引的key,该数值对应的行号对应索引的value,同时所有索引的key都会进行排序。依靠全列索引,交集、并集、差集等数据库基础操作可以高性能地完成。如下图所示,用户的一个复杂查询包含着对任意列的条件筛选。玄武会根据每个列的条件,去索引中筛选满足条件的行号,然后再将每列筛选出的行号,进行交、并、差操作,筛选出最终满足所有条件的行号。玄武会依据这些行号去访问实际的数据,并返回给用户。通常经过筛选后,满足条件的行数可能只占总行数的万分之一到十万分之一。因此,全列索引帮助玄武在执行查询请求的时候,大大减小需要实际遍历的行数,进而大幅提升查询性能,满足任意复杂查询秒级响应的需求。
使用全列索引给设计带来了一个很大挑战:需要对大量数据构建索引,这会是一个非常耗时的过程。如果像传统数据库那样在数据写入的路径上进行索引构建,那么这会严重影响写入的吞吐,而且会严重拖慢查询的性能,影响用户体验。为了解决这个挑战,玄武采用了异步构建索引的方式。当写入请求到达后,玄武把写SQL持久化到盘古,然后直接返回,并不进行索引的构建。
当这些未构建索引的数据(称为实时数据)积累到一定数量时,玄武会开启多个MapReduce任务,来对这些实时数据进行索引的构建,并将实时数据及其索引,同当前版本的基线数据(历史数据)及其索引进行多版本归并,形成新版本的基线数据和索引。这些MapReduce任务通过伏羲进行分布式调度和执行,异步地完成索引的构建。这种异步构建索引的方式,既不影响AnalyticDB的高吞吐写入,也不影响AnalyticDB的高性能查询。
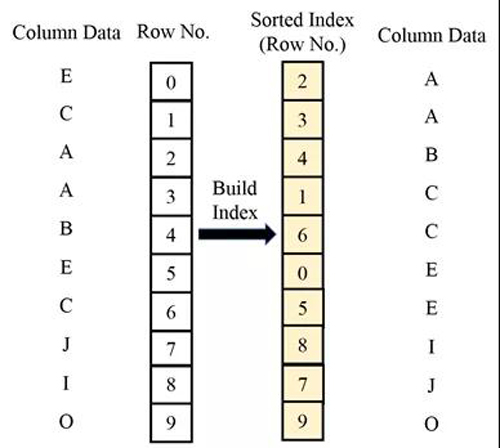
异步构建索引的机制还会引入一个新问题:在进行MapReduce构建索引的任务之前,新写入的实时数据是没有索引的,如果用户的查询会涉及到实时数据,查询性能有可能会受到影响。玄武采用为实时数据构建排序索引(Sorted Index)的机制来解决这个问题。
如下图所示,玄武在将实时数据以block形式刷到磁盘之前,会根据每一列的实时数据生成对应的排序索引。排序索引实际是一个行号数组,对于升序排序索引来说,行号数组的第一个数值是实时数据最小值对应的行号,第二个数值是实时数据第二小值对应的行号,以此类推。这种情况下,对实时数据的搜索复杂度会从O(N)降低为O(lgN)。排序索引大小通常很小(60KB左右),因此,排序索引可以缓存在内存中,以加速查询。
羲和计算引擎
针对低延迟高并发的在线分析场景需求,AnalyticDB自研了羲和大规模分析引擎,其中包括了基于流水线模型的分布式并行计算引擎,以及基于规则 (Rule-Based Optimizer,RBO) 和代价(Cost-Based Optimizer,CBO)的智能查询优化器。
优化器
优化规则的丰富程度是能否产生最优计划的一个重要指标。因为只有可选方案足够多时,才有可能选到最优的执行计划。AnalyticDB提供了丰富的关系代数转换规则,用来确保不会遗漏最优计划。
基础优化规则:
- 裁剪规则:列裁剪、分区裁剪、子查询裁剪
- 下推/合并规则:谓词下推、函数下推、聚合下推、Limit下推
- 去重规则:Project去重、Exchange去重、Sort去重
- 常量折叠/谓词推导
探测优化规则:
- Joins:BroadcastHashJoin、RedistributedHashJoin、NestLoopIndexJoin
- Aggregate:HashAggregate、SingleAggregate
- JoinReordering
- GroupBy下推、Exchange下推、Sort下推
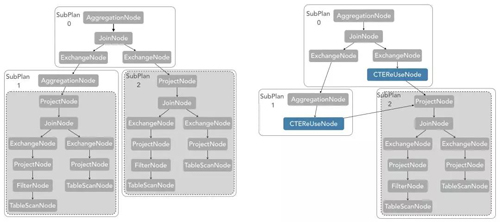
高级优化规则:CTE
例如下图中,CTE的优化规则的实现将两部分相同的执行逻辑合为一个。通过类似于最长公共子序列的算法,对整个执行计划进行遍历,并对一些可以忽略的算子进行特殊处理,如Projection,最终达到减少计算的目的。
单纯基于规则的优化器往往过于依赖规则的顺序,同样的规则不同的顺序会导致生成的计划完全不同,结合基于代价的优化器则可以通过尝试各种可能的执行计划,达到全局最优。
AnalyticDB的代价优化器基于Cascade模型,执行计划经过Transform模块进行了等价关系代数变换,对可能的等价执行计划,估算出按Cost Model量化的计划代价,并从中最终选择出代价最小的执行计划通过Plan Generation模块输出,存入Plan Cache(计划缓存),以降低下一次相同查询的优化时间。
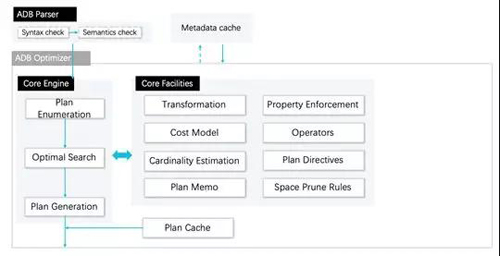
在线分析的场景对优化器有很高的要求,AnalyticDB为此开发了三个关键特性:存储感知优化、动态统计信息收集和计划缓存。
存储层感知优化
生成分布式执行计划时,AnalyticDB优化器可以充分利用底层存储的特性,特别是在Join策略选择,Join Reorder和谓词下推方面。
- 底层数据的哈希分布策略将会影响Join策略的选择。基于规则的优化器,在生成Join的执行计划时,如果对数据物理分布特性的不感知,会强制增加一个数据重分布的算子来保证其执行语义的正确。 数据重分布带来的物理开销非常大,涉及到数据的序列化、反序列化、网络开销等等,因此避免多次数据重分布对于分布式计算是非常重要的。除此之外,优化器也会考虑对数据库索引的使用,进一步减少Join过程中构建哈希的开销。
- 调整Join顺序时,如果大多数Join是在分区列,优化器将避免生成Bushy Tree,而更偏向使用Left Deep Tree,并尽量使用现有索引进行查找。
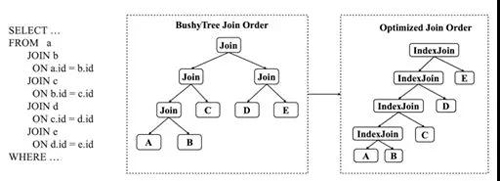
- 优化器更近一步下推了谓词和聚合。聚合函数,比如count(),和查询过滤可以直接基于索引计算。
所有这些组合降低了查询延迟,同时提高集群利用率,从而使得AnalyticDB能轻松支持高并发。
动态统计信息收集
统计信息是优化器在做基于代价查询优化所需的基本信息,通常包括有关表、列和索引等的统计信息。传统数据仓库仅收集有限的统计信息,例如列上典型的最常值(MFV)。商业数据库为用户提供了收集统计信息的工具,但这通常取决于DBA的经验,依赖DBA来决定收集哪些统计数据,并依赖于服务或工具供应商。
上述方法收集的统计数据通常都是静态的,它可能需要在一段时间后,或者当数据更改达到一定程度,来重新收集。但是,随着业务应用程序变得越来越复杂和动态,预定义的统计信息收集可能无法以更有针对性的方式帮助查询。例如,用户可以选择不同的聚合列和列数,其组合可能会有很大差异。但是,在查询生成之前很难预测这样的组合。因此,很难在统计收集时决定正确统计方案。但是,此类统计信息可帮助优化器做出正确决定。
我们设计了一个查询驱动的动态统计信息收集机制来解决此问题。守护程序动态监视传入的查询工作负载和特点以提取其查询模式,并基于查询模式,分析缺失和有益的统计数据。在此分析和预测之上,异步统计信息收集任务在后台执行。这项工作旨在减少收集不必要的统计数据,同时使大多数即将到来的查询受益。对于前面提到的聚合示例,收集多列统计信息通常很昂贵,尤其是当用户表有大量列的时候。根据我们的动态工作负载分析和预测,可以做到仅收集必要的多列统计信息,同时,优化器能够利用这些统计数据来估计聚合中不同选项的成本并做出正确的决策。
计划缓存
从在线应用案件看,大多数客户都有一个共同的特点,他们经常反复提交类似的查询。在这种情况下,计划缓存变得至关重要。为了提高缓存命中率,AnalyticDB不使用原始SQL文本作为搜索键来缓存。相反,SQL语句首先通过重写并参数化来提取模式。例如,查询 “SELECT * FROM t1 WHERE a = 5 + 5”将转化为“SELECT * FROM t1 WHERE a =?”。参数化的SQL模版将被作为计划缓存的关键字,如果缓存命中,AnalyticDB将根据新查询进行参数绑定。由于这个改动,即使使用有限的缓存大小,优化器在生产环境也可以保持高达90%以上的命中率,而之前只能达到40%的命中率。
这种方法仍然有一个问题。假设我们在列a上有索引,“SELECT * FROM t1 WHERE a = 5”的优化计划可以将索引扫描作为其最佳访问路径。但是,如果新查询是“SELECT * FROM t1 WHERE a = 0”并且直方图告诉我们数值0在表t1占大多数,那么索引扫描可能不如全表扫描有效。在这种情况下,使用缓存中的计划并不是一个好的决定。为了避免这类问题,AnalyticDB提供了一个功能Literal Classification,使用列的直方图对该列的值进行分类,仅当与模式相关联的常量“5”的数据分布与新查询中常量“0”的数据分布类似时,才实际使用高速缓存的计划。否则,仍会对新查询执行常规优化。
执行引擎
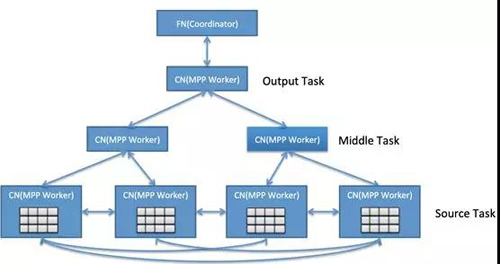
在优化器之下,AnalyticDB在MPP架构基础上,采用流水线执行的DAG架构,构建了一个适用于低延迟和高吞吐量工作负载的执行器。如下图所示,当涉及到多个表之间非分区列JOIN时,CN(MPP Worker)会先进行data exchange (shuffling)然后再本地JOIN (SourceTask),aggregate后发送到上一个stage(MiddleTask),最后汇总到Output Task。由于绝大多情况都是in-memory计算(除复杂ETL类查询,尽量无中间Stage 落盘)且各个stage之间都是pipeline方式协作,性能上要比MapReduce方式快一个数量级。
在接下来的几节中,将介绍其中三种特性,包括混合工作负载管理,CodeGen和矢量化执行。
混合工作负载管理
作为一套完备的实时数仓解决方案,AnalyticDB中既有需要较低响应时间的高并发查询,也有类似ETL的批处理,两者争用相同资源。传统数仓体系往往在这两个方面的兼顾性上做的不够好。
AnalyticDB worker接收coordinator下发的任务, 负责该任务的物理执行计划的实际执行。这项任务可以来自不同的查询, worker会将任务中的物理执行计划按照既定的转换规则转换成对应的operator,物理执行计划中的每一个Stage会被转换成一个或多个operator。
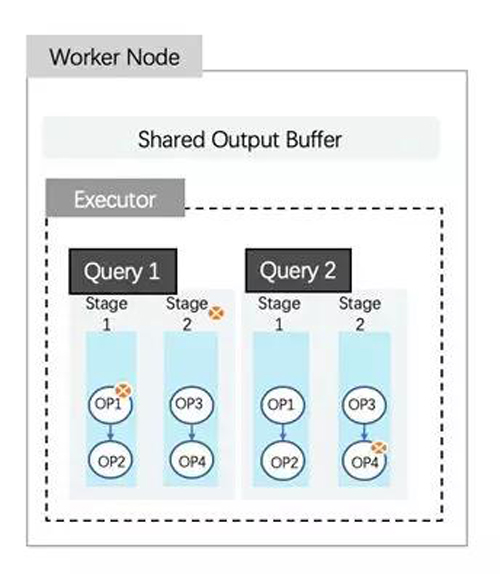
执行引擎已经可以做到stage/operator级别中断和Page级别换入换出,同时线程池在所有同时运行的查询间共享。但是,这之上仍然需要确保高优先级查询可以获得更多计算资源。
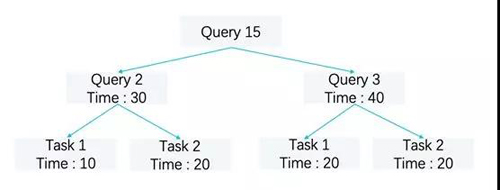
根据经验,客户总是期望他们的短查询即使当系统负载很重的时候也能快速完成。为了满足这些要求,基于以上场景,通过时间片的分配比例来体现不同查询的优先级,AnalyticDB实现了一个简单版本的类Linux kernel 的调度算法。系统记录了每一个查询的总执行耗时,查询总耗时又是通过每一个Task耗时来进行加权统计的,最终在查询层面形成了一颗红黑树,每次总是挑选最左侧节点进行调度,每次取出或者加入(被唤醒以及重新入队)都会重新更新这棵树,同样的,在Task被唤醒加入这颗树的时候,执行引擎考虑了补偿机制,即时间片耗时如果远远低于其他Task的耗时,确保其在整个树里面的位置,同时也避免了因为长时间的阻塞造成的饥饿,类似于CFS 调度算法中的vruntime补偿机制。
这个设计虽然有效解决了慢查询占满资源,导致其他查询得不到执行的问题,却无法保障快查询的请求延迟。这是由于软件层面的多线程执行机制,线程个数大于了实际的CPU个数。在实际的应用中,计算线程的个数往往是可用Core的2倍。这也就是说,即使快查询的算子得到了计算线程资源进行计算,也会在CPU层面与慢查询的算子形成竞争。所下图所示,快查询的算子计算线程被调度到VCore1上,该算子在VCore1上会与慢查询的计算线程形成竞争。另外在物理Core0上,也会与VCore0上的慢查询的计算线程形成竞争。
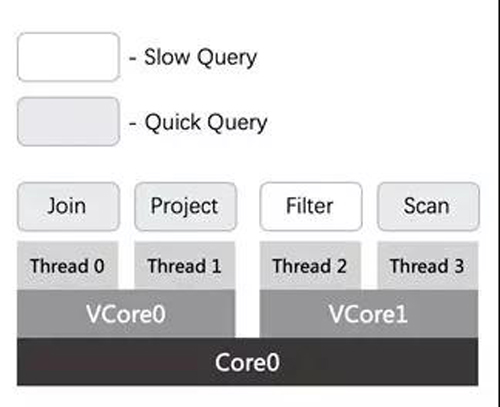
在Kernel sched模块中,对于不同优先级的线程之间的抢占机制,已经比较完善,且时效性比较高。因而,通过引入kernel层面的控制可以有效解决快查询低延迟的问题,且无需对算子的实现进行任何的改造。执行引擎让高优先级的线程来执行快查询的算子,低优先级的线程来执行慢查询的算子。由于高优先级线程抢占低优先级线程的机制,快查询算子自然会抢占慢查询的算子。此外,由于高优先级线程在Kernel sched模块调度中,具有较高的优先级,也避免了快慢查询算子在vcore层面的CPU竞争。

同样的在实际应用中是很难要求用户来辨别快慢查询,因为用户的业务本身可能就没有快慢业务之分。另外对于在线查询,查询的计算量也是不可预知的。为此,计算引擎在Runtime层面引入了快慢查询的识别机制,参考Linux kernel中vruntime的方式,对算子的执行时间、调度次数等信息进行统计,当算子的计算量达到给定的慢查询的阈值后,会把算子从高优先级的线程转移到低优先级的线程中。这有效提高了在压力测试下快查询的响应时间。
代码生成器
Dynamic code generation(CodeGen)普遍出现在业界的各大计算引擎设计实现中。它不仅能够提供灵活的实现,减少代码开发量,同样在性能优化方面也有着较多的应用。但是同时基于ANTLR ASM的AnalyticDB代码生成器也引入了数十毫秒编译等待时间,这在实时分析场景中是不可接受的。为了进一步减少这种延迟,分析引擎使用了缓存来重用生成的Java字节码。但是,它并非能对所有情况都起很好作用。
随着业务的广泛使用以及对性能的进一步追求,系统针对具体的情况对CodeGen做了进一步的优化。使用了Loading Cache对已经生成的动态代码进行缓存,但是SQL表达式中往往会出现常量(例如,substr(col1,1, 3),col1 like‘demo%’等),在原始的生成逻辑中会直接生成常量使用。这导致很多相同的方法在遇到不同的常量值时需要生成一整套新的逻辑。这样在高并发场景下,cache命中率很低,并且导致JDK的meta区增长速度较快,更频繁地触发GC,从而导致查询延迟抖动。
- substr(col1, 1, 3)
- => cacheKey<CallExpression(substr), inputReferenceExpression(col1), constantExpression(1), constantExpression(3)>cacheValue bytecode;
通过对表达式的常量在生成bytecode阶段进行rewrite,对出现的每个常量在Class级别生成对应的成员变量来存储,去掉了Cachekey中的常量影响因素,使得可以在不同常量下使用相同的生成代码。命中的CodeGen将在plan阶段instance级别的进行常量赋值。
- substr(col1, 1, 3)
- => cacheKey<CallExpression(substr), inputReferenceExpression(col1)>cacheValue bytecode;
在测试与线上场景中,经过优化很多高并发的场景不再出现meta区的GC,这显著增加了缓存命中率,整体运行稳定性以及平均延迟均有一定的提升。
AnalyticDB CodeGen不仅实现了谓词评估,还支持了算子级别运算。例如,在复杂SQL且数据量较大的场景下,数据会多次shuffle拷贝,在partitioned shuffle进行数据拷贝的时候很容易出现CPU瓶颈。用于连接和聚合操作的数据Shuffle通常会复制从源数据块到目标数据块的行,伪代码如下所示:
- foreach row
- foreach column
- type.append(blockSrc, position, blockDest);
从生产环境,大部分SQL每次shuffle的数据量较大,但是列很少。那么首先想到的就是forloop的展开。那么上面的伪代码就可以转换成
- foreach row
- type(1).append(blockSrc(1), position, blockDest(1));
- type(2).append(blockSrc(2), position, blockDest(2));
- type(3).append(blockSrc(3), position, blockDest(3));
上面的优化通过直接编码是无法完成的,需要根据SQL具体的column情况动态的生成对应的代码实现。在测试中1000w的数据量级拷贝延时可以提升24%。
矢量化引擎和二进制数据处理
相对于行式计算,AnalyticDB的矢量化计算由于对缓存更加友好,并避免了不必要的数据加载,从而拥有了更高的效率。在这之上,AnalyticDB CodeGen也将运行态因素考虑在内,能够轻松利用异构硬件的强大功能。例如,在CPU支持AVX-512指令集的集群,AnalyticDB可以生成使用SIMD的字节码。同时AnalyticDB内部所有计算都是基于二进制数据,而不是Java Object,有效避免了序列化和反序列化开销。
极致弹性
在多租户基础上,AnalyticDB对每个租户的DB支持在线升降配,扩缩容,操作过程中无需停服,对业务几乎透明。以下图为例:
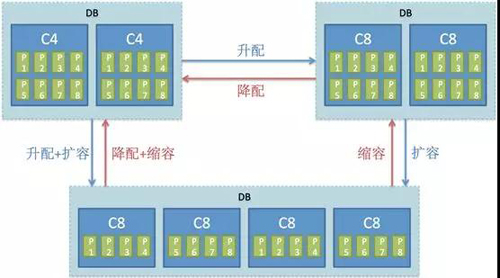
- 用户开始可以在云上开通包含两个C4资源的DB进行业务试用和上线(图中的P1, P2...代表表的数据分区)
- 随着业务的增长,当两个C4的存储或计算资源无法满足时,用户可自主对该DB发起升配或扩容操作,升配+扩容可同时进行。该过程会按副本交替进行,保证整个过程中始终有一个副本提供服务。另外,扩容增加节点后,数据会自动在新老节点间进行重分布。
- 对于临时性的业务增长(如电商大促),升配扩容操作均可逆,在大促过后,可自主进行降配缩容操作,做到灵活地成本控制。
在线升降配,平滑扩缩容能力,对今年双十一阿里巴巴集团内和公共云上和电商物流相关的业务库起到了至关重要的保障作用。
GPU加速
客户业务痛点
某客户数据业务的数据量在半年时间内由不到200TB增加到1PB,并且还在快速翻番,截止到发稿时为止已经超过1PB。该业务计算复杂,查询时间跨度周期长,需按照任意选择属性过滤,单个查询计算涉及到的算子包括20个以上同时交并差、多表join、多值列(类似array)group by等以及上述算子的各种复杂组合。传统的MapReduce离线分析方案时效性差,极大限制了用户快速分析、快速锁定人群并即时投放广告的诉求,业务发展面临新的瓶颈。
AnalyticDB加速方案
GPU加速AnalyticDB的做法是在Compute Node中新增GPU Engine对查询进行加速。GPU Engine主要包括: Plan Rewriter、Task Manager、Code Generator、CUDA Manager、Data Manager和VRAM Manager。
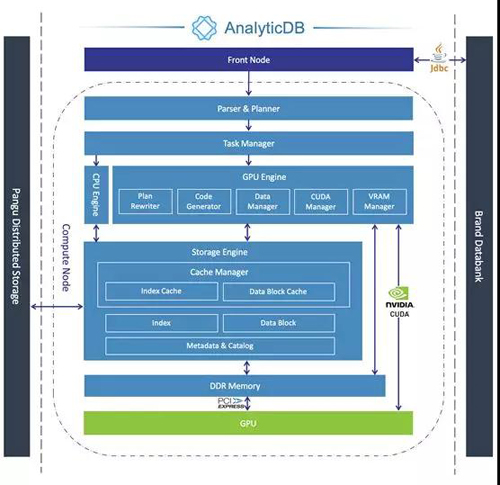
SQL查询从Front Node发送到Compute Node,经过解析和逻辑计划生成以后,Task Manager先根据计算的数据量以及查询特征选择由CPU Engine还是GPU Engine来处理,然后根据逻辑计划生成适合GPU执行的物理计划。
GPU Engine收到物理计划后先对执行计划进行重写。如果计划符合融合特征,其中多个算子会被融合成单个复合算子,从而大量减少算子间临时数据的Buffer传输。
Rewriting之后物理计划进入Code Generator,该模块主功能是将物理计划编译成PTX代码。Code Generator第一步借助LLVM JIT先将物理计划编译成LLVM IR,IR经过优化以后通过LLVMNVPTX Target转换成PTX代码。CUDA运行时库会根据指定的GPU架构型号将PTX转换成本地可执行代码,并启动其中的GPU kernel。Code Generator可以支持不同的Nvidia GPU。
CUDA Manager通过jCUDA调用CUDA API,用于管理和配置GPU设备、GPU kernel的启动接口封装。该模块作为Java和GPU之间的桥梁,使得JVM可以很方便地调用GPU资源。
Data Manager主要负责数据加载,将数据从磁盘或文件系统缓存加载到指定堆外内存,从堆外内存加载到显存。CPU Engine的执行模型是数据库经典的火山模型,即表数据需逐行被拉取再计算。这种模型明显会极大闲置GPU上万行的高吞吐能力。目前Data Manager能够批量加载列式数据块,每次加载的数据块大小为256M,然后通过PCIe总线传至显存。
VRAM Manager用于管理各GPU的显存。显存是GPU中最稀缺的资源,需要合理管理和高效复用,有别于现在市面上其他GPU数据库系统使用GPU的方式,即每个SQL任务独占所有的GPU及其计算和显存资源。为了提升显存的利用率、提升并发能力,结合AnalyticDB多分区、多线程的特点,我们设计基于Slab的VRAM Manager统一管理所有显存申请:Compute Node启动时,VRAM Manager先申请所需空间并切分成固定大小的Slab,这样可以避免运行时申请带来的时间开销,也降低通过显卡驱动频繁分配显存的DoS风险。
在需要显存时,VRAM Manager会从空闲的Slab中查找空闲区域划分显存,用完后返还Slab并做Buddy合并以减少显存空洞。性能测试显示分配时间平均为1ms,对于整体运行时间而言可忽略不计,明显快于DDR内存分配的700ms耗时,也利于提高系统整体并发度。在GPU和CPU数据交互时,自维护的JVM堆外内存会作为JVM内部数据对象(如ByteBuffer)和显存数据的同步缓冲区,也一定程度减少了Full GC的工作量。
GPU Engine采用即时代码生成技术主要有如下优点:
- 相对传统火山模型,减少计划执行中的函数调用等,尤其是分支判断,GPU中分支跳转会降低执行性能
- 灵活支持各种复杂表达式,例如projection和having中的复杂表达式。例如HAVING SUM(double_field_foo) > 1这种表达式的GPU代码是即时生成的
- 灵活支持各种数据类型和UDF查询时追加
- 利于算子融合,如group-by聚合、join再加聚合的融合,即可减少中间结果(特别是Join的连接结果)的拷贝和显存的占用
根据逻辑执行计划动态生成GPU执行码的整个过程如下所示:

GPU 加速实际效果
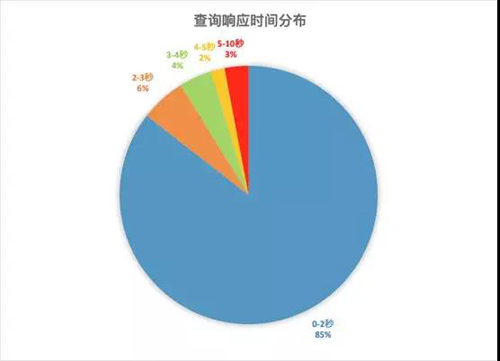
该客户数据业务使用了GPU实时加速后,将计算复杂、响应时间要求高、并发需求高的查询从离线分析系统切换至AnalyticDB进行在线分析运行稳定,MapReduce离线分析的平均响应时间为5到10分钟,高峰时可能需要30分钟以上。无缝升级到GPU加速版AnalyticDB之后,所有查询完全实时处理并保证秒级返回,其中80%的查询的响应时间在2秒以内(如下图),而节点规模降至原CPU集群的三分之一左右。 业务目前可以随时尝试各种圈人标签组合快速对人群画像,即时锁定广告投放目标。据客户方反馈,此加速技术已经帮助其在竞争中构建起高壁垒,使该业务成为同类业务的核心能力,预计明年用户量有望翻番近一个数量级。
总结
简单对本文做个总结,AnalyticDB做到让数据价值在线化的核心技术可归纳为:
- 高性能SQL Parser:自研Parser组件FastSQL,极致的解析性能,无缝集合优化器
- 玄武存储引擎:数据更新实时可见,行列混存,粗糙集过滤,聚簇列,索引优化
- 羲和计算引擎:MPP+DAG融合计算,CBO优化,向量化执行,GPU加速
- 极致弹性:业务透明的在线升降配,扩缩容,灵活控制成本。
- GPU加速:利用GPU硬件加速OLAP分析,大幅度降低查询延时。
分析型数据AnalyticDB, 作为阿里巴巴自研的下一代PB级实时数据仓库, 承载着整个集团内和云上客户的数据价值实时化分析的使命。 AnalyticDB为数据价值在线化而生,作为实时云数据仓库平台,接下来会在体验和周边生态建设上继续加快建设,希望能将最领先的下一代实时分析技术能力普惠给所有企业,帮助企业转型加速数据价值探索和在线化。
【本文为51CTO专栏作者“阿里巴巴官方技术”原创稿件,转载请联系原作者】























