一.内容简介
spark从1.6开始引入了动态内存管理模式,即执行内存和存储内存之间可以互相抢占。spark提供两种内存分配模式:静态内存管理和动态内存管理。本系列文章分别对这两种内存管理模式的优缺点以及设计原理进行了分析。主要针对spark1.6静态内存管理进行了分析与说明。
二.内存空间分配
在 Spark 最初采用的静态内存管理机制下,存储内存、执行内存和其他内存的大小在 Spark 应用程序运行期间均为固定的,但用户可以应用程序启动前进行配置,堆内内存的分配如下图所示:
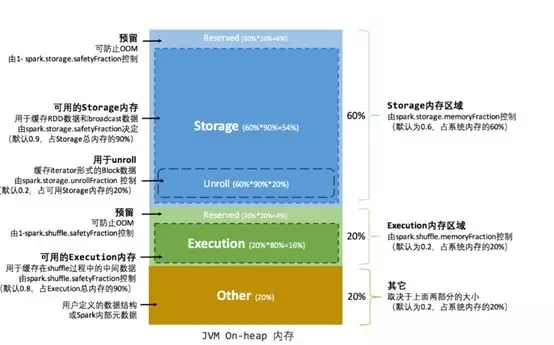
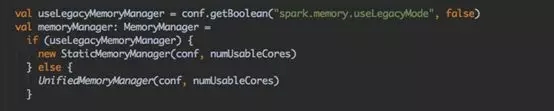
默认情况下,spark内存管理采用unified模式,如果要开启静态内存管理模式。将Spark.memory.useLegacyMode参数调为true(默认为false)。官网相关配置如下:

当调整该参数以后,从SparkEnv.scala中可知,如果为true,内存管理调用静态内存类(StaticMemoryManager)。反之,内存管理采用统一内存管理类(UnifiedMemoryManager)。
三.Execution 内存
可用的Execution内存
用于shuffle聚合内存,取决于joins,sorts,aggregations等过程中频繁的IO需要的Buffer临时数据存储。
简单来说,spark在shuffle write的过程中,每个executor会将数据写到该executor的物理磁盘上,下一个stage的task会去上一个stage拉取其需要处理的数据,并且是边拉取边进行处理的(和MapReduce的拉取合并数据基本一样),这个时候会用一个aggregate的数据结构,比如hashmap边拉取数据边进行聚合。这部分内存就被称做execution内存。
从getMaxExecutironMemory方法可知,每个executor分配给execution的内存为:Execution Memory = systemMaxMemory *memoryFraction(默认0.2) * safetyFraction(默认0.8), 默认为 executor ***可用内存 * 0.16。

Execution内存在运行时会被分配给运行在JVM上的task。这里不同的是,分配给每个task的内存并不是固定的,而是动态的。spark不是一上来就分配固定大小的内存块给task,而是允许一个task占据JVM所有execution内存。
每个JVM上的task可以最多申请至多1/N的execution内存(N为active task的个数,由spark.executor.cores指定)。如果task的申请没有被批准,它会释放一部分内存,并且下次申请的时候,它会申请更小的一部分内存。
注意:为了防止过多的spilling(evict)数据,只有当一个task分配到的内存达到execution内存1/(2N)的时候才会spill, 如果目前空闲的内存达不到1/(2N)的时候, 内存申请会被阻塞直到其他的taskspill掉它们的内存。如果不这样限制,假设当前有一个任务占据了绝大部分内存,那么新来的task会一直往硬盘spill数据,这样就会导致比较严重的I/O问题。
举个例子, 某executor先启动一个task A,并在task B启动前快速占用了所有可用内存。(B启动后)N变成2,task B会阻塞直到task A spill,自己可获得1/(2N)=1/4的execution内存。而一旦task B获取到了1/4的内存,A和B就都有可能spill了。
预留内存
Spark之所以有一个SafetyFraction这样的参数,是为了避免潜在的OOM。例如,进行计算时,有一个提前未预料到的比较大的数据,会导致计算时间延长甚至OOM, safetyFraction为storage和execution 都提供了额外的buffer以防止此类的数据倾斜。这部分内存叫做预留内存。
四.Storage内存
可用的Storage内存
该部分内存用作对RDD的缓存(如调用cache,persist等方法),节点间传输的广播变量。
从StaticMemoryManager的单例对象中可知,***为每个executor分配到的关于storage的内存:
StorageMemory=systemMaxMemory*storageMemoryFraction(默认0.6)*safetyFraction(默认为0.9)=0.54,
也就是说 默认分配executor ***可用内存的 *0.54。源码如下:

预留内存
同Execution内存中的预留部分。
Unroll
unroll是storage中比较特殊的一部分,它默认占据总内存的20%。
BlockManager是spark自己实现的内部分布式文件系统,BlockManager接受数据(可能从本地或者其他结点)的时候是以iterator的形式,并且这些数据有序列化和非序列化的。需要注以下两点:
a) iterator在物理内存上是不连续的,如果后续spark要把数据装载进内存的话,就需要把这些数据放进一个array(物理上连续)。
b) 另外,序列化数据需要进行展开,如果直接展开序列化的数据,会造成OOM, 所以,BlockManager会逐渐的展开这个iterator,并逐渐检查内存里是否还有足够的空间用来展开数据放进array里。

unroll的优先级还是比较高的,它使用的内存空间可以从storage中借用,如果在storage中没有现存的数据block,它甚至可以占据整个storage空间。如果storage中有数据block,它可以***drop掉内存的数据是以spark.storage.unrollFraction来控制的。由图6可知,这部分默认为storage的20%。
注意:这个20%的空间并不是静态保留的,而是通过drop掉内存中的数据block来分配的。如果unroll失败了,spark会把这部分数据evict 到硬盘。
五.Other 部分
这片内存用于程序本身运行所需的内存,以及用户定义的数据结构和创建的对象,此内存有上面两部分决定,默认为0.2。
六.局限性
spark的设计文档中指出静态内存有以下局限性:
(1)没有适用于所有应用的默认配置,通常需要开发人员针对不同的应用进行不同的参数配置。比如根据任务的执行逻辑,调整shuffle和storage内存占比来适应任务的需求。
(2) 这样需要开发人员具备较高的spark原理知识。
(3) 那些不cache数据的应用在运行时只占用一小部分可用内存,因为默认的内存配置中,storage用去了safety内存的60%。
概念补充
eviction策略:在spark技术文档中,eviction一词经常出现。eviction并不是单纯字面上驱逐的意思。说句题外话,spark我们通常都把它叫做内存计算框架,严格意义来说,spark并不是内存计算的新技术。无论是cache还是persist这类算子,spark在内存安排上,绝大多数用的都是LRU策略(LRU可以说是一种算法,也可以算是一种原则,用来判断如何从Cache中清除对象,而LRU就是“近期最少使用”原则,当Cache溢出时,最近最少使用的对象将被从Cache中清除)。即当内存不够的时候,会evict掉最远使用过的内存数据block。当evict的时候,spark会将该数据块evict到硬盘,而不是单纯的抛弃掉。
无论是storage还是execution的内存空间,当内存区域的空间不够用的时候,spark都会evict数据到硬盘。
因此,如果开发人员在内存分配上没有合理的进行分配,无论是在storage还是execution超过内存的限制的时候,spark会把内存的数据写到硬盘。如果是storage的情况,甚至可能把内存的数据全部写到硬盘并丢掉。这样做,无疑会增加系统调用、I/O以及重复计算的开销。有过开发spark任务中包含大量shuffle stage的同学应该有同感,shuffle memory不够的时候,spill到硬盘的数据会很大,导致任务很慢,甚至会导致任务的各种重试***任务fail掉。这种情况建议提高shuffle memory fraction。如果是资源调度在yarn上,建议通过spark.yarn.executor.memoryOverhead提高堆外内存,有的时候甚至会调到2g,3g,4g直到任务成功。spark相关优化,请参见spark系列后续的文章。
七.参考
[1] Unified Memory Management in Spark 1.6,Andrew Or and Josh Rosen
[2]https://www.ibm.com/developerworks/cn/analytics/library/ba-cn-apache-spark-memory-management/index.html?ca=drs-&utm_source=tuicool&utm_medium=referral
[3] https:// http://spark.apache.org
[4] http://www.jianshu.com/p/e41b18a7e202