【51CTO.com原创稿件】2018年11月30日-12月1日,WOT2018全球人工智能技术峰会在北京·粤财JW万豪酒店盛大召开。60+国内外人工智能一线精英大咖与千余名业界人士齐聚现场,分享人工智能的平台工具、算法模型、语音视觉等技术内容,探讨人工智能如何赋予行业新的活力。两天会议涵盖通用技术、应用领域、行业赋能三大章节,开设13大技术专场,如机器学习、数据处理、AI平台与工具、推荐搜索、业务实践、优化硬件等,堪称人工智能技术盛会。
在《AI平台和工具》分论坛,ThoughtWorks智能服务团队技术总监白发川、百度深度学习技术平台部总监马艳军和偶数科技AI负责人刘大伟,三位专家分享了各种深度学习的框架与工具,如TensorFlow、PaddlePaddle等应用及技巧。

持续智能——打造规模化的AI服务
ThoughtWorks智能服务团队技术总监白发川在《持续智能——打造规模化的AI服务》主题演讲中提到,持续集成、持续交付、持续部署可以让软件在快速迭代的同时保持着较高的软件质量。随着机器学习的普及,越来越多的服务更加的个性化、定制化,“持续智能”定义了一套对此类服务进行快速迭代和发布的方法。
智能的定义大致可以分为三个等级:一是为响应当前运营需求而不得不开展的一系列工作;二是把AI变成一种基础服务,融入到业务场景中;三是把AI变成个性化服务,可以组合产生新的业务场景。其中,第三个级别是较为理想的状态,通过人工智能发现新的业务和价值点,达到更好的用户体验。
整体来看,目前人工智能在企业落地的过程中仍然面临诸多挑战。首先是规模化的问题,AI模型的边界难以衡量,也很难复用现有模型的构建过程。其次是工程实践的三大难题:难于追踪,难于重现,难于部署。然后是数据问题,包括数据或模拟数据量不足,数据治理不足,数据安全隐患等诸多问题。很多开发者发现,对于一个机器模型,数据带来的挑战远远大于调整神经网络参数或选用算法带来的难度。

ThoughtWorks智能服务团队技术总监白发川
人工智能在业务系统或生态环境中落地实施,大致可以分为三个阶段。一是做PoCs[鸢玮1] (Projections onto convex sets),评估并验证模型、服务或方案是否可行,完成单个模型的发布和上线。第二个阶段开始解决规模化的问题,因为经过优化和训练后的模型,才可用于生产。第三个阶段进行跨业务系统的AI服务集成。
在PoCs阶段,需要引入数据中台的概念,使用数据治理、血缘分析、可访问性和多语言数据存储构建现代数据体系结构。传统的数据仓库架构只能解决智能的一个维度,也就是支撑运营,而在机器学习场景下,非结构化和半结构化的数据需要大规模ETL动作,则要使用到数据中台架构。
在第二阶段,因为从开发到发布训练再到实施,整个过程过于手动,需要一个产品化的机器学习架构。通过引入优秀实践,例如CI/CD,TDD,Pipeline等技术方法使模型从创建到发布的过程[鸢玮2] 可被复用,跟踪和重现。
在第三阶段,需要搭建跨业务的机器学习架构,通过端到端的机器学习流水线构建平台,更大限度的共享企业的AI服务、数据和算法,达到跨业务线的智能服务整合。
可复用的模型构建过程
- 和数据平台结合,利用数据平台的能力作为数据支撑,更好的发挥数据平台的价值;
- 拆分服务构建环节,智能服务开发流程化,快速响应业务需求;
- 利用元数据管理方式,提供统一的标准格式,场景可以多人协同配合开发;
- 基础设施共享化,模型的训练和发布与数据平台有效绑定,服务的构建自动化;
- 统一的元数据管理系统,模型的全生命周期可管理;
- 通用AI能力平台化,降低人员要求,提升协作效率。
数据中台
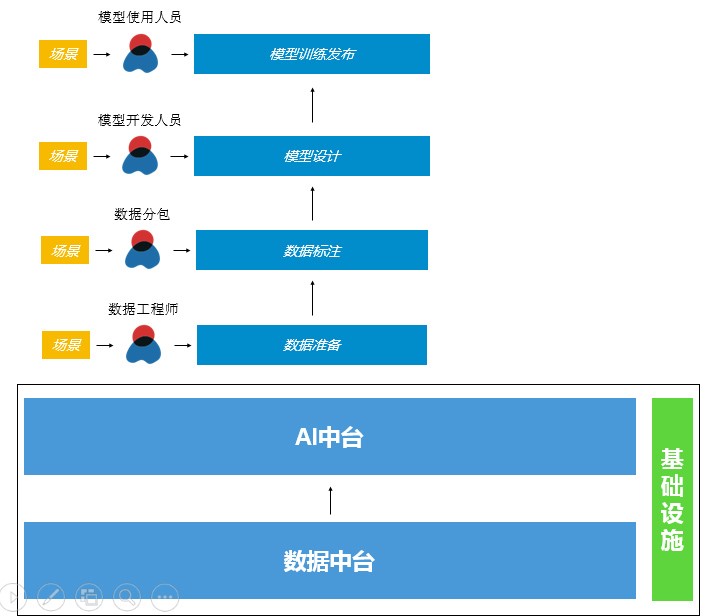
要想实现持续智能,让AI模型像流水线一样可以持续发布,需要先解决以下几层问题:一是数据中台,可以将数据整合、数据加工、数据处理、数据发布的过程形成一整套流水线。二是要有AI基础设施平台,可以选择所需要的算法、框架和服务,以及模型发布所需要的运行环境,并实现流水化。三是数据和AI能力的汇聚层,解决数据和AI基础平台的衔接问题,例如模型的数据从哪来,模型在哪发布,在哪存储等等。这三层能力构建好,就能实现持续发布、持续迭代和持续上线,也就是常说的AI流水线。
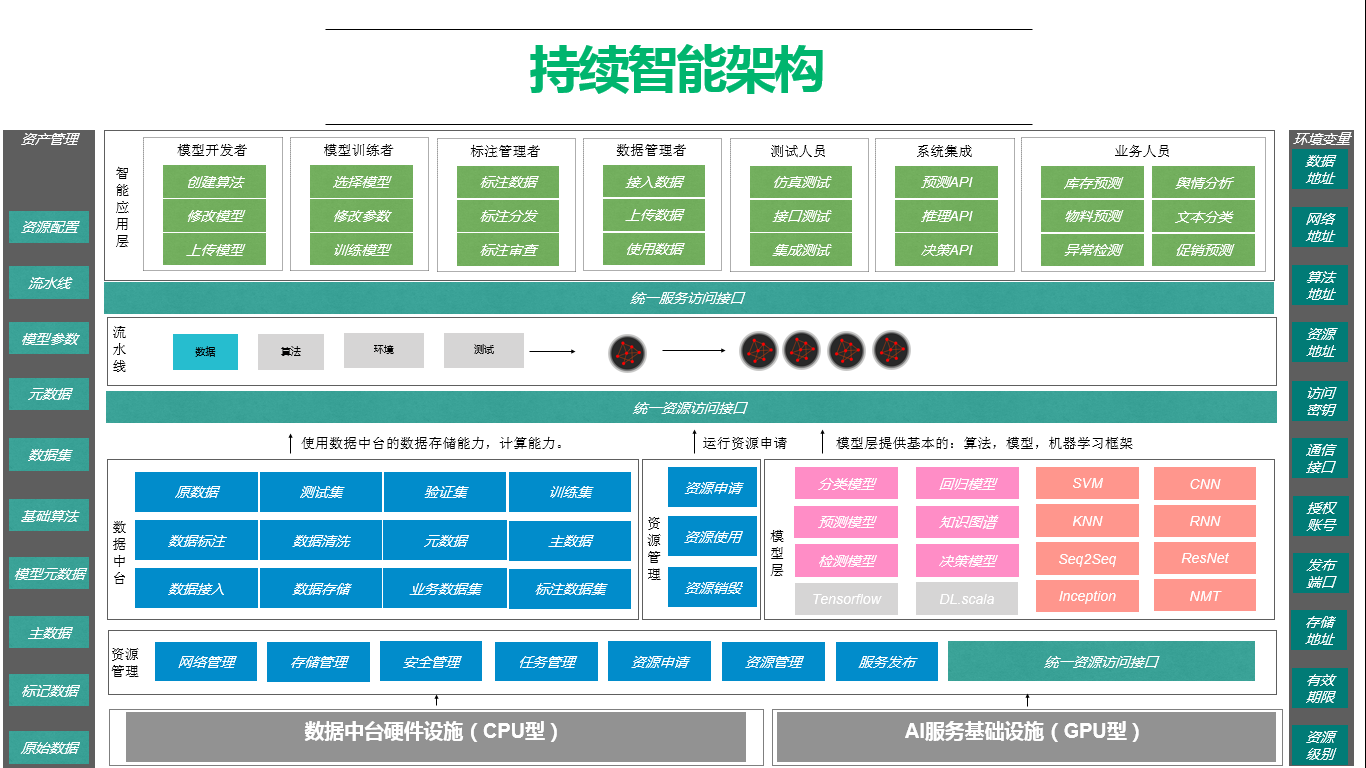
持续智能架构的构建步骤
- 从硬编码到自适应模型;
- 使用大规模数据训练特定模型;
- 构建可扩展的系统;
- 创造交互式AI探索开发工具;
- 协同设计算法、软件和产品。
企业级机器学习目标
- 大规模数据集下的模型训练;
- 模型分析和比较工具;
- 端到端的模型workflow;
- 可规模化的机器学习模型生态系统;
- 可复用的算法和服务;
- 实验管理。
企业级机器学习方案
- 分布式训练工具;
- 性能报告流程;
- 可视化的构建过程;
- Python Jupyter, R, Sklearn, TensorFlow, PyTorch, SparkML, ONNX等。
可选的工具
白发川列举了企业级机器学习一个模型、多个模型以及跨业务线和部门的案例,并列举了机器学习的框架及工具。他强调,在考虑AI规模化落地的过程中,首先要考虑如何提高底层AI能力,然后再去构建上层的AI模型和业务场景,如果先考虑解决业务场景问题,往往会在AI规模化的过程中处处碰壁。
扫描下方二维码查看详细课程

PaddlePaddle深度学习框架
百度深度学习技术平台部总监马艳军在演讲中分析了深度学习技术的发展历程和未来趋势,以及深度学习框架的发展现状。结合百度在深度学习技术应用的情况,为参会者带来了国内开源开放的深度学习框架PaddlePaddle的进展,介绍PaddlePaddle的技术领先性,分享了PaddlePaddle为各行各业进行AI赋能的经验和成果。
百度使用深度学习技术可以追溯到2012年,短短一年时间就将其应用于百度的搜索和推荐业务,并带来业务的显著提升。2015年百度上线了完全基于深度学习的翻译引擎。随着深度学习技术大火,应用场景越来越多,并且已经开始工具化,也就是所谓的深度学习框架,例如TensorFlow以及PaddlePaddle先后开源,而PaddlePaddle是百度内部长期研发的深度学习框架。

百度深度学习技术平台部总监马艳军
实际上,深度学习框架的开源从很大程度上降低了技术的准入门槛,但开发者仍然需要特定的知识背景和硬件资源支持。要深入研究这一系统还是过于复杂,因此又诞生了一系列的工具。例如针对深度学习调参的难题,百度开放了网络结构自动化设计工具AutoDL,让开发者无需经过特殊训练即可完成。此外,百度还发布了更简单的定制化AI模型应用平台——EasyDL,它是一个零算法基础的快速应用平台,无需代码,无需任何专业背景即可轻松定制模型,与云端结合,使用户无任何后顾之忧。
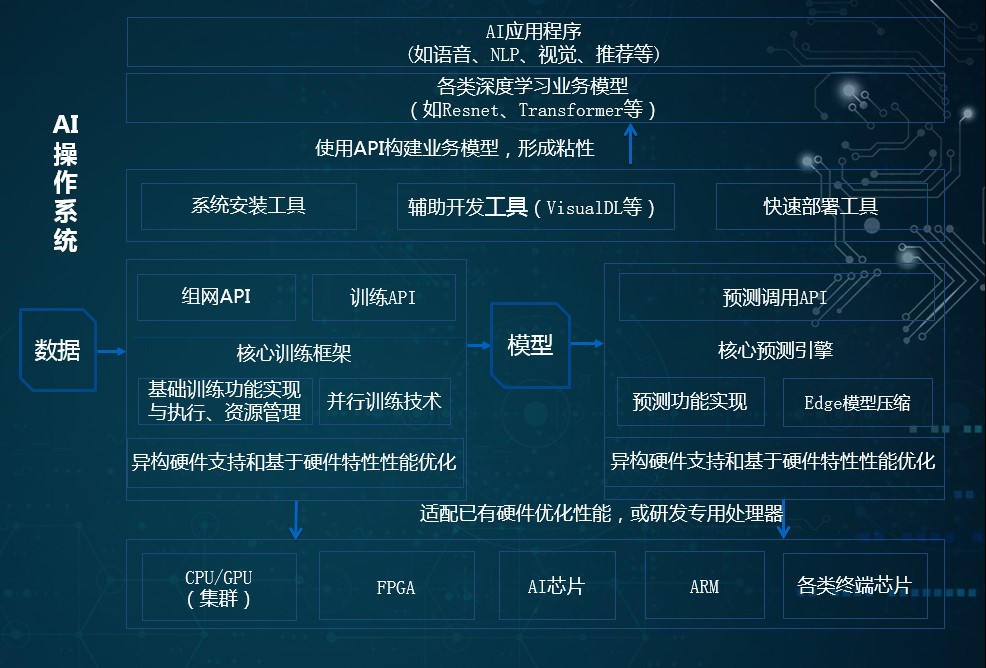
以深度学习框架为核心的“操作系统生态”
马艳军提到,在AI场景下,深度学习框架与操作系统类似,它介于用户程序和硬件资源之间,通过内核为用户程序提供资源调度,通过接口为用户程序提供开发便利。深度学习框架要解决的是如何把底层的硬件性能发挥到更高水平,向上提供API,让企业实现自己的算法。当然,深度学习框架之上也会开放很多算法、可视化工具、安装和部署工具等,企业或个人可以直接开发和使用这些模型,搭建自己的AI程序。
PaddlePaddle与其他深度学习框架不同的是,一是更注重模型以及API的兼容性,在深度学习的安装环境适配方面作了深度优化和验证,让开发者能真正用起来;二是更加便于二次开发,降低了企业的应用成本;三是性能更加稳定,并且更重视对上层视觉、语言处理、情感分析、对话系统等场景应用的支持,而不只是底层工具性的应用。此外,PaddlePaddle配套的工具和组件也非常丰富,包括AutoDL、VisualDL、EasyDL等等。
此外,PaddlePaddle官方公开的模型数量丰富多样,且都是百度长期验证过的模型,效果持续、稳定。而对于大规模的数据场景,PaddlePaddle的并行能力也是一大强项。在部署方面,百度开放了大量的特有模型,包括推荐模型、视觉模型、NLP模型等。
马艳军表示,百度做了很多跟AI生态相关的工作,包括开放数据、评估标准以及平台,举办一系列的专家课程,目的就是降低深度学习的门槛,让AI技术为行业赋能,提高行业生产力。
让人人都会使用AI
偶数科技AI负责人刘大伟从人工智能行业发展现状出发,列举了行业发展的机遇和挑战,进而介绍人工智能建模系统的优势及便利性。另外,以偶数科技的反洗钱金融项目为例,对如何“让普通人轻松拥抱AI,助力行业实践”进行了深入讲解。
刘大伟表示,人工智能技术在语音识别和图像识别领域取得了飞速进展,AI技术已经渗透到多个领域,例如AI模型能够通过视网膜诊断糖尿病,AI能够预测工业生产线上的设备状态,通过AI动态探测系统,来保护像东北虎等野生动物。

偶数科技AI负责人刘大伟
偶数科技应用AI技术在反洗钱领域已经取得了成功案例。据悉,美国大型征信机构已经开始利用AI模型来计算FICO评分系统,从而锁定非法交易。在中国每年有两千亿的洗钱交易发生,破坏了金融的稳定性,我国也出台了反洗钱相关的法律和监管政策,因此每个银行都有责任和义务去监管银行内发生的每笔交易,找出洗钱行为,上报央行统一处理。
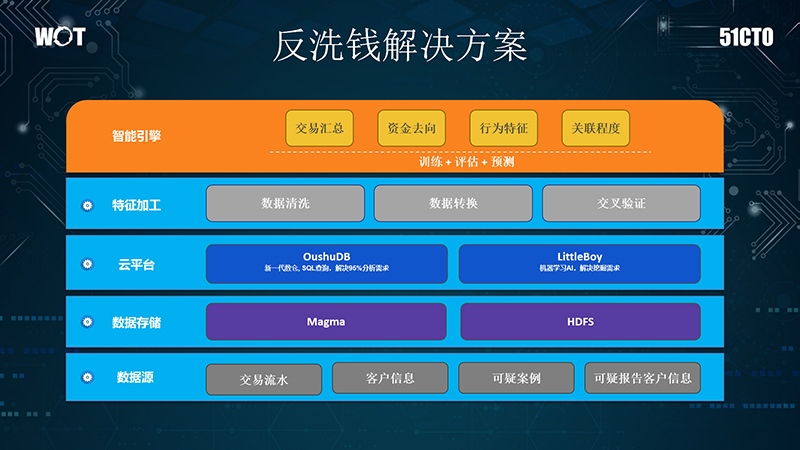
偶数科技反洗钱解决方案底层是数据源,包括交易流水,客户信息,洗钱模式样本,训练模型等。中间两层是OushuDB和LittleBoy人工智能平台,以及分布式存储组件。上层经过数据清洗,数据转换和交叉验证,得到有意义的洗钱相关的数据。偶数科技通过AI建模,提供了多个可行的模型方案,减少推送的可疑案件量和人工排查工作量可达上百倍。
可行模型方案
- 现有方法:查全率100%,查准率约1%;
- 偶数模型A:查全率100%,查准率51.43%;
- 偶数模型B:查全率86.11%,查准率92.08%。
在Oushu Lava AI Cloud上承载着OushuDB数仓,以及LittleBoy人工智能平台,既可以在公有云上管理整个集群,也可以部署在用户自己的私有云中。反洗钱解决方案从数据、建模、发布到接入银行的系统,整个流程听起来很复杂,但其实它很简单,甚至不需要学习专业的AI知识。例如,在LittleBoy的AI工作室里,有很多现成的组件,用户只需通过最短半个小时的培训,了解配置节点的方法,就能通过拖拽操作将组件连接成不同的工作流,甚至是构建复杂应用。
五步训练分类模型
除此之外,偶数科技找到了更为简便的方法,增加了另一种建模方式,通过五步的引导式界面,不需要多少AI知识就可以将AI模型搭建起来。
- 头一步:训练数据,把所有集群、数据库、数据表中的数据通过树形结构展现;
- 第二步:选取特征及标签,网络会自动识别哪些Feature更加有用,因此不需要做太多的特征工程;
- 第三步:评估模型;
- 第四步:配置算法,系统默认使用AutoML自动调整算法, 它会自动的去探索所需要的神经网络的网络结构,而且也会自动地去匹配一套超参组合,因此也无需配置,如果你是AI工程师,也可以自己填写参数;
- 第五步:点击启动,开始训练,训练过程中可以实时监控模型收敛状态。
模型训练完成后,只需点击发布,模型的发布以及服务都将在系统中自动完成。
此外,偶数科技还提供通用的REST API调用工具,用户只要把这个接口集成到自己的应用中,就能马上获得AI能力,非常适合那些已有的不能在短期内更新的系统,通过调用API,这些系统将马上变成人工智能系统。
扫描下方二维码查看详细课程

以上内容是51CTO记者根据WOT2018全球人工智能技术峰会的《AI平台和工具》分论坛演讲内容整理,更多关于WOT的内容请关注请关注51cto.com。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】