












【51CTO.com原创稿件】2018年11月30日-12月1日,WOT2018全球人工智能技术峰会在北京·粤财JW万豪酒店盛大召开。60+国内外 人工智能一线精英大咖与千余名业界专业人士齐聚现场,分享人工智能的平台工具、算法模型、语音视觉等技术内容,探讨人工智能如何赋予行业新的活力。两天会议涵盖通用技术、应用领域、行业赋能三大章节,开设13大技术专场,如机器学习、数据处理、AI平台与工具、推荐搜索、业务实践、优化硬件等,堪称人工智能技术盛会。

大量的数据可以提供训练学习算法所需,如何利用数据来培训人工智能,使其获得更精准的结果?针对这个问题,本届WOT2018峰会特别设置了《数据处理》分论坛。来自VIPKID、易观智库、BBAE Holdings的三位大咖围绕“聚焦数据处理,挖掘数据价值”进行了主题分享。
智能匹配在在线教育行业的应用
VIPKID是一家在线少儿英语教育公司。VIPKID供需优化技术负责人沈亮主要负责供给侧优化、需求匹配、课程质量方面的工作,此次演讲他详细介绍了智能匹配在在线教育行业中的应用。

VIPKID供需优化技术负责人 沈亮
在线教育行业是典型的双边市场,双边市场的概念是指2组参与者通过中间平台进行交易,并且一方的收益决定另一方参与者的数量。在VIPKID快速发展的过程中,随着用户规模的变大,传统抢单模式的弊端慢慢暴露出来。比如:用户无法挑选到合适的老师;用户选择其他用户喜好的老师;以及平台马太效应愈发严重。和外卖、快递、出行等行业的发展轨迹一样,VIPKID慢慢从抢单过度到智能派单,能够有效地提升平台的整体效率,同时,提升用户的产品满意度。
那么,整个双边市场的匹配是一个怎么样的AI问题呢? 沈亮认为,可以把它分为3个层次,从不同的建设周期来考虑。最长周期是生态规划的基础建设,比如:根据需求侧的发展来预测一定时间内老师的招募,司机,配送小哥的招募。第二个层次是市场调节,可以通过经济手段来调节,比如:高峰期的司机补贴、乘客加价,乘客优惠券的发放,老师长期的加薪周期,开课激励等。第三个层次是单次用户需求的满足,通过实时的派单产品、以及用户抢单产品来实现。
谈到如何构建在线教育行业的智能匹配模型,沈亮表示,VIPKID将模型区分为两个阶段,第一阶段是用户找到合适供给的阶段,我们构建了个性化的匹配机制。第二阶段是用户找到了合适的供给以后,我们通过约课机制来保障用户需求能够持续得到满足。
VIPKID在优化整体的学习目标时,也是在不断变化的,每个阶段的思考点是不同的。一开始VIPKID按照Feed流产品的思路,用列表页点击来做为机器学习的正样本。其中核心问题是,从Feed流到真正产生交易的概率低,不能代表用户的核心诉求。第二步,优化用户约课动作发生,从约课到上课有2周左右的周期,并且用户对陌生老师的再复约率不到40%。所以有了第三点目标的变化,用户重复约课的老师是正样本,用户约课后不满意为负样本。这一步主要的问题是1、不满意的用户不表达,2、平台不好约还是用户不满意区分度不强。最终,VIPKID选择了上课质量做为机器学习的优化目标。
海豚系统是VIPKID的一整套在线视频的解决方案。以课程质量分析模块为例,它主要是通过从语音、图像、交互角度上来分析老师/学生的课堂表现,评估每堂课的教学/学习质量。其中图像部分主要进行人脸识别/检测、手势识别(TPR教学方法)、表情识别(笑脸)、语音方面则包括老师语音识别、语音情感识别、噪音识别。通过这些课堂的特征来构建课堂质量评估模型,VIPKID通过专家标注+数据挖掘的方式来区分好课和差课。
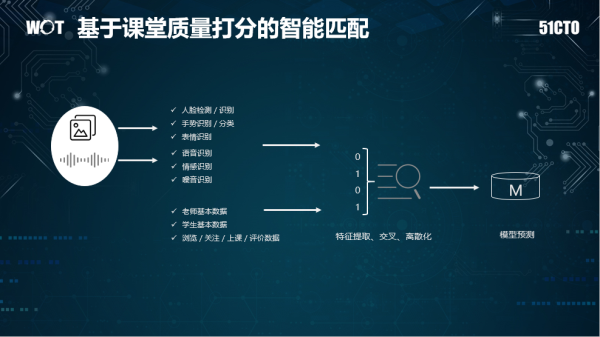
有了课堂质量分的概念,对于一个陌生老师,VIPKID则会提取该老师最近上课视频中的语音、图像相关的特征,学生喜欢的老师图像、语音相关特征,以及老师/学生的一部分结构化数据,进行特征挖掘、交叉和离散化从而构建不同的模型,然后发布到线上A/B测试来监控质量、以及核心指标的变化。
在市场机制、规则设计上,VIPKID推出了专属外教产品,能够让用户通过简单的一步即可和自己喜欢的老师长期上课。专属外教的产品逻辑是这样的,首先,用户设置自己喜欢的老师和上课时间,第二步,系统会在所有的规则集合内进行系统派单,从数学角度上来看,这是一个简单的2分加权图的分配问题。VIPKID用了传统的KM (Kuhn-Munkres)算法了解决,也取得了不错的效果。
VIPKID通过构建基于课程质量的智能匹配模型,完善了师生稳定上课阶段的派单引擎;另外,VIPKID在供给侧采用了相对隔离,以及师生匹配的预分配。上线前后最大的变化就是,它让用户更快地选择到适合自己的老师,可以从两方面衡量,第一,用户找到合适老师的成本(课节数)下降40%;其次,用户找到合适老师的时间下降了33%。
另外,智能匹配也使得用户不需要抢课,有了更好的约课体验;从数据上有两点明显改进,第一,周一高峰期来抢课的用户群体下降幅度高达42%。第二,系统派单的占比持续提升,4个月时间,提升比例高达85%。

基于IOTA架构的实时数据引擎
易观智库CTO郭炜分享了题为《IOTA 数据架构——基于边缘计算的适用于大数据和人工智能新一代计算架构》的主题演讲,详细讲解了基于IOTA数据河的计算引擎的实现思路,以及数据河的基本理念。

易观智库CTO 郭炜
郭炜指出,现代大部分企业都在面临大数据困境,存在大数据“大而不强”,人工智能 “人工”而不“智能”的问题。企业在应用大数据的过程中,无论是大数据部门的研发、总监还是架构师都会面临四大挑战:
- 随着大数据、人工智能的火爆,相关人才严重不足;
- IoT正在让数据量持续爆发,移动互联网数据将会增长十倍,乃至几十倍,大数据存储永远不够,并且企业并不知道这些数据如何利用;
- 业务分析多变难以满足:业务部门希望通过选择维度或者拖拽的方式,能够尽可能快的展现出结果。随着数据量越来越大,定义指标、预定维度正在变得越来越困难;
- IoT,移动端,CRM数据正在变得越来越多,越来越复杂,格式也不统一。
他认为,要解决企业的这些问题,就需要使用新一代的数据计算架构IOTA架构——基于边缘计算的适用于大数据和人工智能新一代计算架构。它将数据和AI模型,从中央集中计算放到边缘进行计算,最终形成企业数据的业务闭环,提高企业运行效率。IOTA架构扩展到整个企业就形成了数据水系的理论,数据河补全了数据湖的流动性问题,将IOTA架构扩展到整个企业,从而改善整个企业大数据和人工智能与业务的交互效率以及自身技术的发展速度。
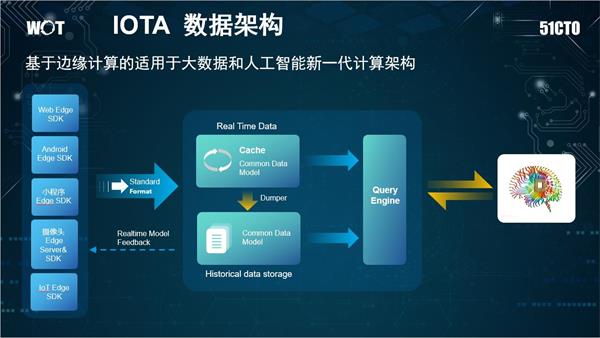
IOTA数据架构具有四大优势:
- 去ETL ((Extract-Transform-Load))化架构:过去企业都在做ETL,每次都要进行各种各样的数据处理,而IOTA架构则不再使用ETL,所有数据产生的时候就已经处理好,可以直接放到云端,进行数据查询;
- 非结构化实时结构化为SQL数据存储:大量事件都是非结构化数据,企业所要做的是把其实时转化为结构化数据进行存储。
- 支持IoT设备与现有移动端数据融合:企业常常会遇到Web端和Android端的用户如何打通的问题,需要花费企业很多精力,搭建平台进行分层,而现在就可以直接进行数据的融合。
- 支持边缘AI实时反馈:一方面,企业可以把数据直接存储在云端,很快的查询到边缘的数据。另一方面,在一些简单的数据模型中,企业可以把参数下放到SDK中,让SDK进行集成。而不再需要每次都在云端进行大量计算,直接在边缘端进行计算即可。
IOTA的整体技术结构分为几部分:
- 核心模型Common Data Model:始终贯穿IOTA架构的数据模型,需要SDK、Cache、历史数据、查询引擎保持一致。对于用户数据分析来讲,可以定义为“主-谓-宾”或者“对象-事件”这样的抽象模型来满足各种各样的查询。以APP用户模型为例,用“主-谓-宾”模型描述就是“X用户 – 事件1 – A页面(2018/4/11 20:00) ”。
- 核心组件Edge SDK:不仅仅是过去的简单的SDK,在复杂的计算情况下,会赋予SDK更复杂的计算, 在设备端就转化为形成统一的数据模型来进行传送。例如,对于智能Wi-Fi采集的数据,从AC端就变为“X用户的MAC 地址-出现- A楼层(2018/4/11 18:00)”这种主-谓-宾结构,对于摄像头会通过Edge AI Server,转化成为“X的Face特征- 进入- A火车站(2018/4/11 20:00)”,对于智能音箱就会变为“X用户-启动-Y设备 (2018/4/11 20:00)”。
与此同时,企业如何利用数据产生价值呢?郭炜给出的答案是企业需要打造一个数据驱动的中台。很多企业认为,数据中台就是把各种数据组件打包、把大数据存储好即可。但是随着时间积累,数据中台就会从数据湖变成数据沼泽。由此,易观提出了数据河的概念,中国有句俗话叫“流水不腐,户枢不蠹”,也就是数据一定要像河水一样流动起来,才不会产生瘀泥。具体来说,数据河就是,从数据产生端直接通过IOTA架构数据河实时流向数据使用者,而不再需要像过去一样层层加工之后才能使用,其好处就在于如果遇到数据质量发生问题,不用等到数据加工完几天甚至是一个月之后才发现,而是在最早的时间,数据的发生者和使用者就能够很快的发现问题,从而驱动解决问题。
最后,郭炜为与会者举了一个IOTA架构引擎的实例——易观秒算,具有以下六大特点:
- 去“ETL”化;
- 高效:时时入库即时分析;
- 稳定:经过易观5.8Pb,5.2亿月活数据锤炼;
- 跨数据库:天然支持“Data Federation”数据联邦针对MySQL等数据库跨库查询;
- 便捷:支持SQL级别的二次开发和UDAF定义;
- 扩充性强:组件基于Apache开源协议,可支持众多开源存储对接。

基于大数据AI的金融建模
来自SEC备案注册的初创投资顾问平台BBAE Holdings的CTO刘玥带来了题为《基于大数据AI的金融建模——BBAE 智能投顾模型的机器学习实践》的主题演讲,围绕BBAE智能投顾产品的设计实现,详细介绍了如何基于统计模型和机器学习来构建一个自适应的资产管理组合。

BBAE Holdings CTO 刘玥
刘玥首先介绍了智能投顾的前世今生。Robo Advisory(智能投顾)概念始于2008经济危机后,2010年,Betterment将基于算法的资产管理模式成功带入人们的视线。德勤预计2025年,美国基于AI和算法模型的资产管理模式将管理多达5万亿至7万亿美金的资产。
传统的建模方法包括Risk Neutral、Constant Mix、60/40、Equal Weighted。
- Risk Neutral:例如,给定两个投资机会,风险中性投资者只关注每个投资的潜在收益,而忽略潜在的下行风险;
- Constant Mix:你买入低价并且卖得很高,因为你卖出表现最好的股票来买入表现最差的股票;
- 60/40:60%的股票和40%的债券或其他固定收益产品;
- Equal Weighted:许多最大和最知名的市场指数是市值加权或价格加权。市值加权指数,如标准普尔500指数,根据市值对大公司给予更大的重视。苹果和通用电气等大型股是标准普尔500指数中最大的股票。道琼斯工业平均指数等价格加权指数给股票价格上涨的股票带来更大的权重。小盘股通常被认为比大盘股具有更高的风险,更高的潜在回报投资。理论上,在等权重的投资组合中给标准普尔500指数中较小的股票赋予更大的权重,应该会增加投资组合的回报潜力。
这些模型虽然简单直观,但过于依赖条件假设,难以个性化。自2008年有了智能投顾这个概念之后,大家越来越多的会把统计模型用于金融分析的领域中。
预期收益计算也有很多传统方法,和机器学习方法形成了两大阵营。现代投资组合理论(MPT)是由Harry Markowitz于1952年提出,是一种试图通过在收益和风险之间取得平衡来创建资产组合的理论。其基本理论是,可以在给定一定风险的情况下最大化投资组合预期收益,或者等效地降低给定收益水平的风险。
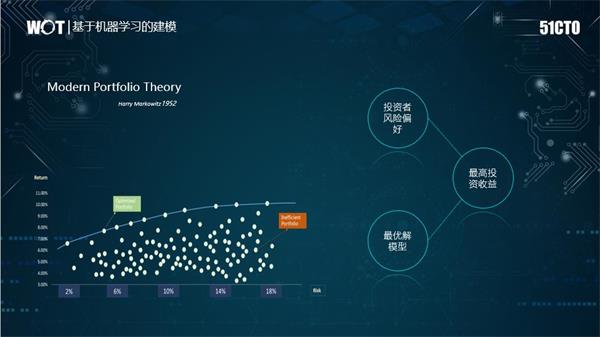
MPT的一个主要思想是,资产组合不应基于单个资产的表现,而应整体地考虑资产绩效。这意味着在评估投资组合时必须考虑投资组合的内部风险收益动态。 MPT的经典数学模型使用平均收益作为预期收益的度量,并使用收益方差作为风险度量。
根据风险调整后的收益对有效边界进行优化,并通过考虑市场收益、独立风险和相关风险的量化方法获得有效边界,从而在结构良好的低相关市场组合 中消除市场独立风险。 然后可以识别最优分配并将其应用于不同的客户。
这其中,有三个核心要素,包括Market Return(预期收益向量)、Market Risk(预期风险(协方差矩阵))、Constraints(约束条件)。
资本资产定价模型(CAPM)是由William Sharpe创建的模型,它根据市场回报和资产与市场回报的线性关系来估计资产的收益。 这种线性关系是股票的β系数。CAPM使用简单的线性回归,而FF使用具有许多自变量的多元回归。 因此,我们的3因子FF方程是lm( R_excess~MKT_RF + SMB + HML。例如,我们可以用过去 26 期周收益率数据的均值当做下周周收益率均值的预测。由于每个投资品的预测只用到自己过去的历史数据,因此这个模型是无结构性的(它相当于每个投资品自成一个因子)。此外,基于历史数据的预测是无偏的(unbiased)。
举一个例子,预测市场收益与不同宏观变量的关系,如石油,美元,波动率,消费者信心,利率等。在传统统计中,分析师会采用线性回归来计算这些变量的市场收益的β值。通过机器学习,分析师可以使用先进的回归模型计算风险,这些回归模型将考虑异常值,以稳健的方式处理大量变量,区分相关输入变量,考虑潜在的非线性效应等。通过计算机科学家开发的新算法使回归成为可能。例如,一个扩展 - 称为套索回归 - 选择输入变量的最小必要子集。另一种算法 - 称为逻辑回归 - 适用于处理数据,其中结果输出是二进制值,如“买入”或“卖出”。该方法涉及将观察组随机地划分为大小相等的k组或折叠。第一个折叠被视为验证集,并且该方法适合剩余的k-1倍。

在估计每个时间帧的协方差矩阵时,BBAE Holdings采用了机器学习方法,包括K最近邻(kNN,k-NearestNeighbor)分类算法和Lasso算法,我们发现这些方法可以提高检验结果偏差(out of specification)性能,而不是传统的估算方法。像Lasso和Ridge是对普通线性回归的简单修改,旨在在存在大量潜在相关变量的情况下创建更稳健的输出模型。当输入特征的数量很大或输入特征相关时,经典线性回归倾向于过度拟合并产生虚假系数。 LASSO,Ridge和弹性网络回归也是“正规化”的例子 - 机器学习中的一种技术,有望减少样本外的预测错误(但无助于减少样本内回溯错误)。
例如,市场状况类别可以定义为强牛、牛、中性、熊和强熊。该算法使用SVM (Support Vector Machine)和Ransom Forrest这些技术进行数据输入的处理,包括基本因素和技术因素,然后可以将其市场定义为五种类型之一。如果市场属于强牛类,则该算法可以调整(其他条件,如投资者的风险偏好可能适用)相应市场的下限约束,如果市场属于熊类,则可以减小所述市场的上限约束以控制风险暴露。

以上内容是51CTO记者根据WOT2018全球人工智能技术峰会的《数据处理》分论坛演讲内容整理,更多关于WOT的内容请关注51cto.com。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】


























