2016年1月,Netflix在全球范围内扩展,向130个国家开放服务,支持20种语言。2016年晚些时候,电视体验逐渐演变为在浏览体验期间包含视频预览。更多的成员,更多的语言和更多的视频播放将时间序列数据存储架构从***部分(https://medium.com/netflix-techblog/scaling-time-series-data-storage-part-i-ec2b6d44ba39)延伸至其突破点。在本文的第二部分中,我们将探讨该架构的局限性,并描述如何在演化的下一阶段重新构建。
突破点
***部分的架构将所有观看数据视为相同,无论类型(完整标题播放与视频预览)或年龄(标题的查看时间)。随着该功能推广到更多设备,预览与完整视图的比例迅速增长。到2016年底,我们看到该数据存储在一个季度内增长了30%; 由于对该数据存储的潜在影响,视频预览的推出被推迟。简单的解决方案是扩展底层的查看数据Cassandra(C *)集群以适应这种增长,但它已经是使用中***的集群,并且接近集群大小限制,很少有C *用户成功通过。必须要做点什么,但那太早了。
重新思考我们的设计
我们挑战自己,重新思考我们的方法,并设计出一种至少能实现5倍增长的方法。我们有可以从***部分的架构中重用的模式,但只有这些模式本身是不够的,还需要新的模式和技术。
分析
我们首先分析了数据集的访问模式,得到三种不同的数据类别:
• 完整标题播放
• 视频预览播放
• 语言偏好(即播放了哪些字幕/配音,表示成员在播放给定语言的字幕时的偏好是什么)
对于每个类别,我们发现了另一种模式——大多数访问都是针对最近的数据。随着数据年龄的增长,所需的详细程度降低。将这些见解和我们与数据消费者的对话结合起来,我们讨论了哪些数据需要详细信息以及持续多长时间。
存储效率低下
对于增长最快的数据集,视频预览和语言信息,我们的合作伙伴只需要最近的数据。我们的合作伙伴正在过滤非常短暂的视频预览视图,因为它们不是会员对内容意图的正面或负面信号。此外,我们发现大多数会员为他们观看的大多数标题选择相同的subs / dubs语言。在每个查看记录中存储相同的语言***项会导致大量数据重复。
客户端复杂性
我们研究的另一个限制因素是查看数据服务的客户端库如何满足调用者对特定时间段内特定数据的特殊需求。调用者可以通过指定来检索查看数据:
• 视频类型——完整标题或视频预览
• 时间范围——***X天/月/年,X对于各种用例不同
• 详细程度——完整或摘要
• 是否包含subs / dubs信息
对于大多数用例,在从后端服务获取完整数据后,这些过滤器应用于客户端。正如您可能想象的那样,这导致了大量不必要的数据传输。此外,对于较大的观看数据集,性能会迅速下降,导致第99个百分点的读取延迟发生巨大变化。
重新设计
我们的目标是设计一个可以扩展到5倍增长的解决方案,具有合理的成本效率和改进以及更容易预测的延迟。通过对上述问题的分析和理解,我们进行了这次重大的重新设计。以下是我们的设计指南:
数据类别
• 按数据类型分片
• 将数据字段简化为基本元素
数据时代
• 按数据年龄划分的碎片。对于最近的数据,在设置TTL后过期
• 对于历史数据,汇总并旋转到归档群集中
性能
• 并行化读取以提供跨最近和历史数据的统一抽象
群集分片
以前,我们将所有数据合并到一个集群中,客户端库根据类型/年龄/详细程度过滤数据。我们颠倒了这种方法,现在根据类型/年龄/细节水平对聚类进行分片。这样可以将每个数据集的不同增长率彼此分离,简化了客户端,并改善了读取延迟。
存储效率
对于增长最快的数据集、视频预览和语言信息,我们能够与合作伙伴保持一致,仅保留***的数据。我们不会存储非常短暂的预览视频,因为它们不是会员对内容感兴趣的良好信号。此外,我们现在存储初始语言***项,然后仅存储后续播放的增量。对于绝大多数会员而言,这意味着只存储一条语言偏好记录,从而节省大量存储空间。对于预览播放和语言偏好数据,我们也有较低的TTL,因此比完整标题播放的数据更容易过期。
如果需要,我们应用***部分中的实时和压缩技术,其中可配置数量的最近记录以未压缩的形式存储,其余记录以压缩形式存储在单独的表中。对于存储较旧数据的集群,我们将数据完全以压缩形式存储,在访问时以较低的存储成本换取较高的计算成本。
***,我们不是存储历史完整标题播放的所有细节,而是在单独的表中存储具有较少列的汇总视图。此摘要视图也经过压缩,可进一步优化存储成本。
总的来说,我们的新架构如下所示:
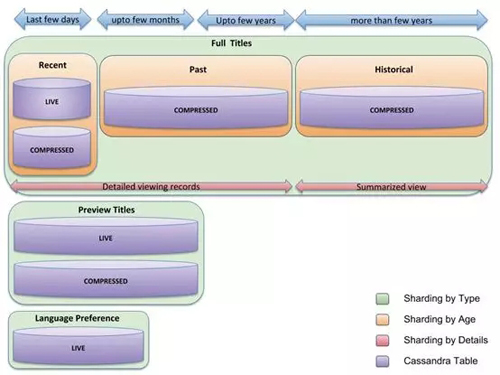
查看数据存储架构
如上所示,查看数据存储是按类型分片的——有完整标题播放、预览标题播放和语言***项的单独集群。在完整的标题播放中,存储按年龄分类。对于最近查看数据(最近几天)、过去查看数据(几天到几年)和历史查看数据都有单独的集群。***,历史查看数据只有一个摘要视图,没有详细的记录
数据流
写入
将数据写入到最近的集群中。在输入之前应用过滤器,例如不存储非常短的视频预览播放或将播放的字幕/配音与以前的***项进行比较,并且仅在与先前行为发生变化时存储。
读取
对***数据的请求直接转到***的集群。当请求更多数据时,并行读取可以实现高效检索。
查看数据的***几天:对于绝大多数需要几天完整标题播放的用例,信息仅从“最近”集群中读取。执行对集群中LIVE和COMPRESSED表的并行读取。继续本博文系列***部分详细介绍的实时和压缩数据集的模式,如果记录数超出可配置的阈值,则在从LIVE读取期间,将记录汇总,压缩并写入COMPRESSED表作为具有相同行键的新版本。
另外,如果需要语言偏好信息,则对“语言偏好”集群进行并行读取。同样,如果需要预览播放信息,则会对“预览标题”集群中的LIVE和COMPRESSED表进行并行读取。与完整标题查看数据类似,如果LIVE表中的记录数超过可配置阈值,则记录将被汇总,压缩并作为具有相同行键的新版本写入COMPRESSED表。
通过对“最近”和“过去”群集的并行读取,可以启用最近几个月的完整标题播放。
汇总的查看数据通过并行读取 “最近”,“过去”和“历史”集群返回。然后将数据拼接在一起以获得完整的汇总视图。为了减少存储大小和成本,“历史”集群中的汇总视图不包含成员查看的***几年的更新,因此需要通过汇总来自“最近”和“过去”集群的查看数据来进行扩充。
数据轮换
对于完整的标题播放,不同年龄组之间的记录移动是异步发生的。在从“最近”集群中读取会员的查看数据时,如果确定存在超过配置天数的记录,则任务排队以将该会员的相关记录从“最近”移动到“过去”集群。在任务执行时,相关记录与“过去”集群中COMPRESSED表的现有记录组合在一起。然后压缩组合的记录集并将其存储在具有新版本的COMPRESSED表中。新版本写入成功后,将删除先前的版本记录。
如果压缩后的新版本记录集的大小大于可配置的阈值,则将记录集分块并且多个块被并行写入。这些记录从一个集群到另一个集群的后台传输是批处理的,因此每次读取时都不会触发它们。所有这些都类似于***部分中详述的实时压缩存储方法中的数据移动。
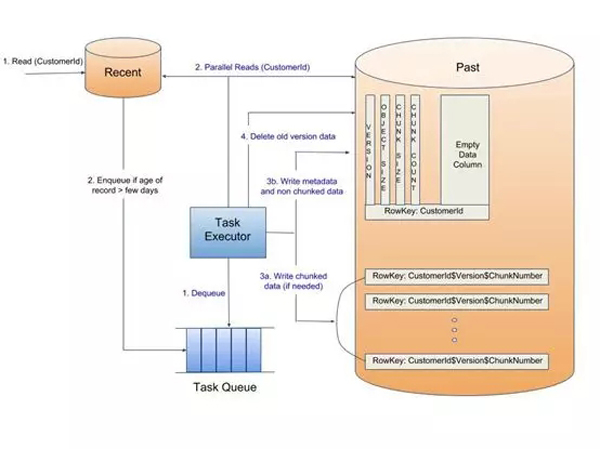
群集之间的数据轮换
类似的记录到“历史”集群的移动是在读取“过去”集群时完成的。使用现有摘要记录重新处理相关记录以创建新的摘要记录。然后将它们压缩并写入具有新版本的“历史”集群中的COMPRESSED表。成功写入新版本后,将删除以前的版本记录。
性能调优
与之前的体系结构一样,LIVE和COMPRESSED记录存储在不同的表中,并进行不同的调整以获得更好的性能。由于LIVE表具有频繁的更新和少量的查看记录,因此压缩会频繁运行,并且gc_grace_seconds很小,以减少SSTable的数量和数据大小。经常运行读取修复和全列族修复以提高数据一致性。由于对COMPRESSED表的更新很少,因此手动和不频繁的完全压缩足以减少SSTable的数量。在罕见的更新期间检查数据的一致性。这样就不需要进行读取修复以及全列修复。
缓存层更改
由于我们对来自Cassandra的大数据块进行了大量并行读取,因此拥有缓存层有很大的好处。EVCache缓存层架构也进行了更改,以模拟后端存储架构,如下图所示。所有缓存都有接近99%的***率,并且在最小化对Cassandra层的读取请求数量方面非常有效。
缓存层架构
缓存和存储体系结构之间的一个区别是“摘要”缓存集群存储整个查看数据的压缩摘要以进行完整标题播放。缓存***率约为99%,只有一小部分请求被发送到Cassandra层,在该层中,需要并行读取3个表,并将记录拼接在一起,以便跨整个查看数据创建摘要。
迁移:初步结果
团队已经完成了一半以上的更改。已经迁移了利用按数据类型分片的用例。因此,虽然我们没有完整的结果可以分享,但初步的结果和经验教训如下:
• Cassandra的操作特性(压缩,GC压力和延迟)的大幅改进仅基于按数据类型分割群集。
• 完整标题的巨大空间,查看数据Cassandra集群,使团队能够扩展至少5倍的增长。
• 由于更积极的数据压缩和数据TTL,大幅节省了成本。
• 重新架构是向后兼容的。现有的API将继续有效工作,并且预计会有更好和更可预测的延迟。为访问数据子集而创建的新API将带来显着的额外延迟优势,但需要更改客户端。这使得在独立于客户端更改的情况下推出服务器端更改变得更加容易,并且可以根据客户端的业务带宽在不同的时间迁移不同的客户端。
结论
在过去几年中,查看数据存储架构已经取得了很大的进步。我们逐步发展到使用实时数据和压缩数据并行读取的模式来查看数据存储,并将该模式用于团队中的其它时间序列数据存储需求。最近,我们对存储集群进行了分片,以满足不同用例的独特需求,并为一些集群使用了实时和压缩数据模式。我们扩展了实时和压缩数据移动模式,以便在年龄分片群集之间移动数据。
设计这些可扩展的构建块以一种简单而有效的方式扩展我们的存储层。虽然我们重新设计了5倍于当前用例增长的产品,但我们知道Netflix的产品体验在不断变化和改进。我们也正密切关注可能需要进一步进化的变化。