随着闲鱼业务的发展,用户规模达到数亿级,用户维度的数据指标,达到上百个之多。
如何从亿级别的数据中,快速筛选出符合期望的用户人群,进行精细化人群运营,是技术需要解决的问题。业界的很多方案常常需要分钟级甚至小时级才能生成查询结果。
本文提供了一种解决大数据场景下的高效数据筛选、统计和分析方法,从亿级别数据中,任意组合查询条件,筛选需要的数据,做到毫秒级返回。
技术选型分析
从技术角度分析,我们这个业务场景有如下特点:
- 需要支持任意维度的组合(and/or)嵌套查询,且要求低延迟。
- 数据规模大,至少亿级别,且需要支持不断扩展。
- 单条数据指标维度多,至少上百,且需要支持不断增加。
综合分析,这是一个典型的 OLAP 场景。
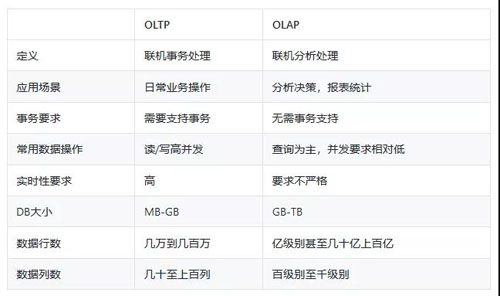
OLTP 与 OLAP
下面简单对比下 OLTP 和 OLAP:
最常见的数据库,如 MySQL、Oracle 等,都采用行式存储,比较适合 OLTP。
如果用 MySQL 等行数据库来实现 OLAP,一般都会碰到两个瓶颈:
- 数据量瓶颈:MySQL 比较适合的数据量级是百万级,再多的话,查询和写入性能会明显下降。因此,一般会采用分库分表的方式,把数据规模控制在百万级。
- 查询效率瓶颈:MySQL 对于常用的条件查询,需要单独建立索引或组合索引。非索引字段的查询需要扫描全表,性能下降明显。
综上分析,我们的应用场景,并不适合采用行存储数据库,因此我们重点考虑列存数据库。
行式存储与列式存储
下面简单对比一下行式存储与列式存储的特点:
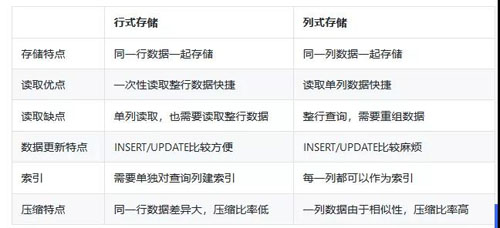
行存适合近线数据分析,比如要求查询表中某几条符合条件的记录的所有字段的场景。
列存适合用于数据的统计分析。考虑如下场景:一个用于存放用户的表中有 20 个字段,而我们要统计用户年龄的平均值,如果是行存,则要全表扫描,遍历所有行。
但如果是列存,数据库只要定位到年龄这一列,然后只扫描这一列的数据就可以得到所有的年龄,计算平均值,性能上相比行存理论上就会快 20 倍。
而在列存数据库中,比较常见的是 HBase。HBase 应用的核心设计重点是 rowkey 的设计,一般要把常用的筛选条件,组合设计到 rowkey 中,通过 rowkey 的 get(单条记录) 或者 scan(范围) 查询。
因此 HBase 比较适合有限查询条件下的非结构化数据存储。而我们的场景,由于所有字段都需要作为筛选条件,所以本质上还是需要结构化存储,且要求查询低延迟,因此也无法使用 HBase。
我们综合考虑集团内多款列式存储的 DB 产品(ADS/PostgreSQL/HBase/HybridDB)。
综合评估读写性能、稳定性、语法完备程度及开发和部署成本,最终选择了 HybridDB for MySQL 计算规格来构建人群圈选引擎。
HybridDB for MySQL 介绍
HybridDB for MySQL 计算规格对我们的这个场景而言,核心能力主要有:
- 任意维度智能组合索引(使用方无需单独自建索引)。
- 百亿大表查询毫秒级响应。
- MySQL BI 生态兼容,完备 SQL 支持。
- 空间检索、全文检索、复杂数据类型(多值列、JSON)支持。
那么,HybridDB for MySQL 计算规格是如何做到大数据场景下的任意维度组合查询的毫秒级响应的呢?
步骤如下:
- 首先是 HybridDB 的高性能列式存储引擎,内置于存储的谓词计算能力,可以利用各种统计信息快速跳过数据块实现快速筛选。
- 第二是 HybridDB 的智能索引技术,在大宽表上一键自动全索引并根据列索引智能组合出各种谓词条件进行过滤。
- 第三是高性能 MPP+DAG 的融合计算引擎,兼顾高并发和高吞吐两种模式实现了基于 pipeline 的高性能向量计算,并且计算引擎和存储紧密配合,让计算更快。
- 第四是 HybridDB 支持各种数据建模技术例如星型模型、雪花模型、聚集排序等,业务适度数据建模可以实现更好的性能指标。
综合来说,HybridDB for MySQL 计算规格是以 SQL 为中心的多功能在线实时仓库系统,很适合我们的业务场景,因此我们在此之上构建了我们的人群圈选底层引擎。
业务实现
在搭建了人群圈选引擎之后,我们重点改造了我们的消息推送系统,作为人群精细化运营的一个重要落地点。
闲鱼消息推送简介
消息推送(PUSH)是信息触达用户最快捷的手段。闲鱼比较常用的 PUSH 方式,是先离线计算好 PUSH 人群、准备好对应 PUSH 文案,然后在第二天指定的时间推送。
一般都是周期性的 PUSH 任务。但是临时性的、需要立刻发送、紧急的 PUSH 任务,就需要 BI 同学介入,每个 PUSH 任务平均约需要占用 BI 同学半天的开发时间,且操作上也比较麻烦。
本次我们把人群圈选系统与原有的 PUSH 系统打通,极大地改善了此类 PUSH 的准备数据以及发送的效率,解放了开发资源。
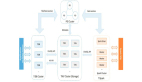
系统架构
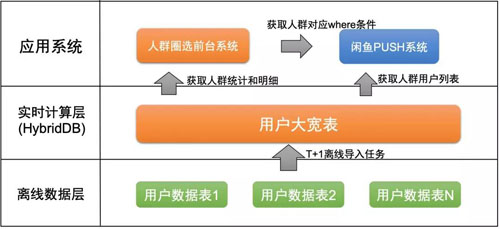
离线数据层:用户维度数据,分散在各个业务系统的离线表中。我们通过离线 T+1 定时任务,把数据汇总导入到实时计算层的用户大宽表中。
实时计算层:根据人群的筛选条件,从用户大宽表中,查询符合的用户数量和用户 ID 列表,为应用系统提供服务。
人群圈选前台系统:提供可视化的操作界面。运营同学选择筛选条件,保存为人群,用于分析或者发送 PUSH。
每一个人群,对应一个 SQL 存储,类似于:
- select count(*) from user_big_table where column1> 1 and column2 in ('a','b') and ( column31=1 or column32=2)
同时,SQL 可以支持任意字段的多层 and/or 嵌套组合。用 SQL 保存人群的方式,当用户表中的数据变更时,可以随时执行 SQL,获取最新的人群用户,来更新人群。
闲鱼 PUSH 系统:从人群圈选前台系统中获取人群对应的 where 条件,再从实时计算层,分页获取用户列表,给用户发送 PUSH。在实现过程中,我们重点解决了分页查询的性能问题。
分页查询性能优化方案:在分页时,当人群的规模很大(千万级别)时,页码越往后,查询的性能会有明显下降。
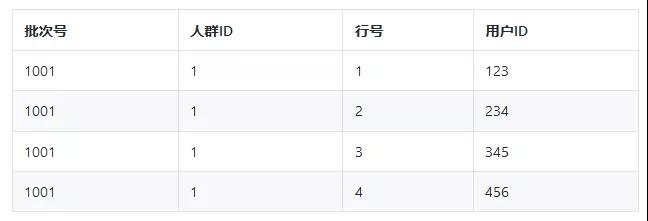
因此,我们采用把人群数据增加行号、导出到 MySQL 的方式,来提升性能。
表结构如下:
- 批次号:人群每导出一次,就新加一个批次号,批次号为时间戳,递增。
- 行号:从 1 开始递增,每一个批次号对应的行号都是从 1 到 N。
我们为"人群 ID"+"批次号"+"行号"建组合索引,分页查询时,用索引查询的方式替换分页的方式,从而保证大页码时的查询效率。
另外,为此额外付出的导出数据的开销,得益于 HybridDB 强大的数据导出能力,数据量在万级别至百万级别,耗时在秒级至几十秒级别。综合权衡之后,采用了本方案。
PUSH 系统改造收益

人群圈选系统为闲鱼精细化用户运营提供了强有力的底层能力支撑。同时,圈选人群,也可以应用到其他的业务场景,比如首页焦点图定投等需要分层用户运营的场景,为闲鱼业务提供了很大的优化空间。
本文实现了海量多维度数据中组合查询的秒级返回结果,是一种 OLAP 场景下的通用技术实现方案。
同时介绍了用该技术方案改造原有业务系统的一个应用案例,取得了很好的业务结果,可供类似需求或场景的参考。
未来
人群圈选引擎中的用户数据,我们目前是 T+1 导入的。这是考虑到人群相关的指标,变化频率不是很快,且很多指标(比如用户标签)都是离线 T+1 计算的,因此 T+1 的数据更新频度是可以接受的。
后续我们又基于 HybridDB 构建了更为强大的商品圈选引擎。闲鱼商品数据相比用户数据,变化更快。
一方面用户随时会更新自己的商品;另一方面,由于闲鱼商品单库存(售出即下架)的特性,以及其他原因,商品状态会随时变更。
因此我们的选品引擎,应该尽快感知到这些数据的变化,并在投放层面做出实时调整。
我们基于 HybridDB(存储)和实时计算引擎,构建了更为强大的“马赫”实时选品系统。
参考资料:
HybridDB for MySQL 介绍:http://click.aliyun.com/m/1000027814/