前几天看到强哥(“纯洁的微笑”)转载的一篇文章《如何判断一个元素是否在亿级数据是否存在》。对其中的解决思路有一些不一样的想法,先阐述一下问题:
| 现在有一个非常庞大的数据,假设全是 int 类型。给出一个数,判断这个数是否在其中(尽可能的高效)。 |
题目要求
文章给出了思路:首先想到的是 Hash 算法,它的时间复杂度是 O(1),在常量时间判断出数据是否存在。文章给出的办法是直接使用了 Java 的集合对象 HashSet(内部用 HashMap 实现)。文章给出的结论是装载数据太慢,直接讨论了后面的一种方法—— Bloom Filter。***发现 Bloom Filter 也不可能***解决这个问题,有“误判”。
总结一下题目的要求:
- 装载数据尽可能的快
- 查询速度尽可能的块
- 数据判断不存在误判
算法复杂度上考虑,***的是 O(1)在常量级时间内完成查找,以及基于 Hash 算法。所以我的解决思路也是采用 Hash。
现代 CPU 多流水线完成 1000W 次循环是非常快的,所以理论上是“装载数据”应该是非常块的。上面文章中提到的装载数据太慢其实是由于HashSet 的 put 方法里面有复杂的逻辑——毕竟 HashSet 是一个通用的 Hash 算法。
新思路
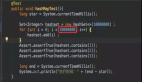
1000W 条数据,我们可以用 1000W 个二进制位表示,初始化为全 0 如果某个数据存在,就置为 1。。Java 中没有办法直接操作一大块连续内存空间,我用一个 int 类型的数组表示,每个数组元素可以表示 32 个元素。比如分别装载 5、13、29(注意:字节顺序)。

这些数据都小于 32,放在***个数组元素就可以了。代码如下:

1000W 条数据有可能是在 1-100 以内取,只需要 100 个 bit 就可以了;也可能是在 1-1000W 以内取,此时需要 1000W 个 bit。所以单独用一个变量boundOfData表示数据的上限,需要的 bit 数量则是 boundOfData,每个 int 是 32 个 bit ,计算需要的数组数量是boundOfData/32 后向上取整。
数据除32 商是数组下标,余数是相应的 bit 位置。比如 10,它应该在***个数组元素的,第 10 个 bit 位,定位到位置后只要通过位运算设置为 1 就行了。判断的时候只要按同样的算法定位到数组位置,判断某个 bit 为是否为 1。
我们测试一下速度,某次执行结果

分析一下算法:
装载数据部分是 O(N)——即线性复杂度,这个是没有办法避免的。查询部分是 O(1)——常量级。当然这里肯定不会存在“误判”,因为每个数据都会被准确的 Hash。
看一下空间复杂度,1000W 的数据需要 312500 个 int 类型的数据大概是 1.1M 内存空间。
我尝试了 1 一条数据,大概 13 秒;如果不用随机数(直接用下标)大概是 200 ms。
总结
其实面试问题很多情况下不是考察你是否知道答案,而是解题过程。希望在信息爆炸的今天,我们能够静下心来分析一个问题,仔细思考它的答案。
答案是什么?谁还在乎这个,我们思考的过程才是最有价值的部分。
【本文是51CTO专栏作者“邢森”的原创文章,转载请联系作者本人获取授权】