













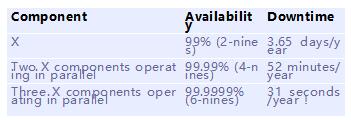
我们在评估一个系统的可用性和可靠性时,一般都会说三个9,四个9之类的。这些一般都是说系统的SLA(Service Level Agreement) 具体是几个「9」,以此,来表示该系统一年中具体宕机的时间。
那这几个9是怎么计算出来的,具体一个系统可用性和可靠性又有哪些方面考虑呢?
以下是朋友推荐的一篇很棒的英文文章,我做了翻译。
一、系统可用性
系统可用性是通过将系统建模为串联和并联的组件来计算的。以下规则用于确定系统是串联的还是并联的:
- 如果组件的失效导致组合变得不可操作,则认为这两个部件是串联操作的
- 如果组件的故障导致另一部件接管故障部件的操作,则认为这两部件并行操作。
1. 串行的可用性

如上图所示,两个组件 X 和 Y,如果有一个出问题导致整个组合都不可用,就认为 X 和 Y 这两个组件是串联的。只有组件 X 和组件 Y 同时可用时,整个组合才可用。由此可见,组合的可用性是这两部分的乘积,公式如下:
A = Ax Ay
从上面的等式我们看出,串联系统中,整体组合的可用性,总是低于单个组件的可用性。
对于上面 X 和 Y 两个串联组件,可用性如下:

从上面的表中,我们看到,即使使用了非常高可用性的组件Y,但组合系统仍然受组件 X 的影响,会降低好多,和「木桶原理」一致,都受最短板的影响。
2. 并行的可用性

如上图所示,如果两个组件都失败时,整个系统会失败的话,这两个组件会被认为是并行的。任一组件可用时,整个系统都是可用的。整体可用性是 1- (两个组件都不可用),公式如下:
A = 1-(1-Ax )2
从上面我们能看出,两个组件并行的系统,整体可用性要任一单独的组件可用性高。如上图假设是组件X的两个部分,可用性如下:
我们看到,即使一个可用性低的组件X,组合后的系统可用性也很高。
二、可用性计算举例
1. 了解系统
***步,我们先准备一个系统的详细框图。该系统由输入传感器组成,该传感器接收信号并将其转换为适合信号处理器的数据流。输出会送到两个冗余的信号处理器。源信号处理器用于输入,备用信号处理器忽略来自输入换能器的数据。备用处理器监控主信号处理器的健康状态。两个信号处理器的输出被组合并发送到输出转换器。再次,有源信号处理器驱动数据线。待机使数据线保持不变。输出传感器将信号输出到外部。
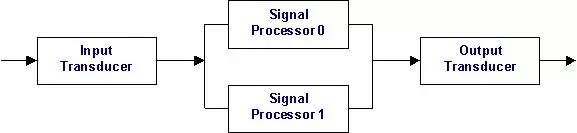
2. 系统可靠性
第二步是准备系统的可靠性模型。在这个阶段,我们决定系统的并行和串行连接。我们的示例系统的完整可靠性模型如下:
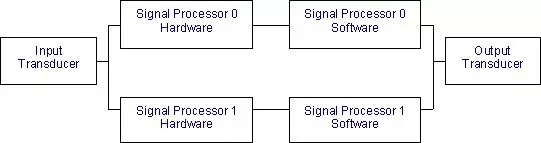
这里要注意的几个要点是:
- 信号处理器的硬件和软件已经被建模为两个不同的实体。软件和硬件是串联的,因为如果硬件或软件不工作,信号处理器就不能工作。
- 两个信号处理器(软件+硬件)结合在一起,形成信号处理复合体。在信号处理复合体中,两个信号处理复合体被并行放置,因为当信号处理器之一失效时,系统可以工作。
- 输入传感器、信号处理复合体和输出传感器被串联放置,因为三个部件中的任何一个的失效都将导致系统的完全失效。
3. 计算单个组件的可用性
第三步包括计算单个组件的可用性。MTBF(Mean time between failure 故障之间的平均时间)和MTTR(Mean time to repair 修复的平均时间)值针对每个组件进行估计。对于硬件组件,MTBF信息可以从硬件制造商的数据表中获得。如果硬件是在内部开发的,则硬件组将为板提供MTBF信息。对硬件的MTTR估计基于操作员对系统的监视程度。这里我们估计大约2小时的硬件MTTR。
一旦已知MTBF和MTTR,就可以使用以下公式来计算组件的可用性:
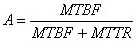
评估软件的MTBF 这个活儿还是比较费劲的。软件MTBF实际上是软件重新启动的时间。中间的间隔可以用系统的缺陷率来估计。在这里,我们估计MTBF大约是4000小时。MTTR是重新启动失败处理器的时间。我们的处理器支持自动重启,所以我们估计软件MTTR大约5分钟。请注意,5分钟似乎是在更高的一面。但MTTR应包括以下内容:
- 由于信号处理器软件崩溃而中止的活动中浪费的时间
- 检测信号处理器故障的时间
- 失败的处理器重新启动并返回服务时所花费的时间
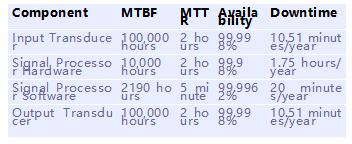
从上面表格我们看到
- 即使硬件MTBF更高,软件的可用性也更高。主要原因是软件的MTTR要低得多。换句话说,软件确实经常失败,但是恢复很快,因此对系统可用性的影响较小。
- 输入和输出传感器具有相当高的可用性,因此即使在没有冗余组件的情况下也能够实现相当高的可用性。
4. 计算系统可用性
***一步是计算整个系统的可用性。这些计算是基于串行和并行可用性计算公式。

三、怎么做到更多的9
每个公司对几个9的定义都不一样,好多的互联网公司要求都是99.99。像一些事业单位网站,办事网站等,经常故障服务不可用,估计***也就到99.9。
如果我们提供的服务可用性越低,意味着造成的损失也越大,别的不说,如果是特别重要的时刻,或许就在某一分钟,你可能就会因服务不可用而丢掉一笔大的订单,这都是始料未及的。所以,只要尽可能的提升SLA可用性才能***化的提高企业生产力。
要做到更多的9,就需要监控自己的服务,在服务出现异常或者宕机的时候,能及时恢复。增加冗余,防止出现问题。













