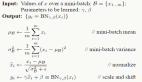【51CTO.com原创稿件】
1.前言
11月1日,百度发布了Paddle Fluid的1.1版本,作为国内***深度学习框架,PaddlePaddle对中文社区非常友好,有完善的中文社区、项目为导向的中文教程,可以让更多中文使用者更方便地进行深度学习、机器学习相关的研究和实践。我本人也非常希望PaddlePaddle能够不断发展壮大,毕竟这是国内公司为开源社区做出的一项非常有意义的贡献。为了一探Paddle Fluid 1.1版本究竟做了哪些方面的更新,笔者***时间安装了新发布的版本,用一个基于SSD的目标检测任务来测试一下新版PaddlePaddle的表现。
2.什么是目标检测
图像识别对于做视觉的同学来说应该是一个非常熟悉的任务了,最初深度学习就是是应用于图像识别任务的,举例来说,给计算机一张汽车图片,让它判断这图片里有没有汽车。
对于背景干净的图片来说,这样做很有意义也比较容易。但是如果是一张包含丰富元素的图片,不仅识别难度大大提高,仅仅判断出里面有没有图片的意义也不大了,我们需要找到到底在读片的什么位置出现了一辆汽车,这就提出了一个新的任务和需求——目标检测。
我们的任务就是给定一张图像或是一个视频帧,让计算机找出其中所有目标的位置,并给出每个目标的具体类别。对于人类来说,目标检测是一个非常简单的任务。然而,计算机能够“看到”的是图像被编码之后的数字,很难解图像或是视频帧中出现了人或是物体这样的高层语义概念,也就更加难以定位目标出现在图像中哪个区域。
与此同时,由于目标会出现在图像或是视频帧中的任何位置,目标的形态千变万化,图像或是视频帧的背景千差万别,诸多因素都使得目标检测对计算机来说是一个具有挑战性的问题。目前主流的方法是FasterRCNN、YOLO和SSD,本文使用SSD进行实验。
3.PaddlePaddle简介
***次听到PaddlePaddle是在CCF前线研讨会上,当时几个人聊起来关于机器学习算法平台的事情,有一位小伙伴提起了这个名字,所以一段时间以来我一直认为这是一个机器学习算法平台。直到16年百度开源了PaddlePaddle我才知道,原来这是一个可以跟TensorFlow媲美的深度学习框架,主打“易用、高效、灵活、可扩展”。所以,简单来说,PaddlePaddle就是百度自研的一套深度学习框架(看过发布会后了解到,百度为此建立了一套覆盖面非常广的生态,包括金融、推荐、决策等,但笔者主要是对PaddlePaddle的核心框架进行测评,不在此浪费过多笔墨了)。
3.1如何安装
笔者的工作站是Ubuntu 16.04系统,PaddlePaddle在CentOS和Ubuntu都支持pip安装和docker安装,GPU版本在Linux下也可以***适配。下面来看一下具体的安装步骤。
首先我们使用cat /proc/cpuinfo | grep avx2来查看我们的Ubuntu系统是否支持avx2指令集,如果发现系统返回了如下一系列信息,就说明系统是支持avx2指令集的,可以放心进行后续安装。如果不支持也没关系,在官网上可以直接下载no_avx的whl包进行安装。

接下来使用pip安装***的Fluid v1.1版本的PaddlePaddle(GPU),在安装前注意,需要在机器上安装python3.5-dev才可以用pip安装PaddlePaddle。下载速度会比较慢,需要20分钟左右的下载时间。

安装完成后,在python里import paddle测试一下,如果成功导入则说明安装成功!

在更新的Paddle Fluid v1.1版本中还特意优化了对MacOS的支持,可以直接通过pip安装,也可以用源码编译安装。具体细节可参考:http://www.paddlepaddle.org/documentation/docs/zh/1.1/beginners_guide/install/Start.html
3.2PaddlePaddle的计算描述方式
框架的计算描述方式是深度学习项目开发者非常关注的一个问题。计算的描述方式经历了从Caffe1.0时代的一组连续执行的layers到TensorFlow的变量和操作构成的计算图再到PaddlePaddle Fluid[1]提出不再有模型的概念一系列的演变。那么PaddlePaddle现在是怎么描述计算的呢?
PaddlePaddle使用Program来描述模型和优化过程,可以把它简单理解为数据流的控制过程。Program由Block、Operator和Variable构成,variable和operator被组织成为多个可以嵌套的block。具体的,如果要实现一个神经网络,我们只需要通过添加必要的variable、operator来定义网络的前向计算,而反向计算、内存管理、block创建都由框架来完成。下面展示一下如何在PaddlePaddle中定义program:
以一个简单的线性回归为例,我们这样定义前向计算逻辑:
#定义输入数据类型 x = fluid.layers.data(name="x",shape=[1],dtype='float32') #搭建全连接网络 y_predict = fluid.layers.fc(input=x,size=1,act=None)
定义好计算逻辑后,与TensorFlow一样,下一步就需要定义损失函数,feed数据,开始训练,feed数据也是在执行运算的时候进行,我们先定义一下数据,这里train_data 就是我们的输入数据,y_true是label:
train_data=numpy.array([[1.0],[2.0],[3.0],[4.0]]).astype('float32')
y_true = numpy.array([[2.0],[4.0],[6.0],[8.0]]).astype('float32')
添加均方误差损失函数(MSE),框架会自动完成反向计算:
cost = fluid.layers.square_error_cost(input=y_predict,label=y) avg_cost = fluid.layers.mean(cost)
执行我们定义的上述Program:
cpu = fluid.core.CPUPlace()
exe = fluid.Executor(cpu)
exe.run(fluid.default_startup_program())
#开始训练
outs = exe.run(
feed={'x':train_data,'y':y_true},
fetch_list=[y_predict.name,avg_cost.name])
#观察结果
print outs
输出结果:
[array([[0.9010564], [1.8021128], [2.7031693], [3.6042256]], dtype=float32), array([9.057577], dtype=float32)]
这样就用PaddlePaddle实现了简单的计算流程,个人感觉使用起来跟TensorFlow的相似度较高,习惯在TensorFlow上跑模型的小伙伴应该很容易适应PaddlePaddle的这一套生态。
关于PaddlePaddle计算描述的详情可以参考Fluid编程指南:http://www.paddlepaddle.org/documentation/docs/zh/1.1/beginners_guide/programming_guide/programming_guide.html
3.3PaddlePaddle的模型库简介
PaddlePaddle的核心框架内置了非常多的经典模型和网络,涵盖了几乎所有主流的机器学习/深度学习任务,包括图像、语音、自然语言处理、推荐等诸多方面。因为本文是做目标检测,所以主要调研了一下图像方面的模型库,在此大致介绍一下。
3.3.1分类
分类任务中的模型库是最全面的,AlexNet、VGG、GoogleNet、ResNet、Inception、MobileNet、Dual Path Network以及SE-ResNeXt,2012年以来的经典图像识别网络都包含其中,每个网络模型是一个独立的py文件,里面是这个网络模型的类,类里面公用的方法是net(),在调用时初始化对应的类之后调用.net()方法,就可以得到对应网络的Program描述,之后只需要给网络feed数据、定义损失函数、优化方法等就可以轻松使用了。分类模型作为图像任务的基础任务,在目标检测、语义分割等任务中都会重复利用这些模型,所以这样一个模型库可以为大大简化后续任务的开发工作。这部分的模型库里的写法比较统一,只要了解网络结构,用.net()方法调用就可以,这里就不一一介绍了,具体可以参考:https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/image_classification/models。
3.3.2目标检测
SSD
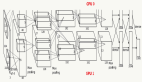
Single Shot MultiBox Detector (SSD) 是一种单阶段的目标检测器。与两阶段的检测方法不同,单阶段目标检测并不进行区域推荐,而是直接从特征图回归出目标的边界框和分类概率。SSD 运用了这种单阶段检测的思想,并且对其进行改进:在不同尺度的特征图上检测对应尺度的目标。如下图所示,SSD 在六个尺度的特征图上进行了不同层级的预测。每个层级由两个3x3卷积分别对目标类别和边界框偏移进行回归。因此对于每个类别,SSD 的六个层级一共会产生 38x38x4 + 19x19x6 + 10x10x6 + 5x5x6 + 3x3x4 + 1x1x4 = 8732 个检测结果。
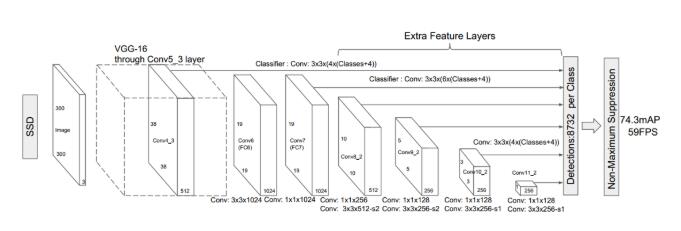
SSD 目标检测模型
SSD 可以方便地插入到任何一种标准卷积网络中,比如 VGG、ResNet 或者 MobileNet,这些网络被称作检测器的基网络。PaddlePaddle里的SSD使用Google的MobileNet作为基网络。
目标检测模型库不同于分类模型库,PaddlePaddle是以一个工程的形式提供SSD的模型库。工程里面包含如下文件:
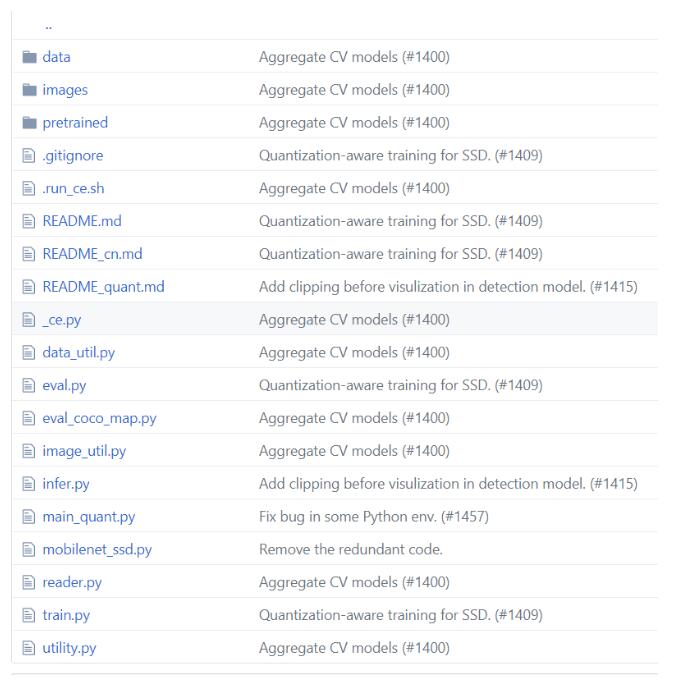
其中,train.py、reader.py、mobilenet_ssd.py是与网络训练相关的文件,包括数据读取、网络结构、训练参数等过程的定义都在这3个文件中;eval.py、eval_coco_map.py是网络预测评估相关文件;infer.py是可视化预测结果相关文件。Data文件夹用于存储数据集,使用时可以把训练集、测试集、验证集放在data目录下,reader会在data目录下寻找图片数据加载;pretrained目录存放预训练模型,如果不想从头训练一个SSD,可以把预训练好的模型放在这个目录下,方便进行迁移学习。
4.PaddlePaddle实现SSD的目标检测
有了上述的一些基础,我们就可以轻松使用PaddlePaddle上手一些项目了。现在我们就来实现一个基于SSD的目标检测任务。
4.1服务器配置
系统:Ubuntu 16.04
GPU:NVIDIA GTX 1080*4 显存:8GB
环境:python 3.5
4.2框架配置
Paddle Fluid v1.1 GPU版本
4.3数据准备
我们使用微软的COCO2017数据集来预训练模型(PaddlePaddle提供了一个基于COCO的预训练模型,可以直接使用),COCO数据集是微软团队获取的一个可以用来图像recognition+segmentation+captioning 数据集,其官方说明网址:http://mscoco.org/。微软在ECCV Workshops里发表文章《Microsoft COCO: Common Objects in Context》更充分地介绍了该数据集。COCO以场景理解为目标,从复杂场景中截取了328,000张影像,包括了91类目标和2,500,000个label。整个COCO2017数据集20G,官网下载非常慢,可以在国内找一些镜像站下载,数据集里分好了训练集、测试集和验证集,标注和file_list用json文件保存。

拿到预训练数据集后,我们在Pascal VOC数据集上对模型进行进一步训练,做一下微调。Pascal VOC数据集相较COCO数据集来说图片数量和种类小很多,共计20类,11540张训练图片,标注采用xml格式文件保存。
4.4数据读取
图片格式为jpg,需要对图像进行转码读取,SSD中的reader.py文件帮助我们实现了这个功能,内置的数据读取使用了一个生成器来逐个batch读取图片并转码,这样内存占用率非常低。由于我们机器内存不大,设置的batch为32,在此情况下load十万张图片的annotation只需要17秒左右,每一个batch的load+train时间只需要0.3秒左右。
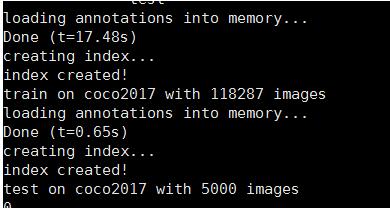
可以看一下这个reader的核心代码:
def reader():
if mode == 'train' and shuffle:
np.random.shuffle(images)
batch_out = []
for image in images:
image_name = image['file_name']
image_path = os.path.join(settings.data_dir, image_name)
im = Image.open(image_path)
if im.mode == 'L':
im = im.convert('RGB')
im_width, im_height = im.size
im_id = image['id']
# layout: category_id | xmin | ymin | xmax | ymax | iscrowd
bbox_labels = []
annIds = coco.getAnnIds(imgIds=image['id'])
anns = coco.loadAnns(annIds)
for ann in anns:
bbox_sample = []
# start from 1, leave 0 to background
bbox_sample.append(float(ann['category_id']))
bbox = ann['bbox']
xmin, ymin, w, h = bbox
xmax = xmin + w
ymax = ymin + h
bbox_sample.append(float(xmin) / im_width)
bbox_sample.append(float(ymin) / im_height)
bbox_sample.append(float(xmax) / im_width)
bbox_sample.append(float(ymax) / im_height)
bbox_sample.append(float(ann['iscrowd']))
bbox_labels.append(bbox_sample)
im, sample_labels = preprocess(im, bbox_labels, mode, settings)
sample_labels = np.array(sample_labels)
if len(sample_labels) == 0: continue
im = im.astype('float32')
boxes = sample_labels[:, 1:5]
lbls = sample_labels[:, 0].astype('int32')
iscrowd = sample_labels[:, -1].astype('int32')
if 'cocoMAP' in settings.ap_version:
batch_out.append((im, boxes, lbls, iscrowd,
[im_id, im_width, im_height]))
else:
batch_out.append((im, boxes, lbls, iscrowd))
if len(batch_out) == batch_size:
yield batch_out
batch_out = []
可以看到,这里的reader是一个生成器,逐个batch把数据load进内存。在数据读取过程中,需要注意一下几点:
1. 数据集需要放在项目的data目录下,reader通过annotations下的instances_train2017.json文件区分训练集和验证集,不需要在data目录下用文件夹区分训练集和验证集。
2. 如果数据没有按要求保存,则需要在reader.py修改数据路径:
class Settings(object): def __init__(self, dataset=None, data_dir=None, label_file=None, resize_h=300, resize_w=300, mean_value=[127.5, 127.5, 127.5], apply_distort=True, apply_expand=True, ap_version='11point'): self._dataset = dataset self._ap_version = ap_version # 把data_dir替换为数据所在路径 self._data_dir = data_dir if 'pascalvoc' in dataset: self._label_list = [] label_fpath = os.path.join(data_dir, label_file) for line in open(label_fpath): self._label_list.append(line.strip())
1. 如果遇到NoneType is not iterable的错误,一般是由于数据读取错误导致的,仔细检查文件路径应该可以解决。
2. 读取PascalVOC数据集用reader.py文件中的pascalvoc()函数,两个数据集的文件结构和标注不太一样,Paddle为我们写好了两个版本数据集的读取方法,可以直接调用。
4.5模型训练
数据读取完成后,就可以着手开始模型的训练了,这里直接使用PaddlePaddle SSD model里面的train.py进行训练:
python -u train.py
train.py里为所有的超参数都设置了缺省值,不熟悉PaddlePaddle参数调整的工程师可以直接用缺省参数进行训练,非常方便。如果需要,可以根据下表进行对应超参数的修改:
|
参数名 |
类型 |
意义 |
|
learning_rate |
Float |
学习率 |
|
batch_size |
Int |
Batch大小 |
|
epoc_num |
Int |
迭代次数 |
|
use_gpu |
Bool |
是否使用GPU训练 |
|
parallel |
Bool |
是否使用多卡训练 |
|
dataset |
Str |
数据集名称 |
|
model_save_dir |
Str |
模型保存路径 |
|
pretrained_model |
Str |
预训练模型路径(如果使用) |
|
image_shape |
Str |
输入图片尺寸 |
|
data_dir |
Str |
数据集路径 |
在执行脚本时,传入相应的参数值即可,例如:
python -u train.py --batch_size=16 --epoc_num=1 --dataset='pascalvoc' --pretrained_model='pretrain/ssd_mobilenet_v1_coco/'
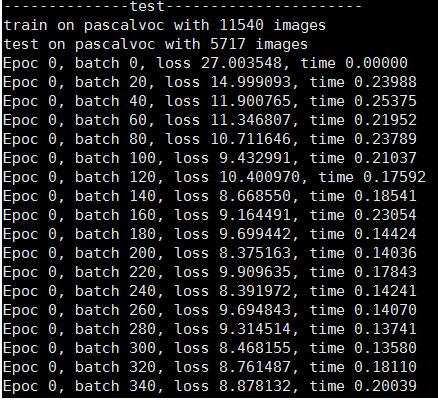
4.5.1单机多卡配置
单机多卡的配置相较于多机多卡配置较为简单,参数需要先在GPU0上初始化,再经由fluid.ParallelExecutor() 分发到多张显卡上。这里可以使用fluid.core.get_cuda_device_count()得到可用显卡数量,也可以自己定义用几张显卡。
train_exe = fluid.ParallelExecutor(use_cuda=True, loss_name=loss.name,
main_program=fluid.default_main_program())
train_exe.run(fetch_list=[loss.name], feed={...})
4.5.2参数调整
PaddlePaddle这一套SSD模型给了使用者非常大的自由度,可以对网络结构、损失函数、优化方法等多个角度对模型进行调整。本文采用的是基于MobileNet的SSD,如果想使用基于VGG的SSD,可以自己修改工程中的mobilenet_ssd.py文件,把里面定义的MobileNet Program更改为VGG的Program描述就可以了;如果需要修改损失函数或优化方法,则在train.py中找到build_program()函数,在
with fluid.unique_name.guard("train"):
loss = fluid.layers.ssd_loss(locs, confs, gt_box, gt_label, box,
box_var)
loss = fluid.layers.reduce_sum(loss)
optimizer = optimizer_setting(train_params)
optimizer.minimize(loss)
里修改损失函数或优化器即可;修改batch_num、epoch_num、learning rate等参数可以直接在train.py传入参数中进行。
4.5.3模型保存
模型在COCO数据集上训练完后,可以用fluid.io.save_persistables()方法将模型保存下来,我们实现了如下save_model()函数来将模型保存到指定路径。
def save_model(postfix, main_prog, model_path):
model_path = os.path.join(model_save_dir, postfix)
if os.path.isdir(model_path):
shutil.rmtree(model_path)
print('save models to %s' % (model_path))
fluid.io.save_persistables(exe, model_path, main_program=main_prog)
4.5.4继续训练
训练过程有时候会被打断,只要每个过几个batch保存一下模型,我们就可以通过load_vars()方法来恢复已经保存的模型来继续训练或者用于预测。文中提到的这些API,大家可以去PaddlePaddle的官网教程上进行更系统的学习和查看,PaddlePaddle提供了大量的中文文档和使用教程,对中文使用者可以说是非常友好的了。
fluid.io.load_vars(exe, pretrained_model, main_program=train_prog, predicate=if_exist)
4.5.5性能参数
训练速度:在COCO2017数据集上单卡训练,迭代1个epoch耗时3 min33s;单机4卡训练,迭代1个epoch耗时1min02s。
CPU/GPU占用率:正常训练情况下CPU占用率在40%-60%之间,GPU占用率稳定在50%左右。
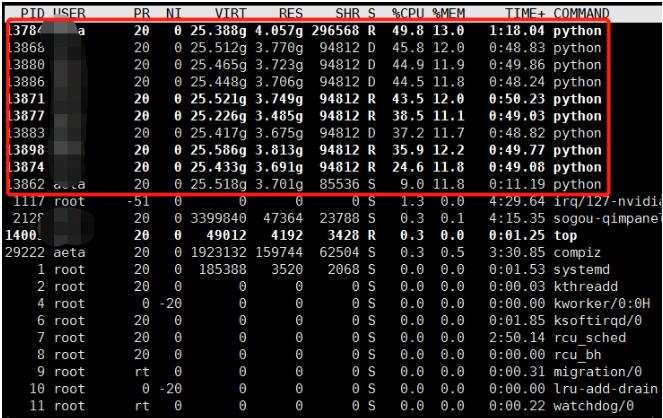
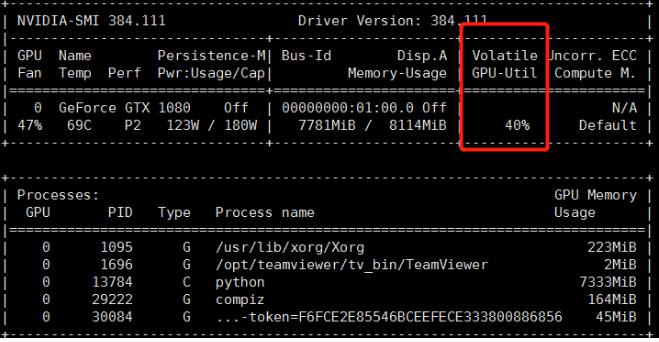
CPU/GPU使用情况
4.6模型评估
在PaddlePaddle的SSD模型中,可以使用eval.py脚本进行模型评估,可以选择11point、integral等方法来计算模型在验证集上的mAP。
python eval.py --dataset='pascalvoc' --model_dir='train_pascal_model/best_model' --data_dir='data/pascalvoc' --test_list='test.txt' --ap_version='11point' --nms_threshold=0.45
其中,model_dir是我们训练好的模型的保存目录,data_dir是数据集目录,test_list是作为验证集的文件列表(txt文件),前提是这些文件必须要有对应的标签文件,ap_version是计算mAP的方法,nms_threshold是分类阈值。***我们得到PaddlePaddle SSD模型在Pascal VOC数据集上的mAP为73.32%[2]
|
模型 |
预训练模型 |
训练数据 |
测试数据 |
mAP |
|
MobileNet-v1-SSD 300x300 |
COCO MobileNet SSD |
VOC07+12 trainval |
VOC07 test |
73.32% |
4.7模型预测及可视化
4.7.1模型预测
模型训练完成后,用test_program = fluid.default_main_program().clone(for_test=True)将Program转换到test模式,然后把要预测的数据feed进Executor执行Program就可以计算得到图像的分类标签、目标框的得分、xmin、ymin、xmax、ymax。具体过程如下:
test_program = fluid.default_main_program().clone(for_test=True) image = fluid.layers.data(name='image', shape=image_shape, dtype='float32') locs, confs, box, box_var = mobile_net(num_classes, image, image_shape) nmsed_out = fluid.layers.detection_output( locs, confs, box, box_var, nms_threshold=args.nms_threshold) place = fluid.CUDAPlace(0) if args.use_gpu else fluid.CPUPlace() exe = fluid.Executor(place) nmsed_out_v, = exe.run(test_program, feed=feeder.feed([[data]]), fetch_list=[nmsed_out], return_numpy=False) nmsed_out_v = np.array(nmsed_out_v)
4.7.2预测结果可视化
对于目标检测任务,我们通常需要对预测结果进行可视化进而获得对结果的感性认识。我们可以编写一个程序,让它在原图像上画出预测框,核心代码如下:
def draw_bounding_box_on_image(image_path, nms_out, confs_threshold,
label_list):
image = Image.open(image_path)
draw = ImageDraw.Draw(image)
im_width, im_height = image.size
for dt in nms_out:
if dt[1] < confs_threshold:
continue
category_id = dt[0]
bbox = dt[2:]
xmin, ymin, xmax, ymax = clip_bbox(dt[2:])
(left, right, top, bottom) = (xmin * im_width, xmax * im_width,
ymin * im_height, ymax * im_height)
draw.line(
[(left, top), (left, bottom), (right, bottom), (right, top),
(left, top)],
width=4,
fill='red')
if image.mode == 'RGB':
draw.text((left, top), label_list[int(category_id)], (255, 255, 0))
image_name = image_path.split('/')[-1]
print("image with bbox drawed saved as {}".format(image_name))
image.save(image_name)
这样,我们可以很直观的看到预测结果:

令人欣喜的是,PaddlePaddle的SSD模型中帮我们实现了完整的一套预测流程,我们可以直接运行SSD model下的infer.py脚本使用训练好的模型对图片进行预测:
python infer.py --dataset='coco' --nms_threshold=0.45 --model_dir='pretrained/ssd_mobilenet_v1_coco' --image_path='./data/ pascalvoc/VOCdevkit/VOC2012/JPEGImages/2007_002216.jpg'
4.8模型部署
PaddlePaddle的模型部署需要先安装编译C++预测库,可以在http://www.paddlepaddle.org/documentation/docs/zh/1.1/user_guides/howto/inference/build_and_install_lib_cn.html下载安装。预测库中提供了Paddle的预测API,预测部署过程大致分为三个步骤:1.创建PaddlePredictor;2.创建PaddleTensor传入PaddlePredictor中;3.获取输出 PaddleTensor,输出结果。这部分操作也并不复杂,而且Paddle的教程中也提供了一份部署详细代码参考,大家可以很快地利用这个模板完成模型部署(https://github.com/PaddlePaddle/Paddle/tree/develop/paddle/fluid/inference/api/demo_ci)
5.使用感受
- 中文社区支持好
在搭建SSD过程中,遇到了一些问题,例如segmentation fault、NoneType等,笔者直接在paddle的GitHub上提了相关issue,很快就得到了contributor的回复,问题很快得到了解决。
- 教程完善
PaddlePaddle的官网上提供了非常详尽的中英文教程,相较于之前学TensorFlow的时候经常看文档看半天才能理解其中的意思,PaddlePaddle对于中文使用者真是一大福音。
- 相比较TensorFlow,整体架构简明清晰,没有太多难以理解的概念。
- 模型库丰富
内置了CV、NLP、Recommendation等多种任务常用经典的模型,可以快速开发迭代AI产品。
- 性能优越,生态完整
从这次实验的结果来看,PaddlePaddle在性能上与TensorFlow等主流框架的性能差别不大,训练速度、CPU/GPU占用率等方面均表现优异,而且PaddlePaddle已经布局了一套完整的生态,前景非常好。
6.总结
整体来说,PaddlePaddle是一个不错的框架。由于设计简洁加之文档、社区做的很好,非常容易上手,在使用过程中也没有非常难理解的概念,用fluid Program定义网络结构很方便,对于之前使用过TensorFlow的工程师来说可以比较快速的迁移到PaddlePaddle上。这次实验过程中,还是发现了一些PaddlePaddle的问题,训练过程如果意外终止,Paddle的训练任务并没有被完全kill掉,依然会占用CPU和GPU大量资源,内存和显存的管理还需要进一步的提高。不过,实验也证实了,正常情况下PaddlePaddle在SSD模型上的精度、速度等性能与TensorFlow差不多,在数据读取操作上比TensorFlow要更加简洁明了。
-
PaddlePaddle Fluid是2016年百度对原有PaddlePaddle的重构版本,如无特殊说明,本文中所述PaddlePaddle均指PaddlePaddle Fluid。
-
此处引用了官方的评估结果,数据来源:https://github.com/PaddlePaddle/models/blob/develop/fluid/PaddleCV/object_detection/README_cn.md#%E6%A8%A1%E5%9E%8B%E8%AF%84%E4%BC%B0
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】