刚接触大数据一个月,把一些基本知识,总体架构记录一下,感觉坑很多,要学习的东西也很多,先简单了解一下基本知识
什么是大数据:大数据(big data),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据的5V特点:Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性),百度随便找找都有。
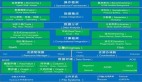
大数据处理流程:

1.是数据采集,搭建数据仓库,数据采集就是把数据通过前端埋点,接口日志调用流数据,数据库抓取,客户自己上传数据,把这些信息基础数据把各种维度保存起来,感觉有些数据没用(刚开始做只想着功能,有些数据没采集, 后来被老大训了一顿)。
2.数据清洗/预处理:就是把收到数据简单处理,比如把ip转换成地址,过滤掉脏数据等。
3.有了数据之后就可以对数据进行加工处理,数据处理的方式很多,总体分为离线处理,实时处理,离线处理就是每天定时处理,常用的有阿里的maxComputer,hive,MapReduce,离线处理主要用storm,spark,hadoop,通过一些数据处理框架,可以吧数据计算成各种KPI,在这里需要注意一下,不要只想着功能,主要是把各种数据维度建起来,基本数据做全,还要可复用,后期就可以把各种kpi随意组合展示出来。
4.数据展现,数据做出来没用,要可视化,做到MVP,就是快速做出来一个效果,不合适及时调整,这点有点类似于Scrum敏捷开发,数据展示的可以用datav,神策等,前端好的可以忽略,自己来画页面。
数据采集:
1.批数据采集,就是每天定时去数据库抓取数据快照,我们用的maxComputer,可以根据需求,设置每天去数据库备份一次快照,如何备份,如何设置数据源,如何设置出错,在maxComputer都有文档介绍,使用maxComputer需要注册阿里云服务,https://help.aliyun.com/product/27797.html,链接是maxComputer文档。
2.实时接口调用数据采集,可以用logHub,dataHub,流数据处理技术,DataHub具有高可用,低延迟,高可扩展,高吞吐的特点。
- 高吞吐:***支持单主题(Topic)每日T级别的数据量写入,每个分片(Shard)支持***每日8000万Record级别的写入量。
- 实时性:通过DataHub ,您可以实时的收集各种方式生成的数据并进行实时的处理,
- 设计思路:首先写一个sdk把公司所有后台服务调用接口调用情况记录下来,开辟线程池,把记录下来的数据不停的往dataHub,logHub存储,前提是设置好接收数据的dataHub表结构,https://help.aliyun.com/document_detail/47448.html?spm=a2c4g.11186623.3.2.nuizA4,这是dataHub文档,下图是数据监控,会看到数据会不停流入

3.前台数据埋点,这些就要根据业务需求来设置了,也是通过流数据传输到数据仓库,如上述第二步。
数据处理:
数据采集完成就可以对数据进行加工处理,可分为离线批处理,实时处理。
1.离线批处理maxComputer,这是阿里提供的一项大数据处理服务,是一种快速,完全托管的TB/PB级数据仓库解决方案,编写数据处理脚本,设置任务执行时间,任务执行条件,就可以按照你的要求,每天产生你需要的数据,https://help.aliyun.com/document_detail/30267.html?spm=a2c4g.11174283.3.2.0aBtdh,链接dataworks为文档。下图是检测任务实例运行状态

2.实时处理:采用storm/spark,目前接触的只有storm,strom基本概念网上一大把,在这里讲一下大概处理过程,首先设置要读取得数据源,只要启动storm就会不停息的读取数据源。Spout,用来读取数据。Tuple:一次消息传递的基本单元,理解为一组消息就是一个Tuple。stream,用来传输流,Tuple的集合。Bolt:接受数据然后执行处理的组件,用户可以在其中执行自己想要的操作。可以在里边写业务逻辑,storm不会保存结果,需要自己写代码保存,把这些合并起来就是一个拓扑,总体来说就是把拓扑提交到服务器启动后,他会不停读取数据源,然后通过stream把数据流动,通过自己写的Bolt代码进行数据处理,然后保存到任意地方,关于如何安装部署storm,如何设置数据源,网上都有教程,这里不多说。

数据展现:做了上述那么多,终于可以直观的展示了,由于前端技术不行,借用了第三方展示平台datav,datav支持两种数据读取模式,***种,直接读取数据库,把你计算好的数据,通过sql查出来,需要配置数据源,读取数据之后按照给定的格式,进行格式化就可以展现出来,https://help.aliyun.com/document_detail/30360.html,链接为datav文档。可以设置图标的样式,也可以设置参数,

第二种采用接口的形式,可以直接采用api,在数据区域配置为api,填写接口地址,需要的参数即可,这里就不多说了。
这次先记录这么多,以后再补充,内容为原创,若是有不对的地方还请评论纠正。