容器化对于Redis自动化运维效率、资源利用率方面都有巨大提升,携程在对Redis在容器上性能和稳定性进行充分验证后,启动了生产Redis迁移容器化的项目。其中第一批次两台宿主机,第二批次五台宿主机。
本次“异常”是第二批次迁移过程中发现的,排查过程一波三折,最终得出让人吃惊的结论。
希望本次结论能给遇到同样问题的小伙伴以启发,另外本次分析问题的思路对于分析其他疑难杂症也有一定借鉴作用。
一、问题描述
在某次Redis迁移容器后,DBA发来告警邮件,slowlog>500ms,同时在DBA的慢日志查询里可以看到有1800ms左右的日志,如下图1所示:
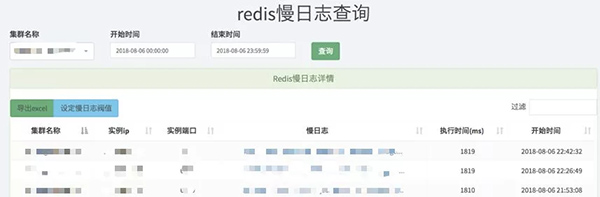
图 1
二、分析过程
2.1 什么是Slowlog
在分析问题之前,先简单解释下Redis的slowlog。阅读Redis源码(图2)不难发现,当某次Redis的操作大于配置中slowlog-log-slower-than设置的值时,Redis就会将该值记录到内存中,通过slowlog get可以获取该次slowlog发生的时间和耗时,图1的监控数据也是从此获得。
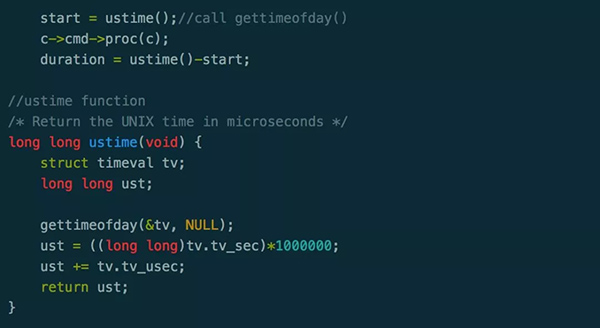
图 2
也就是说,slowlog只是单纯的计算Redis执行的耗时时间,与其他因素如网络之类的都没关系。
2.2 矛盾的日志
每次slowlog都是1800+ms并且都随机出现,在第一批次Redis容器化的宿主机上完全没有这种现象,而QPS远小于第一批次迁移的某些集群,按常理很难解释,这时候翻看CAT记录,更加加重了我们的疑惑,见图3:
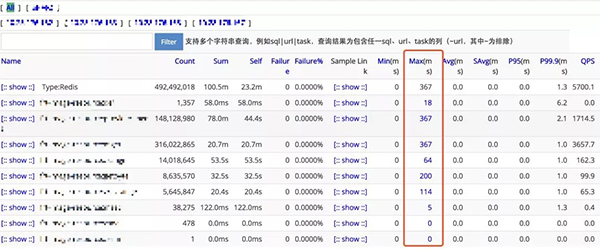
图 3
CAT是携程根据开源软件(https://github.com/dianping/cat)的定制版本,用于客户端记录打点的耗时,从图中可以很清晰的看到,Redis打点的最大值367ms也远小于1800ms,它等于是说下面这张自相矛盾图,见图4:
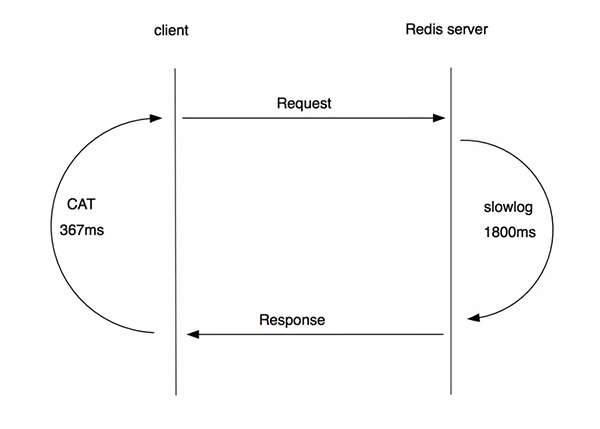
图 4
2.3 求助社区
所以说,slowlog问题要么是CAT误报,要么是Redis误报,但Redis使用如此广泛,并且经过询问CAT的维护者说CAT有一定的消息丢弃率,而Redis在官方github issue中并没有发现类似的slowlog情形,因此我们第一感觉是CAT误报,并在官方Redis issue中提问,试图获取社区的帮助。
很快社区有人回复,可能是NUMA架构导致的问题,但也同时表示NUMA导致slowlog高达1800ms很不可思议。关于NUMA的资料网上有很多,这里不再赘述,我们在查阅相关NUMA资料后也发现,NUMA架构导致如此大的slowlog不太可能,因此放弃了这条路径的尝试。
2.4 豁然开朗
看上去每个方面好像都没有问题,而且找不到突破口,排障至此陷入了僵局。
重新阅读Redis源代码,直觉发现gettimeofday()可能有问题,模仿Redis获取slowlog的代码,写了一个简答的死循环,每次Sleep一秒,看看打印出来的差值是否正好1秒多点,如图5所示:

图 5
图5的程序大概运行了20分钟后,奇迹出现了,gettimeofday果然有问题,下面是上面程序测试时间打印出来的LOG,如图6:
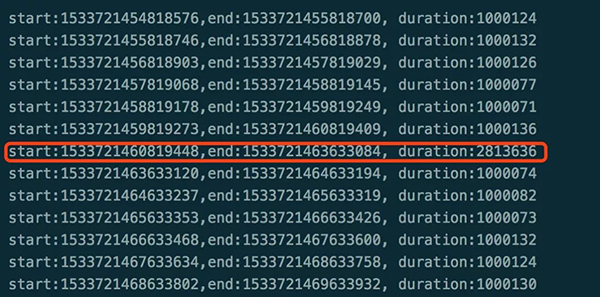
图 6
图6中标红的时间减去1秒等于1813ms,与slowlog时间如此相近!在容器所在的物理机上也测试一遍,发现有同样的现象,排除因容器导致slowlog,希望的曙光似乎就在眼前了,那么问题又来了:
- 到底为什么会相差1800ms+呢?
- 为什么第一批机器没有这种现象呢?
- 为什么之前跑在物理机上的Redis没有这种现象呢?
带着这三个问题,重新审视系统调用gettimeofday获取当前时间背后的原理,发现一番新天地。
三、系统时钟
系统时钟的实现非常复杂,并且参考资料非常多。
简单来说 我们可以通过命令:
- cat /sys/devices/system/clocksource/clocksource0/current_clocksource
来获取当前系统的时钟源,携程的宿主机上都是统一Time Stamp Counter(TSC):80x86微处理器包括一个时钟输入插口,用来接收来自外部振荡器的时钟信号,从奔腾80x86微处理器开始,增加了一个计数器。
随着每增加一个时钟信号而加一,通过rdtsc汇编指令也可以去读TSC寄存器,这样如果CPU的频率是1GHz,TSC寄存器就能提供纳秒级别的计时精度,并且现代CPU通过FLAG constant_tsc来保证即使CPU休眠也不影响TSC的频率。
当选定TSC为时钟源后,gettimeofday获取墙上时钟(wall-clock)正是从TSC寄存器读出来的值转换而来,所谓墙上时钟主要是参照现实世界人们通过墙上时钟获取当前时间,但是用来计时并不准确,可能会被NTP或者管理员修改。
那么问题又来了,宿主机的时间没有被管理员修改,难道是被NTP修改?即使是NTP来同步,每次相差也不该有1800ms这么久,它的意思是说难道宿主机的时钟每次都在变慢然后被NTP拉回到正常时间?我们手工执行了下NTP同步,发现的确是有很大偏差,如图7所示:

图 7
按常识时钟正常的物理机与NTP服务器时钟差异都在1ms以内,相差1s+绝对有问题,而且还是那个老问题,为什么第一批次的机器上没有问题?
四、内核BUG
两个批次宿主机一样的内核版本,第一批没问题而第二批有问题,差异只可能在硬件上,非常有可能在计时上,翻看内核的commit log终于让我们发现了这样的commit,如图8所示:

图 8
该commit非常清楚指出,在4.9以后添加了一个宏定义INTEL_FAM6_SKYLAKE_X,但因为搞错了该类型CPU的crystal frequency会导致该类型的CPU每10分钟慢1秒钟。
这时再看看我们的出问题的第二批宿主机xeon bronze 3104正好是skylake-x的服务器,影响4.9-4.13的内核版本,宿主机内核4.10正好中招。
并且NTP每次同步间隔1024秒约慢1700ms,与slowlog异常完全吻合,而第一批次的机器CPU都不是SKYLAKE-X平台的,避开了这个BUG,迁移之前Redis所在的物理机内核是3.10版本,自然也不存在这个问题。至此,终于解开上面三个疑惑。
五、总结
5.1 问题根因
通过上面的分析可以看出,问题根因在于内核4.9-4.13之间skylake-x平台TSC晶振频率的代码BUG,也就是说同时触发这两个因素都会导致系统时钟变慢,叠加上Redis计时使用的gettimeofday会容易被NTP修改导致了本文开头诡异的slowlog“异常”。有问题的宿主机内核升级到4.14版本后,时钟变慢的BUG得到了修复。
5.2 怎么获取时钟
对于应用需要打点记录当前时间的场景,也就是说获取Wall-Clock,可以使用clock_gettime传入CLOCK_REALTIME参数,虽然gettimeofday也可以实现同样的功能,但不建议继续使用,因为在新的POSIX标准中该函数已经被废弃。
对于应用需要记录某个方法耗时的场景,必须使用clock_gettime传入CLOCK_MONOTONIC参数,该参数获得的是自系统开机起单调递增的纳秒级别精度时钟,相比gettimeofday精度提高不少,并且不受NTP等外部服务影响,能更准确来统计耗时(Java中对应的是System.nanoTime),也就是说所有使用gettimeofday来统计耗时(Java中是System.currenttimemillis)的做法本质上都是错误的。