今天来聊一聊微服务的隔离和熔断是怎么做的, 如果你的项目没有用微服务,不要走开,可以看看对一个问题的解决思路。
按照码农翻身的惯例, 我们先用一个例子来抛出问题:
假设Tomcat线程池有100个线程, 每次有新的用户请求过来,Tomcat就会从中找出一个空闲的线程去执行, 抛开那些琐碎的小细节,这些请求其实非常简单, 无非就是这么几件事:
1. 根据用户ID调用用户服务, 获取用户对象。
2. 获取该用户的推荐商品
3. 获取该用户的积分。
4. 把这些信息组合起来,返回给浏览器。
有意思的是前三件事情全是HTTP调用,需要调用某个地方的所谓“微服务”。
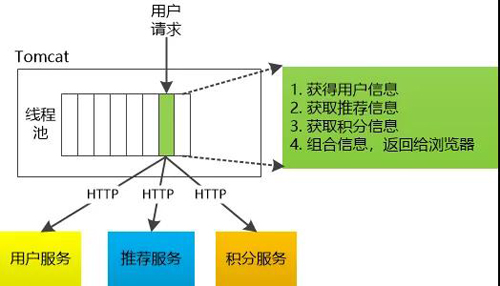
有一次,线程A去执行几个逻辑,等它调用“推荐服务”的时候,“推荐服务”迟迟没有返回,线程A也许很高兴, 终于可以休息了!
新的用户请求源源不断地到来,线程池中越来越多的线程都在等待推荐服务返回。
很快,100个线程全部用光,Tomcat只好挂出一个牌子: “系统繁忙,暂停营业。”
总之, 一个服务的出错竟然导致了整个Tomcat不可用,实在是难以忍受。
也许你会和运维商量一下,来个简单粗暴的办法: 给Tomcat线程池在增加100个线程兄弟, 可是这不能解决问题, 在高并发的情况下, 只要那些远程的微服务有一个阻塞,无论多少线程,很快就会被用光。
于是,你只好重启Tomcat,毁灭这个可爱的世界,但是重启后问题还是有可能发生。
隔离
怎么把一个微服务的故障给隔离起来呢?让他们互不影响呢?
Netflix的程序员们想了一个点子, 对每个微服务,都分配一个线程池,像这样:
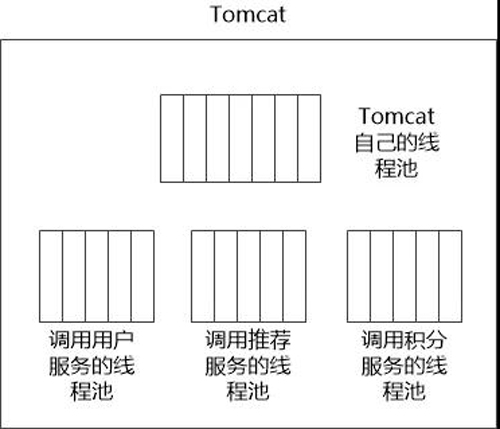
比如说调用“推荐服务”的时候,就会从“推荐服务线程池” (假设有5个线程)中找到一个线程执行。如果这个HTTP系统调用迟迟没有返回,那这个线程就会一直等待,新的请求就需用使用池中别的线程。
如果5个线程都用光了,会发生什么情况?
这很简单, 可以简单地认为这个服务不可用了!马上返回,绝不等待。
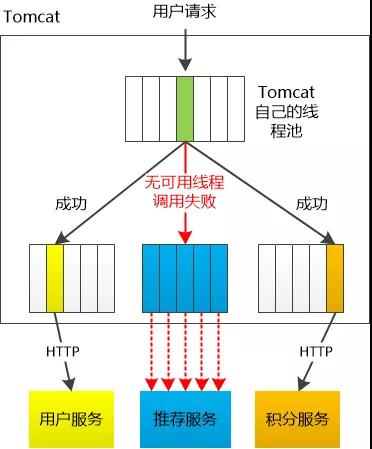
这些新的线程池,是一种隔离的手段, 一个微服务一旦出了问题,很快就会被识别出来。
熔断器
但是上面这种方案,还是有一定的问题,如果这个推荐服务已经不可用了,还不断地尝试去调用,那肯定是一种浪费。
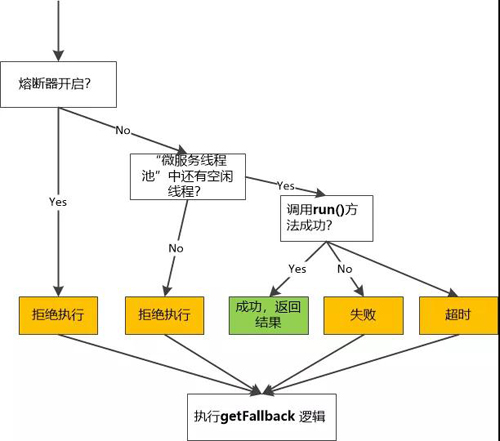
所以Netflix的程序员又想了一个办法:使用熔断器(也叫断路器),注意:当这个熔断器关闭的时候,外面的请求可以直接调用,如果打开,就把外界的请求给阻断了。
具体的做法是:系统会检测请求失败的比率(失败数/总请求数), 一旦这个比率达到一个阈值的时候,熔断器就开启, 直接拒绝执行用户请求。然后休眠一段时间,尝试放过一部分流量(比如一个请求),如果调用成功,熔断器闭合,恢复到正常状态,否则继续进行休眠周期。
API
现在有了新的线程池,对程序员来讲,该如何使用呢? 原来是这么做的:
- UserService service = ... 获得用户服务...
- User user = service.getUser(userID);
现在,为了利用新的线程池, 需要做一层封装:
- UserService service = ... 获得用户服务...
- UserServiceCmd cmd = new UserServiceCmd(service, userID);
- User user = cmd.execute();
看到没有? UserService 被封装了一层, 放到了一个UserServiceCmd中去执行。
这个Command代码是这个样子的:
- public class UserServiceCmd extends HystrixCommand<User> {
- private UserService userService = null;
- private String userID = null;
- ……
- public UserServiceCmd(UserService userService,
- String userID) {
- ……
- this.userService = userService;
- this.userID = userID;
- }
- @Override
- protected User run(){
- return userService.getUser(userID);
- }
- @Override
- protected User getFallback() {
- return annonymousUser;
- }
- }
看起来非常简单吧, 可是背后的魔法是什么呢?
实际上,在这个UserServiceCmd执行的时候,会使用另外一个线程池的线程去调用那个run()方法。

(注:这是一种同步调用,实际上还可以异步调用)
线程池的维护是在HystrixCommand这个父类中(命令模式),不需要程序员处理,程序员只需要告诉它: 我需要几个线程,就可以了。
眼光敏锐的你也许已经猜到,这里还采用了设计模式模板方法!
HystrixCommand它定义了一个抽象的方法: run(), 这个方法需要程序员去实现(例如前面的UserServiceCmd ), 父类的的execute方法会调用程序员写的run()方法。
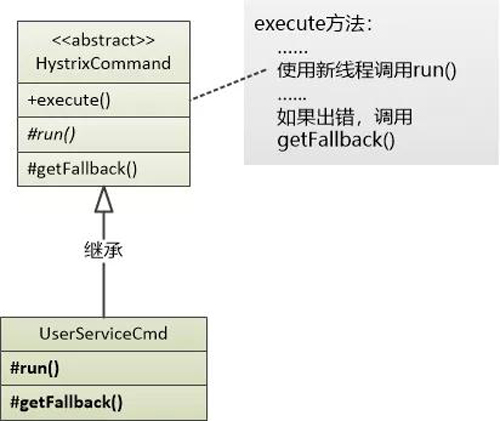
你也许还会注意到,还有一个叫做getFallback()的方法,这是干嘛用的?
其实前面的例子中我们只说道了线程池耗尽的时候,直接返回。 但是大部分情况下总得返回一点儿东西吧,比如UserServiceCmd,我们也许可以返回一个匿名的用户给调用方。
这就是所谓的撤退,退却(Fallback)逻辑。
当然,这个逻辑也可以用在熔断器开启,调用失败,超时等情况下。
一个粗略的、大致的流程图是这样的:
Netflix把这些功能(当然,这里只是概要介绍,还有很多其他功能)给组装起来,形成了一个开源的库,叫做Hystrix,就是豪猪,浑身是刺,自我保护,还是挺贴切的。
后记
刚写完这个文章,就得到了一个”悲惨“的消息: Hystrix不再开发新功能,将进入维护模式。 考虑到Hystrix巨大的使用量,学习它还是非常有价值的。
Netflix推荐大家转向Resilience4j,看来又有新的玩具可以研究下了,兴奋!
这是个相对新的项目,影响力和使用量现在还不能和Hystrix相比。
Resilience4j全面拥抱了Java 8和函数式编程, 他的核心功能包括:断路器,限速,隔离(不再支持线程池),自动重试,响应的缓存, 看,核心的功能还是类似的, resilience4j能发展到什么程度,我们拭目以待吧。

【本文为51CTO专栏作者“刘欣”的原创稿件,转载请通过作者微信公众号coderising获取授权】