同样做数据科学,为什么有人赚得多,有人赚的少?为了科学地回答这个问题,Kaggle 进行了一项系统的调查。结果表明,行业、经验、掌握的数据类型等是影响数据科学家薪酬的主要因素。行业是自己选的,经验是自己攒的,这些都没啥好说的。至于数据类型,你会的更高级就赚得越多。
如何提高薪酬?本文作者从 2018 年 Kaggle ML & DS 调查问卷中总结出 124 条「该做」和「不该做」之事。
做什么能为你的数据科学职业生涯加码?很多人已经非常清楚巩固数据科学职业和加薪的重要因素。但我从没有见过一个系统的、基于数据的方法来回答这个问题。所以我想通过建模来解释「哪些因素可以提高数据科学家的市场价值」。有些你可能已经了解,但有些可能真的有助于你加薪呢~
完整研究报告及代码地址:
https://www.kaggle.com/andresionek/what-makes-a-kaggler-valuable
根据数据估计薪酬
我们只能做这种研究,因为 Kaggle 已经发布了其第二次年度机器学习和数据科学调查的数据。该调查于 2018 年 10 月展开,耗时一周,共获得 23859 份回复。结果包括一些原始数据,如什么人在研究数据、不同行业中机器学习的情况、新数据科学家进入该领域的最佳方式。
有了这些数据,我们想了解影响 Kaggler 薪酬的因素(我们把回复调查的人称之为 Kaggler)。我们想让你了解什么对市场更有价值,这样你就可以停止把时间花在投资回报率(ROI)低的事情上,并加速获得更高的报酬。根据这些从数据中提炼出来的见解,我希望你有一天能够像 Babineaux 一样——躺在钱堆上。
Huel Babineaux,《绝命毒师》和《风骚律师》中的角色。图源:AMC
在进入正题之前,我们可以先做一些基本的探索性数据分析(EDA)。首先看一下大家的薪水↓↓

数据:Kaggle 第二次年度机器学习和数据科学调查。图表:作者
薪酬主要集中分布在较低的水平范围内(每年 1 万美元),在 10 万美元左右还有另一个高峰。很多学生也填写了这份调查问卷,看看他们赚多少?

数据:Kaggle 第二次年度机器学习和数据科学调查。图表:作者
不出所料,学生们赚得不多,因为他们还没有正式工作。既然如此,我们可以把学生从数据中剔除并确定收入前 20% 的 Kaggler 薪酬是多少。

数据:Kaggle 第二次年度机器学习和数据科学调查。图表:作者
根据这些数据,我们定义了用于建模的目标变量,如下:
我们将计算一个 Kaggler 年收入超过 10 万美元的概率。
数据科学中的性别不平衡
在继续建模之前,我想告诉你的是,在收入最高的 20%Kaggler 中存在性别不平衡,但是其余的 80% 中不存在这种现象。这意味着男性高管的薪资要高于女性。如下图所示:

数据:Kaggle 第二次年度机器学习和数据科学调查。图表:作者
预测模型
为了创建模型,我们从 29 个问题中提取了 138 个可以解释高薪的特征。经过一定的数据清洗之后,我们运行了 Logistic 回归和随机森林模型。
经过评估,我们发现 Logistic 回归表现更好。该模型在提取特征系数方面也具有优势。这可以帮助我们理解每个特征对(收入最高的 20%Kaggler)最终结果有何贡献。我们做了欠采样、交叉验证及网格搜索,代码见完整版调查报告。
- ### -- ### -- LogisticRegression -- ### -- ###
- MODEL PERFORMANCE ON TEST DATA*
- Accuracy: 0.8167438271604939
- AUC: 0.8963917030007695
- Confusion Matrix:
- [[1817 411]
- [ 64 300]]
- Type 1 error: 0.18447037701974867
- Type 2 error: 0.17582417582417584
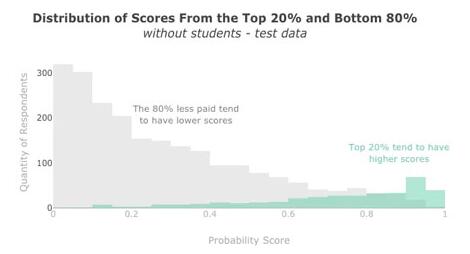
模型性能:薪水前 20% 和后 80% 的预测分数。数据:Kaggle 第二次年度机器学习和数据科学调查。
帮你加薪的几个方法
选择特征之后,我们的模型总共有 124 个特征。从它们的系数我们总结了几点帮你加薪的建议。
我们模型的截距是 0。这意味着每个人都是从 0 分开始的。接下来你可以在你分数的基础上加分或减分,这取决于你针对每个问题给出的答案。
- 正系数:系数为正表示肯定的答案有助于你挤进前 20%
- 负系数:系数为负表示肯定的回答不利于你挤进前 20%
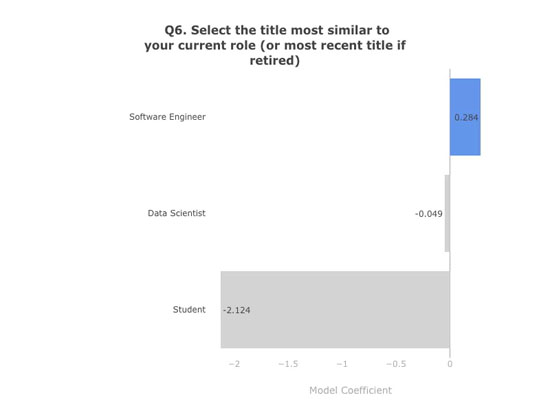
模型系数。数据:Kaggle 第二次年度机器学习和数据科学调查。图表:作者
学生身份可能是挫败感强、薪水低的一个原因。走出学校门找份工作吧!做一名数据科学家很不错,但软件工程师薪水更高。为什么不去做一名 B 型数据科学家(注:B 型数据科学家具有很强的编程能力,可能是经过训练的软件工程师。详见:
https://medium.com/@jamesdensmore/there-are-two-types-of-data-scientists-and-two-types-of-problems-to-solve-a149a0148e64)并将模型部署到生产中呢?
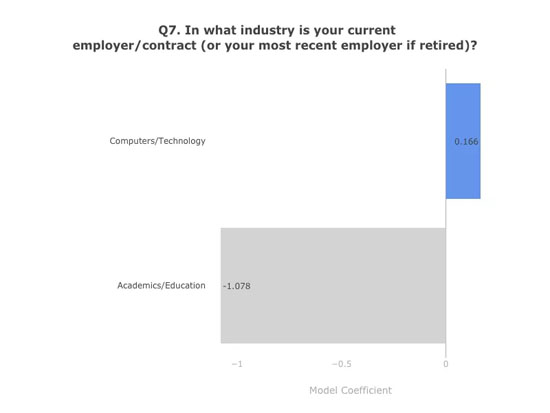
模型系数。数据:Kaggle 第二次年度机器学习和数据科学调查。图表:作者
如果想致富,不要再待在学界/教育界了。从完整的 EDA 调查中可以看出,与其它领域相比,学界/教育界的平均薪水最低,模型的系数也佐证了这一点。作为对数据科学的未来最重要的领域之一,学界/教育的平均薪资水平居然最低,这让人非常沮丧。如果你想多赚点钱,投身计算机/技术行业有利于你挤进薪水的前 20%。
模型系数。数据:Kaggle 第二次年度机器学习和数据科学调查。图表:作者
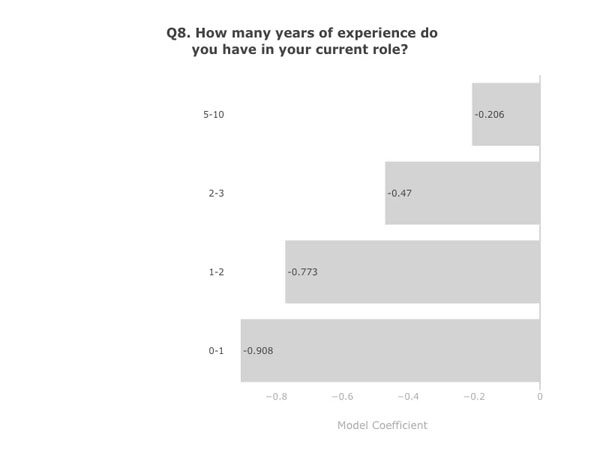
显然,经验越丰富,赚得就越多。所以看开点,你不太可能凭借两年经验就成为收入前 20% 的 Kaggler 之一。
模型系数。数据:Kaggle 第二次年度机器学习和数据科学调查。图表:作者
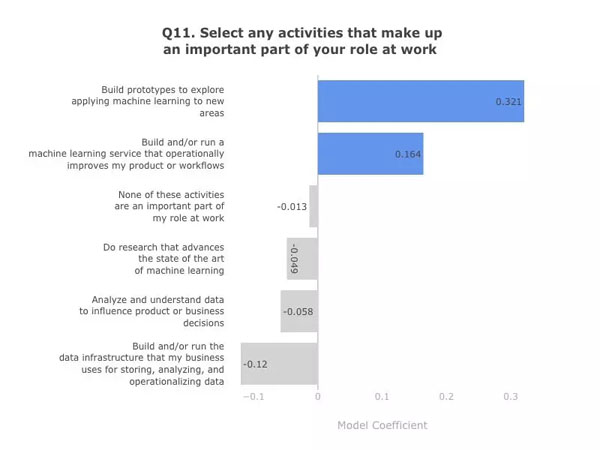
说到活动,试着构建原型或机器学习服务。探索机器学习在新领域的应用并利用它来改进产品或工作流,这也是离年入 10 万美元更近一步的方法。
另一方面,如果你的工作主要是运用商业智能来分析和理解影响产品或商业决策的数据,那就不要期望高薪了。运行数据基础架构也是如此。
使用云计算服务!习惯使用 AWS 或其它领先的云供应商,如谷歌或微软。
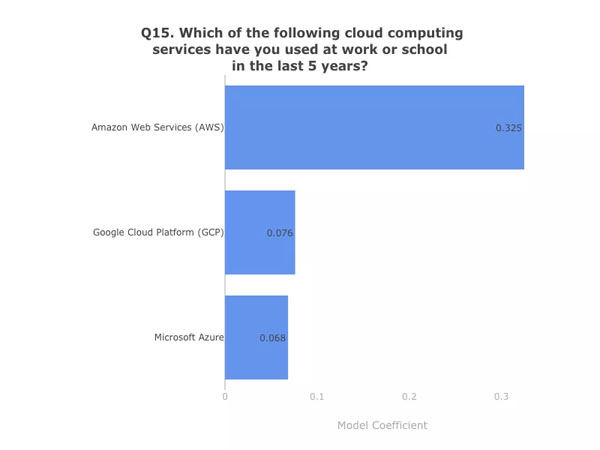
模型系数。数据:Kaggle 第二次年度机器学习和数据科学调查。图表:作者
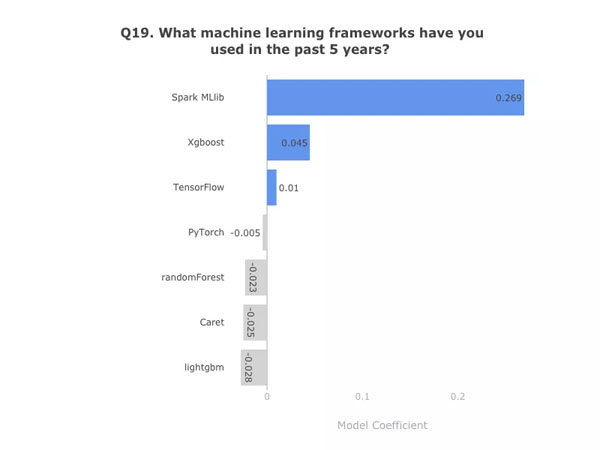
有些机器学习框架可能会增加你的市场价值。学习并使用 SparkMLlib、Xgboost、TensorFlow 会让你的简历更有分量。
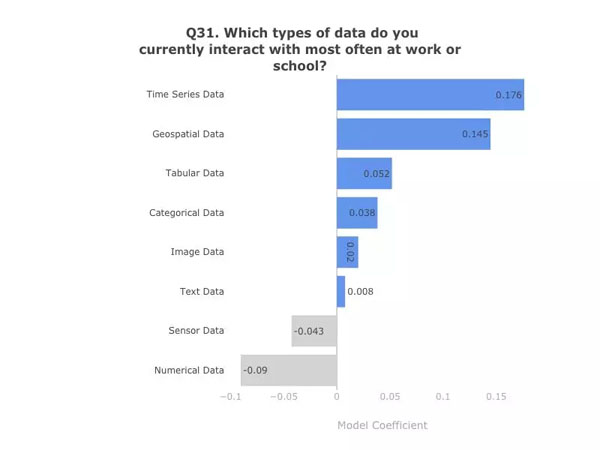
模型系数。数据:Kaggle 第二次年度机器学习和数据科学调查。图表:作者
说到可能会增加薪酬的数据类型,不妨试着学学时间序列(Time Series)和地理空间数据(Geospatial Data)。所有人都在用数值型数据(Numerical Data),所以先学好基础数据,如果你想获得高薪,那就去学习更高级的数据类型。
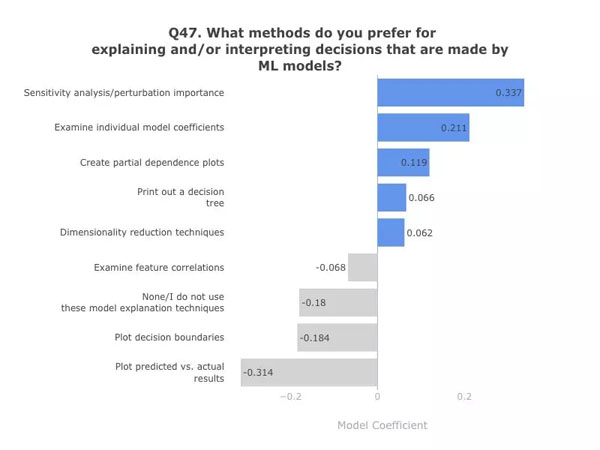
模型系数。数据:Kaggle 第二次年度机器学习和数据科学调查。图表:作者
原文链接:https://towardsdatascience.com/what-makes-a-data-scientist-valuable-b723e6e814aa
【本文是51CTO专栏机构“机器之心”的原创译文,微信公众号“机器之心( id: almosthuman2014)”】