












商品标题是卖家和买家在电商平台沟通的重要媒介。在淘宝这样的电商app中,用户与推荐、搜索等系统的交互时所接受到的信息,主要由商品标题、图片、价格、销量以及店铺名等信息组成。这些信息直接影响着用户的点击决策。而其中,算法能够主动影响的集中在标题与图片上。本文所述工作,关注于商品标题生成,更具体地来讲,是商品的短标题的生成。
背景
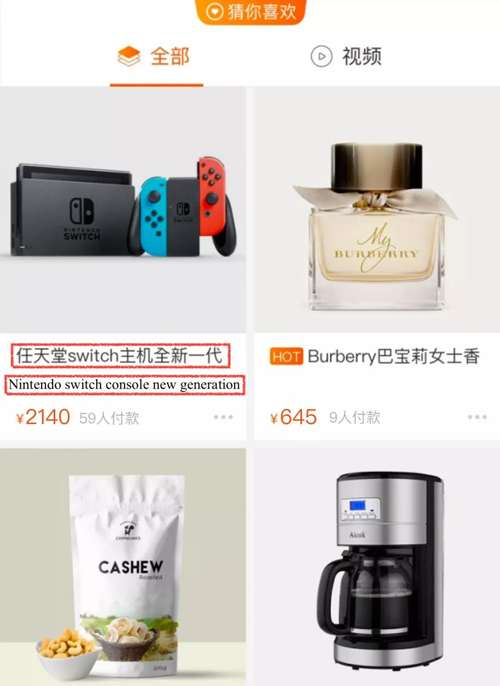

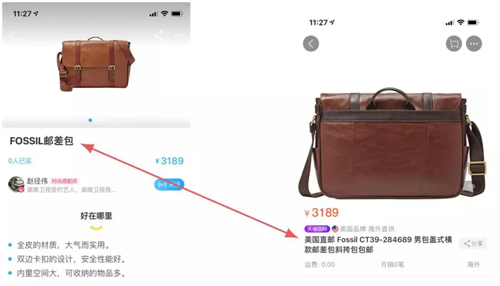
图1. 猜你喜欢推荐结果展示图以及商品详情页截图(目前猜你喜欢同时存在一行以及两行标题情况)。商品原始标题往往过长(平均长度30字左右),在结果页中无法完整显示,只能点击进入商品详情页才能看到商品完整标题。
当前淘系商品(C2C)标题主要由商家撰写,而商家为了SEO,往往会在标题中堆砌大量冗余词汇,甚至许多与商品并不直接相关的词汇,以提高被搜索召回的概率,以及吸引用户点击。这引起两方面的问题:
- 这些标题往往过长,以往pc时代这并不是一个严重问题。但现在已经全面进入移动互联网时代,手淘用户也几乎都是移动端用户,这些冗长的商品标题由于屏幕尺寸限制,往往显示不全,只能截断处理,严重影响用户体验。如图1所示,在推荐的展示页中,标题往往显示不全,影响体验。用户若想获取完整标题,还需进一步点击进入商品详情页。
- 另一方面,这些原始长标题是为了搜索做的SEO,对于推荐的match阶段,其实并无帮助。甚至,其中许多无关冗余词汇还会起到噪声作用,并且也会对用户的浏览决策起到干扰作用。
因此,使用尽可能短的文本体现商品的核心属性,引起用户的点击和浏览兴趣,提高转化率,是值得深入研究的问题。
问题形式化
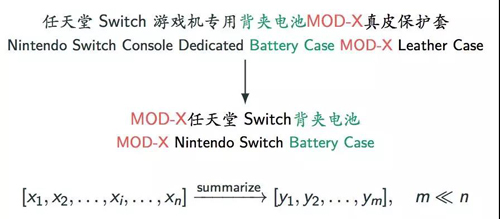
商品短标题的生成或者压缩,可以看作一种特殊的文本摘要任务。类似于Alexander Rush等人提出的sentence summarization任务[1,2]。但相比普通的sentence summarization任务,作为特定电商领域且跟用户消费密切相关的一个任务,商品短标题的生成具有一些更显式且严格的限制。此工作中,我们主要将其抽象为两点:
- 不能引入无关信息。商品的短标题尽量保留原始标题中的用词,避免引入其他信息。一方面这是因为原始标题中的词语往往都是卖家为了点击率等考虑精挑细选的,已经足够优秀;另一方面,引入其他信息虽然能够带来更多的变化,但也增加了犯错的可能。如为Nike的鞋子标题生成了Adidas关键字,这类事实性的错误在wiki style类的文本摘要中经常发生,已引起研究人员的重视[3],但在新闻之类的摘要中,人们往往还能忍受。对于电商平台来说,这类错误是不能容忍的。
- 需要保留商品的关键信息(如,品牌,品类词)。商品的短标题如果丢失了品牌或者品类词,一方面对用户来说非常费解,影响体验;另一方面也容易引起卖家的不满投诉。
这两个约束,在普通的句子摘要任务中,同样也成立,但他们并没有电商领域中如此严格。
针对这些问题,我们基于Pointer Netowrk [4],提出Multi-Source Pointer Network (MS-Pointer)来显式建模这两个约束,生成商品短标题。
首先,对于约束1,我们使用Pointer Network框架将商品短标题摘要建模成一个extractive summarization(抽取式摘要)问题(Pointer Network是一种特殊的Seq2Seq模型结构,具体下一小节介绍)。对于约束2,我们尝试在原有的标题encoder之外,引入关于商品背景知识信息的另一个encoder (knowledge encoder),这个encoder编码了关于商品的品牌以及品类词信息,其作用一方面在于告诉模型商品的品牌和品类词信息,另一方面在于pointer mechanism可以直接从这个encoder中提取商品的品牌等信息。
最终,MS-Pointer可以使用data-driven的方式学习从这多个encoder中提取相应的信息来生成商品的短标题,比如从knowledge encoder中选择品牌信息,而从title encoder中选择丰富的描述信息。
这里需要说明两个问题。
- 对于抽取式摘要,基于删除的方法(Deletion Based)一样可以使用。比如Filippova等人[5]便基于seq2seq提出了在decode端输出原始title每个词保留与否的label,这是一个特殊的seq2seq模型,与普通的seq2seq模型decoder输入是summarization不同,这个模型的decoder的输入还是原始标题,输出并不是生成词,而是输入词保留与否二分类的label。然而,为了让摘要结果更加通顺易读,摘要中经常存在word reordering现象[6],Deletion Based方法并不能很好地处理这问题。在我们收集的训练数据中,就发现有超过50%的数据有word reordering现象。
- 另一个问题在于title中品牌、品类词信息的处理使用。显然,我们可以引入NER模型,构建一个end2end的模型,从title中自动识别商品的品牌和品类词等信息,来完成这个任务。但是,首先NER模块本身就尤其精度限制,会有错误累积问题,且需要额外的entity标注数据。另外,许多标题中存在多个品牌,多个品类词,这种情况下,正确识别错商品自身的品牌和品类词信息,对NER模块来说是个更大的挑战。而商品的品牌和品类信息,可以轻易地从数据库中商品meta信息中获取,直接给模型输入这些背景知识,显然是更加简单直接的选择。
模型
Pointer Network
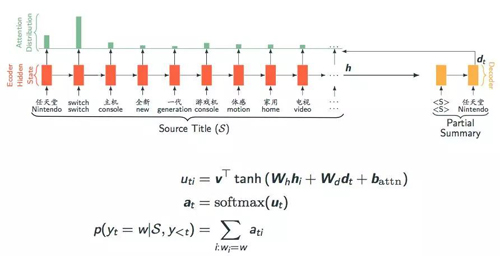
Pointer Network框架图
与普通的seq2seq从一个预先定义好的vocabulary中选择词语生成摘要不同,pointer network使用attention机制,从encoder中选择词语来生成摘要。如图2所示,在decode的每一步t,使用decoder的隐状态dtdt去attention encoder的隐状态[h1,…,hi,…,hn][h1,…,hi,…,hn],然而以此attention的权重作为分布,去选择对应位置上的词来生成摘要。
相比传统的seq2seq,Pointer Network能够更好地处理NLP中常遇到的OOV问题。这是因为它能够动态地从输入中选择单词,而不是从一个预定义好的vocabulary中选择,这使得它可以生成vocabulary中没有的单词。这对于商品短标题生成是一个非常好的特性,因为商品标题中存在大量的型号类的词语,都可能未出现在训练语料中。当然最重要的是,Pointer Network提供了一种extractive地摘要生成建模思路。短标题中所有的单词都是从输入的原始标题中获取的,这样可以大大降低普通seq2seq的abstractive摘要那样出错的概率。但是Pointer Network并没有机制保障decoder保留原标题中的品牌与品类信息,而这对电商平台而言是至关重要的。
Multi-Sources Pointer Network
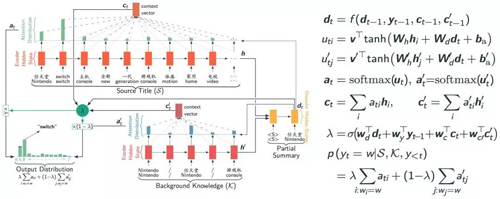
使用两个encoder的Multi-Sources Pointer Network框架图
最显著的区别在于,MS-Pointer可以从多个encoders中选择单词。在decode的每一步t,首先计算一个soft gating weight λ,这个概率权衡着decoder从两个encoder中选择单词的概率。最终生成单词的概率为两个encoder上的attention分布的加权和。这里为了简单处理,使用了sigmoid函数,根据decoder当前输入、状态以及encoder的状态来计算选择不同encoder的概率。更一般地,可以使用softmax函数来建模大于两个encoder的情况。这里λ所起的作用类似于一个分类器,如根据当前状态,去选择是否从background knowledge encoder中选择品牌信息。
最终,模型的loss可定义为为:
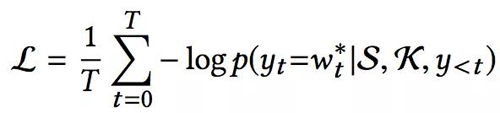
实验效果
数据集构造

对于本文的模型,我们除了常见的训练seq2seq模型需要的输入输出seq pair 样本,还需要商品的品牌、品类背景知识信息。对于品牌等信息,可以容易地从odps数据库中获取。对于商品原始标题与短标题对,我们从手淘有好货栏目中收集了这样的数据。有好货是手淘首页一个推荐场景,其中包含了大量达人生产的优质内容数据。这其中,就包含了商品的短标题。如下图所示,有好货中推荐结果的展示页面包含了达人所写的商品短标题。
但是这些短标题并不适合所有都拿来训练模型。其中一部分标题类似于创意文案,已经与商品本书关联较弱,属于噪声数据需要去掉;另一部分虽然也是商品短标题,但是由达人重新延伸重写了,这可以认为是abstractive的短标题,也需要去除,原因见上文说明,因我们的模型是一个extractive模型;还有一些虽然是extractive的短标题,但是存在品牌缺失类的情况,也需要清除。所以,最终我们严格使用extractive,短标题长度(10个字,推荐页一行能显示的长度),以及必须保留品牌信息,来过滤了有好货的训练数据。在第一期论文研究阶段,共收集了超过40w训练数据,统计信息见下表:

后期,我们扩充了数据源,包括有好货以及从其他信息源手机的数据,最终构成了一个超过500万样本的训练语料。
数据处理
在此工作中,我们尽量减少了对于数据的预处理操作:
- 大部分标点符号均做了保留。许多品牌,型号等信息包含标点,如Coca-Cola, J.crew.
- 凡是出现在品牌等关键信息中的数字,都保留。这是因为许多品牌、型号中会带有数据,如 7 for all mankind, 360,PS4等。数字在NLP中是比较难处理的一类问题,首先数字是无穷的,难以学习可靠的表示,且生成时候很容易会生成一个新的错误的数字出来。因此凡是每次短标题中出现过的数字,都被过滤掉了。当然还有很多50ml、100%这样的处理细节,这里不做过细描述(前面的两个case,在此工作中不做切分,作为一个整体处理)。
- 不分词,按字处理。seq2seq很多时候性能已经足够强,可以学出如何组合出合适的词语,这样也可以规避分词错误引起的问题。另外,词的长度不定,也难以控制生成的短标题长度。
数据按照80%,10%,10%,以类目层次地随机划分为训练集、验证集以及测试集。
Baseline & 模型设置
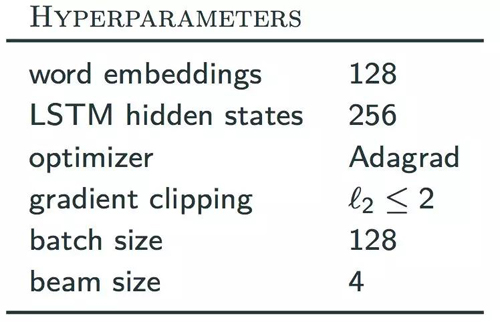
这个工作中,简单起见,我们使用了基于LSTM的encoder和decoder,模型以及优化超参数设置如下:
baseline包括:
- Truncation (Trunc.) 阿里、Amazon.com以及eBay等网站线上所使用的方案,直接截断,保留前n个词。
- TextRank [7] 一种类似于pagerank的关键词提取算法,可以用于生成摘要。
- Seq2Seq-Del [5] 如上文介绍,基于seq2seq的deletion based的抽取式摘要算法。
- LSTM-Del 与Seq2Seq-Del的不同在于直接在encoder的输出预测单词保留与否。
- Pointer network (Ptr-Net) [4] 见模型部分介绍。
- Ptr-Concat 将background knowledge与title拼接后,使用Ptr-Net。
- Vanilla sequence-to-sequence (Seq2Seq-Gen) 传统的seq2seq普通,abstractive的方法。
- Pointer-Generator(Ptr-Gen) Ptr-Net与Seq2Seq-Gen的结合。
评价标准
跟大多数文本生成任务一样,文本摘要评测一直是一个困难的任务,常见评测方法包括人工评测和自动评测。对于自动评测方法,我们使用了BLUE、ROUGE和METEOR三个指标。我们使用nlg-eval包计算 BLEU [8]和METEOR [10];pythonrouge计算ROUGE F1 [9]。此外,我们也人工评测了模型生成的短标题的质量。
自动评测
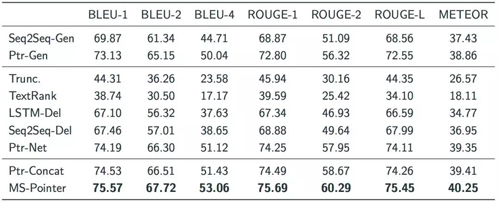
可以发现直接截断和TextRank的结果最差,因为这两个方法都没有考虑标题中单词的语义信息。同时,基于seq2seq框架的模型均取得了很高的得分,这说明seq2seq这个框架强大的拟合能力,在这个简单任务上优异性能。相比abstractive模型,extractive模型在各项指标上表现的更加优异。相比Ptr-Net和Ptr-Concat,MS-Pointer在各项指标上均有明显提升。
品牌保留实验
如前文所述,对于电商领域的商品短标题生成,品牌、品类词这类关键信息的保留是一个至关重要的指标。但由于品类词是一个比较笼统的概念,很多时候类似于类目,他在商品的标题中未必原封不动地出现,所以难以自动地评价。所幸,我们可以很容易地自动化测试模型是否完整地保留下了商品的品牌信息。错误率结果如下表:
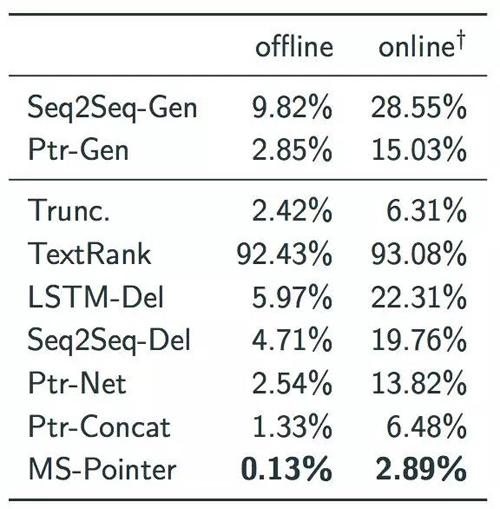
容易看出MS-Pointer显著优于其他模型,在测试集上的错误率降低到了接近千分之一。这里online数据集指的是从线上随机采样的140166个商品标题。值得说明的是在线上的online数据集中存在大量训练语料中没有出现过的品牌,当输入标题中存在多个oov单词时,模型难以从这些相同的oov embedding中选择出正确的词。针对这个问题,我们尝试在这些oov赋以不同的embedding加以区分,在此情况下online数据集上的错误率可以降低到0.56%.
人工评测
此外,我们随机采样了300条短标题进行了人工评测,主要考虑了四个维度, 核心产品词识别准确率Accuracy(0/1),品类词完整性Comm. (0/1),可读性 Readability(1~5)以及信息完整性 Info.(1~5),结果如下:
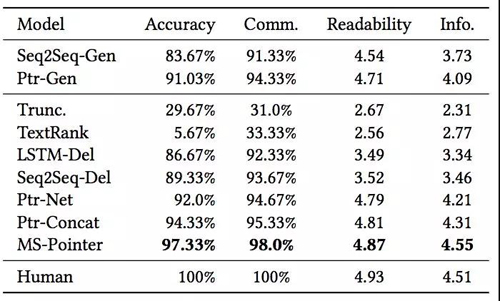
人工评测结果同样说明了MS-Pointer方法相对其他方法的优势,并且可以发现与人工写的短标题得分非常相近。
线上实验
除了前文的离线实验,我们同样进行了线上实验对比。两个分桶的差异只有结果展示标题不同:一个分桶是线上原油方案截断的两行标题;另一个是模型产生的8~10个字的短标题。因此展示标题的不同,直接影响用户点击与否,因此这里选用CTR作为实验指标。试验持续了一周时间,结果如下图:
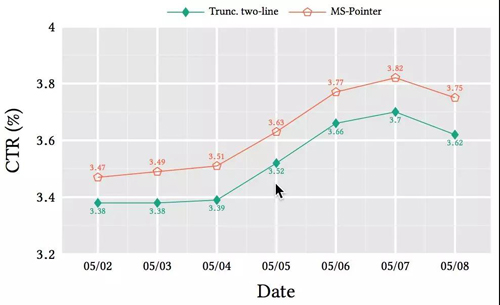
这里统计的是分桶内部,pv>20以上商品的平均CTR。可以发现,使用生成的短标题可以明显提升。更进一步地分析发现,不同类目下商品的CTR变化非常不一样。如电子产品类商品的CTR提升甚至可以达到10%;而女性用户更加关注的类目如女装、化妆品类目CTR提升则较小。这是因为女性用户在浏览这些类目的推荐结果时,对于修饰形容词汇(如衣服的款式、材质,化妆品的功效等)会比较关注,而10个字以内的短标题毕竟有损,往往难以包含所有这些信息。而电子产品这些类目,往往品牌型号加上品类词就已足够包含所有信息,过多的冗余信息反而带来干扰。这也说明个性化的短标题生成以及如何引入CTR指标,是一个值得探索的方向。当然更加复杂的knowledge的引入,也是一个值得探索的方向。
Reference:
[1] Alexander M. Rush, Sumit Chopra, and Jason Weston. 2015. A Neural Attention Model for Abstractive Sentence Summarization. In Proceedings of EMNLP. Association for Computational Linguistics, Lisbon, Portugal, 379–389.
[2] Sumit Chopra, Michael Auli, and Alexander M. Rush. 2016. Abstractive Sentence Summarization with Attentive Recurrent Neural Networks. In Proceedings of NAACL. Association for Computational Linguistics, San Diego, California, 93– 98.
[3] Abigail See, Peter J. Liu, and Christopher D. Manning. 2017. Get To The Point: Summarization with Pointer-Generator Networks. In Proceedings of ACL. Association for Computational Linguistics, Vancouver, Canada, 1073–1083.
[4] Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. 2015. Pointer Networks. In Proceedings of NIPS, C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett (Eds.). Curran Associates, Inc., 2692–2700.
[5] Katja Filippova, Enrique Alfonseca, Carlos A. Colmenares, Lukasz Kaiser, and Oriol Vinyals. 2015. Sentence Compression by Deletion with LSTMs. In Proceedings of EMNLP. Association for Computational Linguistics, Lisbon, Portugal, 360–368.
[6] Hongyan Jing. 2002. Using Hidden Markov Modeling to Decompose Human-written Summaries. Comput. Linguist. 28, 4 (Dec. 2002), 527–543.
[7] Rada Mihalcea and Paul Tarau. 2004. TextRank: Bringing Order into Texts. In Proceedings of EMNLP 2004. Association for Computational Linguistics, Barcelona, Spain, 404–411.
[8] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a Method for Automatic Evaluation of Machine Translation. In Proceedings of ACL. Association for Computational Linguistics, Philadelphia, Pennsylvania, USA, 311–318. https://doi.org/10.3115/1073083.1073135
[9] Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out: Proceedings of the ACL-04 Workshop.
[10] Satanjeev Banerjee and Alon Lavie. 2005. METEOR: An Automatic Metricfor MT Evaluation with Improved Correlation with Human Judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. Association for Computational Linguistics, Michigan, 65–72.
【本文为51CTO专栏作者“阿里巴巴官方技术”原创稿件,转载请联系原作者】















