【51CTO.com快译】 Redis是一种内存中的多模式数据库,适用于诸多使用场合,包括内容缓存、会话存储、实时分析、消息代理和数据流。去年,我撰文介绍了如何使用Redis Pub/Sub、Lists和Sorted Sets用于实时数据流处理,详见https://www.infoworld.com/article/3212768/database/how-to-use-redis-for-real-time-stream-processing.html。现在Redis 5.0已发布,Redis有了一种全新的数据结构来管理数据流。
有了Redis Streams数据结构,可以执行比Pub/Sub、Lists和Sorted Sets丰富得多的操作。Redis Streams有众多优点,它让你能够执行下列操作:
- 收集大量高速传来的数据(唯一的瓶颈是你的网络I/O);
- 在许多生产者和许多消费者之间建立数据通道;
- 即使生产者和消费者运作的速度不一样,也能高效地管理数据的消费;
- 你的消费者离线或断开连接时确保数据持久化;
- 在生产者和消费者之间异步通信;
- 扩大消费者的数量;
- 消费者在消费数据过程中失效时,实现类似事务的数据安全性;
- 有效地使用主内存。
Redis Streams的最大优点是它内置于Redis中,因此部署或管理Redis Streams无需额外的步骤。我在本文中将逐步介绍使用Redis Streams的基本方面,包括如何将数据添加到数据流、如何读取数据(一次性读取、异步读取和到达时读取等),以满足消费者的不同使用场合。
一、了解Redis Streams中的数据流
Redis Streams提供了一种“只允许追加”(append only)的数据结构,与日志类似。它提供了可以将数据源添加到数据流、使用数据流以及监控和管理如何消费数据的命令。 Streams数据结构很灵活,让你可以以几种方式来连接生产者和消费者。

图1. Redis Streams的简单应用,只有一个生产者和一个消费者
图1表明了Redis Streams的基本用法。单单一个生产者充当数据源,消费者是将数据发送给相关接收者的消息传递应用程序。

图2.多个消费者从Redis Streams读取数据的应用
图2中,一个公共数据流被多个消费者使用。使用Redis Streams,消费者可以按照自己的节奏来读取和分析数据。
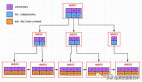
在下一个应用中,如图3所示,情况变得复杂一点。该服务从多个生产者接收数据,并将所有数据存储在Redis Streams数据结构中。该应用有多个消费者从Redis Streams读取数据,读取数据的还有消费者组(consumer group),消费者组支持无法与生产者保持同样速度的消费者。

图3. Redis Streams支持多个生产者和消费者
二、用Redis Streams将数据添加到数据流
图3中的图表只显示了向Redis Stream添加数据的一种方法。虽然一个或多个生产者可以向数据结构添加数据,但任何新数据始终追加到数据流的末尾。
1.添加数据的默认方法
这是向Redis Streams添加数据的最简单方法:
XADD mystream * name Anna
XADD mystream * name Bert
XADD mystream * name Cathy
- 1.
- 2.
- 3.
在上述命令中,XADD是Redis命令,mystream是数据流的名称,Anna、Bert和Cathy是每一行添加的名称,而*操作符告诉Redis为每一行自动生成识别符。这个命令得出三个mystream条目:
1518951481323-0 name Cathy
1518951480723-0 name Bert
1518951480106-0 name Anna
- 1.
- 2.
- 3.
2.针对每个条目,为数据添加用户管理的ID
Redis让你可以为每个条目维护你自己的识别符(见下面)。虽然这在一些情况下很有用,但依赖自动生成的ID通常来得更简单:
XADD mystream 10000000 name Anna
XADD mystream 10000001 name Bert
XADD mystream 10000002 name Cathy
- 1.
- 2.
- 3.
这得出下列的mystream条目:
10000002-0 name Cathy
10000001-0 name Bert
10000000-0 name Anna
- 1.
- 2.
- 3.
3.为数据添加最大限制
你可以为数据流设置条目最大数:
XADD mystream MAXLEN 1000000 * name Anna
XADD mystream MAXLEN 1000000 * name Bert
XADD mystream MAXLEN 1000000 * name Cathy
- 1.
- 2.
- 3.
数据流达到1000000个左右条目的长度时,该命令驱逐旧条目。
一个小贴士:Redis Streams将数据存储在基树(radix tree)的宏节点中。每个宏节点有几个数据项(通常在几十个左右)。如果添加一个近似的MAXLEN值(如下所示),就没必要为每次插入处理宏节点。如果几十个数(比如1000000或1000050)对你来说关系不大,可以用近似字符(~)来调用命令,从而优化性能。
XADD mystream MAXLEN ~ 1000000 * name Anna
XADD mystream MAXLEN ~ 1000000 * name Bert
XADD mystream MAXLEN ~ 1000000 * name Cathy
- 1.
- 2.
- 3.
三、用Redis Streams消费来自数据流的数据
Redis Streams结构提供了一套丰富的命令和功能,以便以多种方式消费数据。
1.从数据流的开头读取所有内容
场景:数据流已含有你需要处理的数据,而且你想从开头开始处理数据。
为此你要使用的命令是XREAD,它让你可以从数据的开头读取所有或前N个条目。一条最佳实践是,逐页读取数据始终是好主意。想从数据流的开头读取多达100个条目,命令是:
XREAD COUNT 100 STREAMS mystream 0
- 1.
假设1518951481323-0是你在上一个命令中收到的数据项的最后一个ID,你可以运行该命令,检索下100个条目:
XREAD COUNT 100 STREAMS mystream 1518951481323-1
- 1.
2.异步消费数据(通过阻塞调用)
场景:你的消费者消费和处理数据的速度比数据添加到数据流的速度还快。
在许多使用场合下,消费者读取的速度比生产者向数据流添加数据的速度还快。这种情况下,你希望消费者等待、新数据到达时接到通知。BLOCK选项让你可以指定等待新数据的时长:
XREAD BLOCK 60000 STREAMS mystream 1518951123456-1
- 1.
在这里,XREAD返回1518951123456-1之后的所有数据。如果之后没有数据,查询将等待N= 60秒,直至新数据到达,然后超时中断。如果你想要无限期地阻止该命令,按如下方式调用XREAD:
XREAD BLOCK 0 STREAMS mystream 1518951123456-1
- 1.
注意:在该示例中,你还可以使用XRANGE命令来逐页检索数据。
3.只读取刚到达的新数据
场景:你只对处理从当前时间点开始的新数据集有兴趣。
你反复读取数据时,从上次停下来的地方重新开始始终是个好主意。比如在前一个示例中,你进行了阻塞调用以读取大于1518951123456-1的数据。然而,你可能不知道最新的ID。在这种情况下,可以用$符号开始读取数据流,该符号告诉XREAD命令只检索新数据。由于该调用使用的BLOCK选项是60秒,它将等到数据流中有一些数据。
XREAD BLOCK 60000 STREAMS mystream $
- 1.
这种情况下,你将开始用$选项读取新数据。然而,不该用$选项进行后续调用。比如说,如果1518951123456-0是之前调用中检索的数据的ID,你的下一个调用应该是:
XREAD BLOCK 60000 STREAMS mystream 1518951123456-1
- 1.
4.迭代数据流以读取过去的数据
场景:你的数据流已有足够的数据,你想查询它已分析到目前为止收集的数据。
可以分别使用XRANGE和XREVRANGE,以向前或向后的方向读取两个条目之间的数据。在该示例中,命令读取1518951123450-0和1518951123460-0之间的数据:
XRANGE mystream 1518951123450-0 1518951123460-0
- 1.
XRANGE还让你可以借助COUNT选项,限制返回的数据项数量。比如说,下列查询返回两个间隔之间的前10个数据项。使用该选项,你可以像使用SCAN命令一样迭代数据流:
XRANGE mystream 1518951123450-0 1518951123460-0 COUNT 10
- 1.
如果你不知道查询的上限或下限,可以将下限换成-、将上限换成+。比如说,下列查询返回从数据开头的前10个数据项:
XRANGE mystream - + COUNT 10
- 1.
XREVRANGE的语法类似XRANGE,只是下限和上限的顺序倒过来。比如说,下列查询以相反的顺序返回数据流末尾的前10个数据项:
XREVRANGE mystream + - COUNT 10
- 1.
5.在多个消费者之间划分数据
场景:消费者消费数据的速度远低于生产者生成数据的速度。
在某些情况下,包括图像处理、深度学习和情感分析,消费者与生产者相比可能很慢。这种情况下,可以通过分散消费者并划分每个消费者消耗的数据的做法,来匹配到达数据的速度与消耗数据的速度。
使用Redis Streams,你可以利用消费者组来完成此任务。多个消费者是消费者组的一部分时,Redis Streams将确保每个消费者都收到一组独有的数据。
XREADGROUP GROUP mygroup consumer1 COUNT 2 STREAMS mystream >
- 1.
当然,关于消费者组如何运作还有更多的东西要了解。Redis Streams消费者组旨在划分数据、实现灾难恢复并提供事务数据安全性。
如你所见,Redis Streams很容易上手。只需下载并安装Redis 5.0,然后钻研该项目网站上的Redis Streams教程。
原文标题:How to use Redis Streams,作者:Roshan Kumar
作者简介:Roshan Kumar是Redis Labs的资深产品经理。他在软件开发和技术营销方面有着丰富的从业经验。Roshan曾供职于惠普和多家成功的硅谷初创公司,包括ZillionTV、 Salorix、Alopa和ActiveVideo。
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】