一、聊什么
上一篇《Apache Flink 漫谈系列 - JOIN算子》我们对最常见的JOIN做了详尽的分析,本篇介绍一个特殊的JOIN,那就是JOIN LATERAL。JOIN LATERAL为什么特殊呢,直观说因为JOIN的右边不是一个实际的物理表,而是一个VIEW或者Table-valued Funciton。本篇会先介绍传统数据库对LATERAL JOIN的支持,然后介绍Apache Flink目前对LATERAL JOIN的支持情况。
二、实际问题
假设我们有两张表,一张是Customers表(消费者id, 所在城市), 一张是Orders表(订单id,消费者id),两张表的DDL(SQL Server)如下:
- Customers
- CREATE TABLE Customers (
- customerid char(5) NOT NULL,
- city varchar (10) NOT NULL
- )
- insert into Customers values('C001','Beijing');
- insert into Customers values('C002','Beijing');
- insert into Customers values('C003','Beijing');
- insert into Customers values('C004','HangZhou');
查看数据:
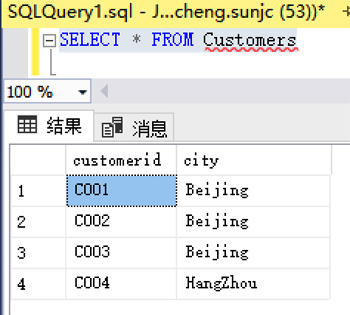
- Orders
- CREATE TABLE Orders(
- orderid char(5) NOT NULL,
- customerid char(5) NULL
- )
- insert into Orders values('O001','C001');
- insert into Orders values('O002','C001');
- insert into Orders values('O003','C003');
- insert into Orders values('O004','C001');
查看数据:
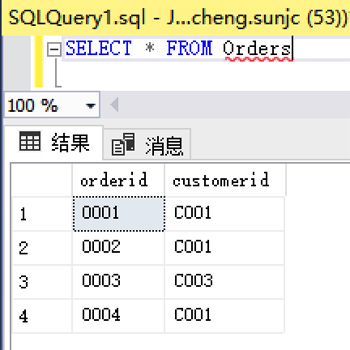
1. 问题示例
假设我们想查询所有Customers的客户ID,地点和订单信息,我们想得到的信息是:
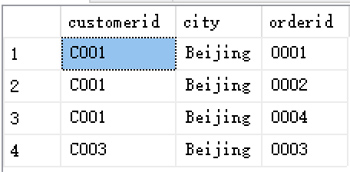
(1) 用INNER JOIN解决
如果大家查阅了《Apache Flink 漫谈系列 - JOIN算子》,我想看到这样的查询需求会想到INNER JOIN来解决,SQL如下:
- SELECT
- c.customerid, c.city, o.orderid
- FROM Customers c JOIN Orders o
- ON o.customerid = c.customerid
查询结果如下:
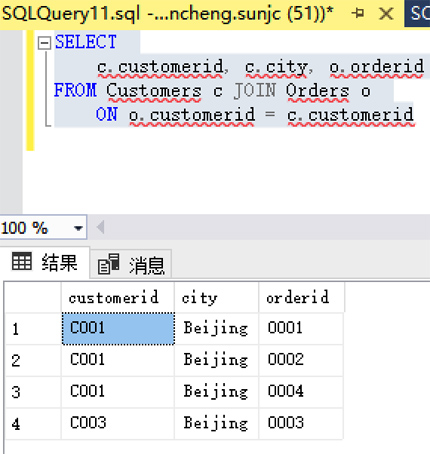
但如果我们真的用上面的方式来解决,就不会有本篇要介绍的内容了,所以我们换一种写法。
2. 用 Correlated subquery解决
Correlated subquery 是在subquery中使用关联表的字段,subquery可以在FROM Clause中也可以在WHERE Clause中。
- WHERE Clause
用WHERE Clause实现上面的查询需求,SQL如下:
- SELECT
- c.customerid, c.city
- FROM Customers c WHERE c.customerid IN (
- SELECT
- o.customerid, o.orderid
- FROM Orders o
- WHERE o.customerid = c.customerid
- )
执行情况:

上面的问题是用在WHERE Clause里面subquery的查询列必须和需要比较的列对应,否则我们无法对o.orderid进行投影, 上面查询我为什么要加一个o.orderid呢,因为查询需求是需要o.orderid的,去掉o.orderid查询能成功,但是拿到的结果并不是我们想要的,如下:
- SELECT
- c.customerid, c.city
- FROM Customers c WHERE c.customerid IN (
- SELECT
- o.customerid
- FROM Orders o
- WHERE o.customerid = c.customerid
- )
查询结果:
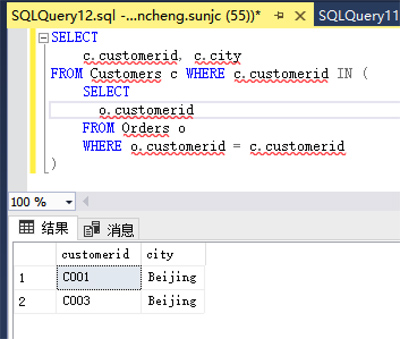
可见上面查询结果缺少了o.orderid,不能满足我们的查询需求。
- FROM Clause
用WHERE Clause实现上面的查询需求,SQL如下:
- SELECT
- c.customerid, c.city, o.orderid
- FROM Customers c, (
- SELECT
- o.orderid, o.customerid
- FROM Orders o
- WHERE o.customerid = c.customerid
- ) as o
我们会得到如下错误:
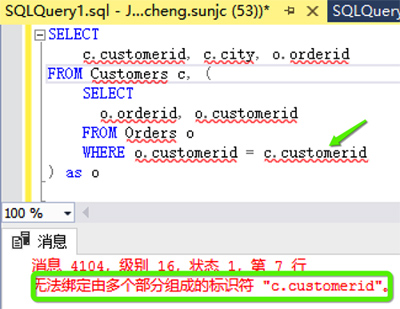
错误信息提示我们无法识别c.customerid。在ANSI-SQL里面FROM Clause里面的subquery是无法引用左边表信息的,所以简单的用FROM Clause里面的subquery,也无法解决上面的问题,
那么上面的查询需求除了INNER JOIN 我们还可以如何解决呢?
三、JOIN LATERAL
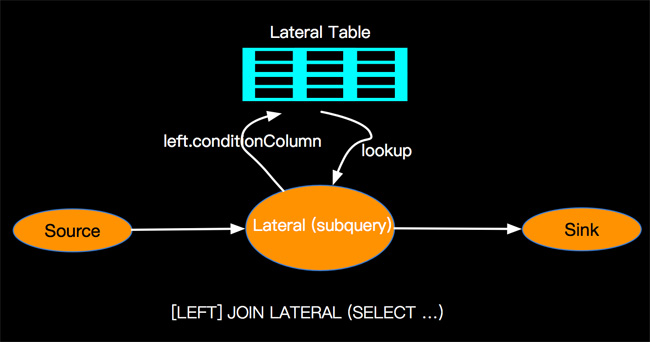
我们分析上面的需求,本质上是根据左表Customers的customerid,去查询右表的Orders信息,就像一个For循环一样,外层是遍历左表Customers所有数据,内层是根据左表Customers的每一个Customerid去右表Orders中进行遍历查询,然后再将符合条件的左右表数据进行JOIN,这种根据左表逐条数据动态生成右表进行JOIN的语义,SQL标准里面提出了LATERAL关键字,也叫做 lateral drive table。
1. CROSS APPLY和LATERAL
上面的示例我们用的是SQL Server进行测试的,这里在多提一下在SQL Server里面是如何支持 LATERAL 的呢?SQL Server是用自己的方言 CROSS APPLY 来支持的。那么为啥不用ANSI-SQL的LATERAL而用CROSS APPLY呢? 可能的原因是当时SQL Server为了解决TVF问题而引入的,同时LATERAL是SQL2003引入的,而CROSS APPLY是SQL Server 2005就支持了,SQL Server 2005的开发是在2000年就进行了,这个可能也有个时间差,等LATERAL出来的时候,CROSS APPLY在SQL Server里面已经开发完成了。所以种种原因SQL Server里面就采用了CROSS APPLY,但CROSS APPLY的语义与LATERAL却完全一致,同时后续支持LATERAL的Oracle12和PostgreSQL94同时支持了LATERAL和CROSS APPLY。
2. 问题解决
那么我们回到上面的问题,我们用SQL Server的CROSS APPLY来解决上面问题,SQL如下:
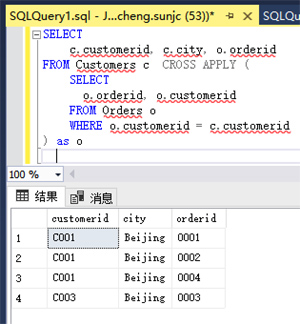
上面得到的结果完全满足查询需求。
四、JOIN LATERAL 与 INNER JOIN 关系
上面的查询需求并没有体现JOIN LATERAL和INNER JOIN的区别,我们还是以SQL Server中两个查询执行Plan来观察一下:
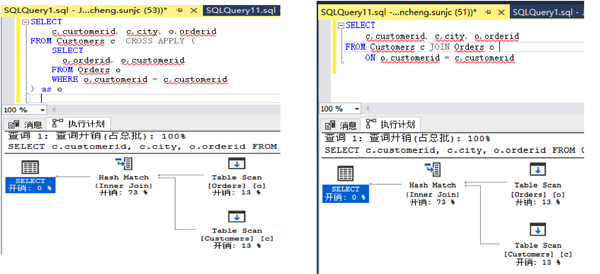
上面我们发现经过SQL Server优化器优化之后的两个执行plan完全一致,那么为啥还要再造一个LATERAL 出来呢?
1. 性能方面
我们将上面的查询需求稍微改变一下,我们查询所有Customer和Customers的***份订单信息。
- LATERAL 的写法
- SELECT
- c.customerid, c.city, o.orderid
- FROM Customers c CROSS APPLY (
- SELECT
- ***) o.orderid, o.customerid
- FROM Orders o
- WHERE o.customerid = c.customerid
- ORDER BY o.customerid, o.orderid
- ) as o
查询结果:

我们发现虽然C001的Customer有三笔订单,但是我们查询的***信息。
- JOIN 写法
- SELECT c.customerid, c.city, o.orderid
- FROM Customers c
- JOIN (
- SELECT
- o2.*,
- ROW_NUMBER() OVER (
- PARTITION BY customerid
- ORDER BY orderid
- ) AS rn
- FROM Orders o2
- ) o
- ON c.customerid = o.customerid AND o.rn = 1
查询结果:
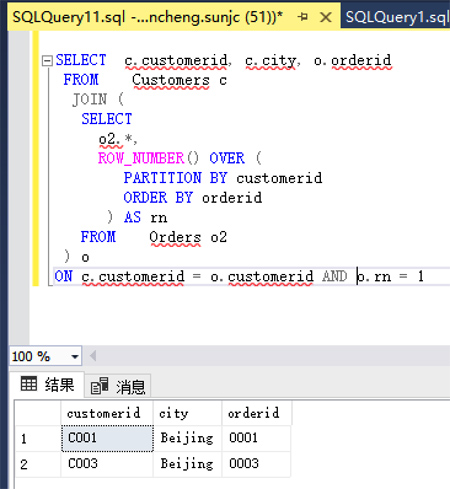
如上我们都完成了查询需求,我们在来看一下执行Plan,如下:
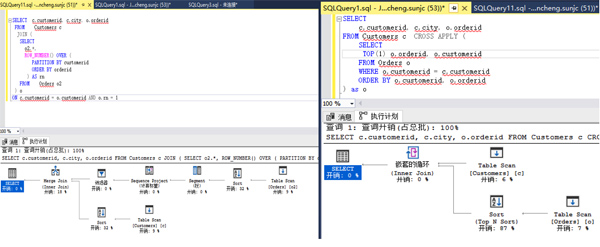
我们直观发现完成相同功能,使用CROSS APPLY进行查询,执行Plan简单许多。
2. 功能方面
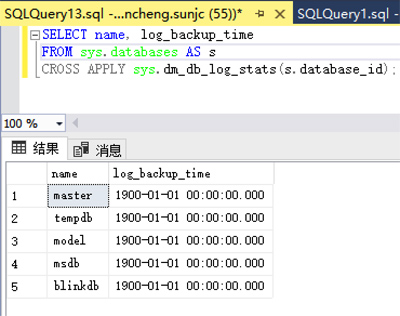
在功能方面INNER JOIN本身在ANSI-SQL中是不允许 JOIN 一个Function的,这也是SQL Server当时引入CROSS APPLY的根本原因。我们以一个SQL Server中DMV(相当于TVF)查询为例:
- SELECT
- name, log_backup_time
- FROM sys.databases AS s
- CROSS APPLY sys.dm_db_log_stats(s.database_id);
查询结果:
五、Apache Flink对 LATERAL的支持
前面我花费了大量的章节来向大家介绍ANSI-SQL和传统数据库以SQL Server为例如何支持LATERAL的,接下来我们看看Apache Flink对LATERAL的支持情况。
1. Calcite
Apache Flink 利用 Calcite进行SQL的解析和优化,目前Calcite完全支持LATERAL语法,示例如下:
- SELECT
- e.NAME, e.DEPTNO, d.NAME
- FROM EMPS e, LATERAL (
- SELECT
- *
- FORM DEPTS d
- WHERE e.DEPTNO=d.DEPTNO
- ) as d;
查询结果:
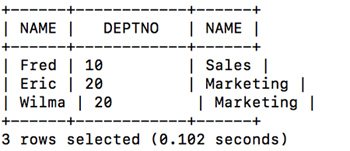
我使用的是Calcite官方自带测试数据。
2. Flink
截止到Flink-1.6.2,Apache Flink 中有两种场景使用LATERAL,如下:
- UDTF(TVF) - User-defined Table Funciton
- Temporal Table - 涉及内容会在后续篇章单独介绍。
本篇我们以在TVF(UDTF)为例说明 Apache Fink中如何支持LATERAL。
(1) UDTF
UDTF- User-defined Table Function是Apache Flink中三大用户自定义函数(UDF,UDTF,UDAGG)之一。 自定义接口如下:
- 基类
- /**
- * Base class for all user-defined functions such as scalar functions, table functions,
- * or aggregation functions.
- */
- abstract class UserDefinedFunction extends Serializable {
- // 关键是FunctionContext中提供了若干高级属性(在UDX篇会详细介绍)
- def open(context: FunctionContext): Unit = {}
- def close(): Unit = {}
- }
- TableFunction
- /**
- * Base class for a user-defined table function (UDTF). A user-defined table functions works on
- * zero, one, or multiple scalar values as input and returns multiple rows as output.
- *
- * The behavior of a [[TableFunction]] can be defined by implementing a custom evaluation
- * method. An evaluation method must be declared publicly, not static and named "eval".
- * Evaluation methods can also be overloaded by implementing multiple methods named "eval".
- *
- * User-defined functions must have a default constructor and must be instantiable during runtime.
- *
- * By default the result type of an evaluation method is determined by Flink's type extraction
- * facilities. This is sufficient for basic types or simple POJOs but might be wrong for more
- * complex, custom, or composite types. In these cases [[TypeInformation]] of the result type
- * can be manually defined by overriding [[getResultType()]].
- */
- abstract class TableFunction[T] extends UserDefinedFunction {
- // 对于泛型T,如果是基础类型那么Flink框架可以自动识别,
- // 对于用户自定义的复杂对象,需要用户overwrite这个实现。
- def getResultType: TypeInformation[T] = null
- }
上面定义的核心是要求用户实现eval方法,我们写一个具体示例。
- 示例
- // 定义一个简单的UDTF返回类型,对应接口上的 T
- case class SimpleUser(name: String, age: Int)
- // 继承TableFunction,并实现evale方法
- // 核心功能是解析以#分割的字符串
- class SplitTVF extends TableFunction[SimpleUser] {
- // make sure input element's format is "<string>#<int>"
- def eval(user: String): Unit = {
- if (user.contains("#")) {
- val splits = user.split("#")
- collect(SimpleUser(splits(0), splits(1).toInt))
- }
- }}
(2) 示例(完整的ITCase):
- 测试数据
我们构造一个只包含一个data字段的用户表,用户表数据如下:
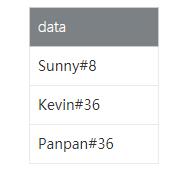
- 查询需求
查询的需求是将data字段flatten成为name和age两个字段的表,期望得到:
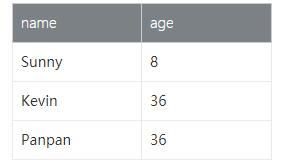
- 查询示例
我们以ITCase方式完成如上查询需求,完整代码如下:
- @Test
- def testLateralTVF(): Unit = {
- val env = StreamExecutionEnvironment.getExecutionEnvironment
- val tEnv = TableEnvironment.getTableEnvironment(env)
- env.setStateBackend(getStateBackend)
- StreamITCase.clear
- val userData = new mutable.MutableList[(String)]
- userData.+=(("Sunny#8"))
- userData.+=(("Kevin#36"))
- userData.+=(("Panpan#36"))
- val SQLQuery = "SELECT data, name, age FROM userTab, LATERAL TABLE(splitTVF(data)) AS T(name, age)"
- val users = env.fromCollection(userData).toTable(tEnv, 'data)
- val tvf = new SplitTVF()
- tEnv.registerTable("userTab", users)
- tEnv.registerFunction("splitTVF", tvf)
- val result = tEnv.SQLQuery(SQLQuery).toAppendStream[Row]
- result.addSink(new StreamITCase.StringSink[Row])
- env.execute()
- StreamITCase.testResults.foreach(println(_))
- }
运行结果:

上面的核心语句是:
- val SQLQuery = "SELECT data, name, age FROM userTab, LATERAL TABLE(splitTVF(data)) AS T(name, age)"
如果大家想运行上面的示例,请查阅《Apache Flink 漫谈系列 - SQL概览》中 源码方式 搭建测试环境。
六、小结
本篇重点向大家介绍了一种新的JOIN类型 - JOIN LATERAL。并向大家介绍了SQL Server中对LATERAL的支持方式,详细分析了JOIN LATERAL和INNER JOIN的区别与联系,***切入到Apache Flink中,以UDTF示例说明了Apache Flink中对JOIN LATERAL的支持,后续篇章会介绍Apache Flink中另一种使用LATERAL的场景,就是Temporal JION,Temporal JION也是一种新的JOIN类型,我们下一篇再见!
关于点赞和评论
本系列文章难免有很多缺陷和不足,真诚希望读者对有收获的篇章给予点赞鼓励,对有不足的篇章给予反馈和建议,先行感谢大家!
作者:孙金城,花名 金竹,目前就职于阿里巴巴,自2015年以来一直投入于基于Apache Flink的阿里巴巴计算平台Blink的设计研发工作。
【本文为51CTO专栏作者“金竹”原创稿件,转载请联系原作者】