













随着持续集成,持续交付等理念的传播,很多软件开发团队都搭建了自己的staging、UAT等类生产环境。这些环境的软硬件及网络配置会尽量贴近真实的生产环境,起到沙盘演练的作用。
类生产环境毕竟前面还有一个类字,沙盘毕竟不是真实的战场,尽量贴近毕竟还不是完全吻合。
类生产环境与真实生产环境的一个重要差异就是访问量。稍具规模的互联网应用每天几百万访问量是很正常的,而类生产环境的访问量一般都会相形见绌。
有各种工具可以弥合这个差异,比如Apache JMeter,Gatling。测试人员可以和开发人员一起设计测试用例,以自动化或者半自动化的方式对类生产环境进行压力测试。
不过即便是精心设计出来的用例也还是用例,不是真实请求。真实请求具有多样性,会随着昼夜交替而变化,会随着时事热点而波动,这是很难用工具模拟出来的。
这就引出了这篇文章的主角-影子流量(shadow traffic)。
简言之,影子流量(shadow traffic)就是将发给生产环境的请求复制一份转发到类生产环境上去,以此来达到压力测试和正确性测试的目的。
这就如同把真实战场上的敌方炮火投放到演习场里去。
一、实现方式
Shadow traffic通常有两种实现方式:服务端实现,客户端实现。
下图描述的是服务端实现的简化示例。

生产环境接收到来自于用户或者是上游系统的请求,在响应该请求的同时,将这个请求原封不动的也发送给类生产环境。
下图描述的是客户端的实现。

客户设备或者上游系统在发给生产环境请求的同时,给类生产环境也发送一个一模一样的请求。
这两种实现方式各有优劣,放到服务端做可以减少客户端设备的流量消耗,这一点对于移动应用很重要。
客户端的实现则较简单,通常只需要几行代码即可。如果后端架构较复杂,则可以选择前端实现。
无论前端还是后端实现,都需要遵循发射后不管(fire and forget)的原则,以免阻塞正常流程或者增加响应时间。
1. 适用场景
笼统来说,shadow traffic可以适用于所有互联网应用。而在以下场景中,shadow traffic的作用格外明显:
- 要用新系统替换掉老旧系统
- 系统经历了大规模改造,直接上线面对客户风险较大
- 系统更新,需要提供向后兼容性
- 试验性质的架构调整
在以上场景运用shadow traffic,可以在不影响终端用户的情况下完成验证与测试。
2. 启用时机
在上线之前一段时间集中地进行测试固然是一种可行的方式,不过我个人更倾向于在项目运转的早期引入shadow traffic。
这样做可以让开发团队尽早的并且持续的接触到真实的外界压力。相当于用一种成本并不怎么高的方式构建出了具有产品运维经验的开发团队。
二、配套机制
Shadow traffic的原理和实现方式并不深奥,但要让它发挥出应有的价值还需要一些前期工作的配合。
1. 基础设施监控
要了解系统的表现,基础设施监控是必不可少的。
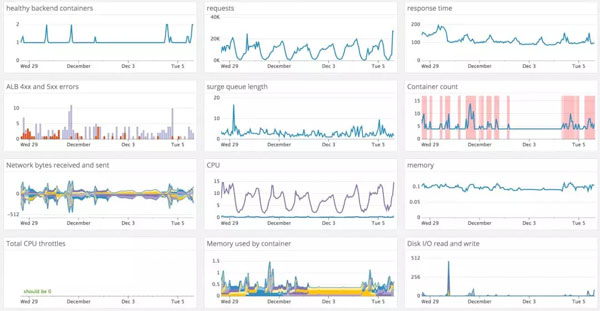
上图是我所经历过的一个项目的可视化监控界面。监控范围涵盖了docker container的数量,请求数量,响应时间,以4或者5打头的HTTP状态码的数量,网络、内存、CPU用量等等。
通过如上的可视化图表,开发团队可以实时得到反馈。
2. 日志
基础设施监控可以提供一个外部视角,日志则能够窥见应用内部。
日志可以帮助开发团队定位shadow traffic中发现的问题,shadow traffic也可以促使开发团队提升日志的质量。这二者可以起到双向的积极促进作用。
3. 下游系统的配合
如果一个系统开启了shadow traffic,可以想见它的下游系统所面对的压力也会陡升。
这时有必要与下游系统负责团队做好事先沟通。
三、用法变式
Shadow traffic并非是一成不变的技术实践,可以按需微调。
1. 请求挑取
并非每一个请求都有被转发的必要。可以优先选取流量大或者业务价值高的请求。
2. 流量控制
如果想做极限压力测试,可以把每一个请求重复发送多次给类生产环境。
当然也可以只挑取10%的请求来发送给类生产环境,随着团队信心的提升而逐步升高。
3. 重播
可以截取并保存每天尖峰时刻的请求,在其他时段反复重播。
这种考验可以有效的锻炼团队的心理素质,并促使团队形成应急预案。
四、小结
如果明天要上线,今天会是一个让人惴惴不安的日子。
系统性能表现如何?会不会有奇形怪状的用户行为导致系统异常?与上下游系统的衔接会不会出现问题?
这些问题的答案,可以通过测试人员的精心模拟来寻找。但仍难免会挂一漏万。
启用shadow traffic,如果开发团队可以习惯于有shadow traffic的日常,也就具有了应对线上运维问题的能力。
【本文是51CTO专栏作者“ThoughtWorks”的原创稿件,微信公众号:思特沃克,转载请联系原作者】

















