当我们工作所在的系统处于分布式系统初期,往往这时候每个服务都只部署了一个节点。
在这样的背景下,如果某个服务 A 需要发布一个新版本,往往会对正在运行的其他依赖服务 A 的程序产生影响。
甚至,一旦服务 A 的启动预热过程耗时过长,问题会更严重,大量请求会阻塞,产生级联影响,导致整个系统卡慢。
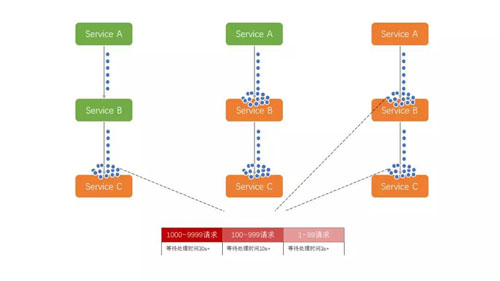
举个夸张的例子来形容:一幢楼的下水管是从最高楼直通到最低楼的,这个时候如果你家楼下的管道口堵住了,那么所有楼上的污水就会倒灌到你家;如果这导致你家的管道口也堵住了,之后又会倒灌到楼上一层,以此类推。
然而实际生活中一旦你发现了这个问题,必然会想办法先避免影响到自己家,然后跑到楼下让他们赶紧疏通管道。此时,避免影响自己家的办法就可被称之为「熔断」。
熔断是什么
熔断本质上是一个过载保护机制。这一概念来源于电子工程中的断路器,可能你曾经被这个东西的“跳闸”保护过。
在互联网系统中的熔断机制是指:当下游服务因访问压力过大而响应变慢或失败,上游服务为了保护自己以及系统整体的可用性,可以暂时切断对下游服务的调用。
做熔断的思路大体上就是:一个中心思想,分四步走。
熔断怎么做
熔断怎么做?首先,你需秉持的一个中心思想是:量力而行。因为软件和人不同,没有奇迹会发生,什么样的性能支撑多少流量是固定的,这是根本。
然后,这四步走分别是:
- 定义一个识别是否处于“不可用”状态的策略
- 切断联系
- 定义一个识别是否处于“可用”状态的策略,并尝试探测
- 重新恢复正常
定义一个识别是否处于“不正常”状态的策略
相信软件开发经验丰富的你也知道,识别一个系统是否正常,无非是两个点:
- 是不是能调通。
- 如果能调通,耗时是不是超过预期时长。
但是,由于分布式系统被建立在一个并不是 100% 可靠的网络上,所以上述的情况总有发生,因此我们不能将偶发的瞬时异常等同于系统“不可用”(避免以偏概全)。
由此我们需要引入一个「时间窗口」的概念,这个时间窗口用来“放宽”判定“不可用”的区间,也意味着多给了系统几次证明自己“可用”机会。
但是,如果系统还是在这个时间窗口内达到了你定义“不可用”标准,那么我们就要“断臂求生”了。
这个标准可以有两种方式来指定:
- 阈值。比如,在 10 秒内出现 100 次“无法连接”或者出现 100 次大于 5 秒的请求。
- 百分比。比如,在 10 秒内有 30% 请求“无法连接”或者 30% 的请求大于5秒。
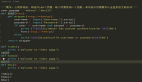
最终会形成这样的一段代码:
- 全局变量 errorcount = 0; //有个独立的线程每隔10秒(时间窗口)重置为0。
- 全局变量 isOpenCircuitBreaker = false;
- //do some thing...
- if(success){
- return success;
- }
- else{
- errorcount++;
- if(errorcount == 不可用阈值){
- isOpenCircuitBreaker = true;
- }
- }
切断联系
切断联系要尽可能的“果断”,既然已经认定了对方“不可用”,那么索性就默认“失败”,避免做无用功,也顺带能缓解对方的压力。
分布式系统中的程序间调用,一般都会通过一些 RPC 框架进行。
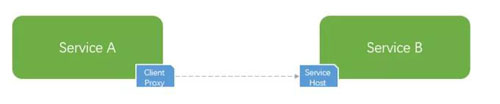
那么,这个时候作为客户端一方,在自己进程内通过代理发起调用之前就可以直接返回失败,不走网络。
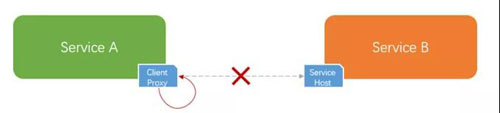
这就是常说的「fail fast」机制。就是在前面提到的代码段之前增加下面的这段代码:
- if(isOpenCircuitBreaker == true){
- return fail;
- }
- //do some thing...
定义一个识别是否处于“可用”状态的策略,并尝试探测
切断联系后,功能的完整性必然会受影响,所以还是需要尽快恢复回来,以提供完整的服务能力。这事肯定不能人为去干预,及时性必然会受到影响。
那么如何能够自动的识别依赖系统是否“可用”呢?这也需要你来定义一个策略。
一般来说这个策略与识别“不可用”的策略类似,只是这里是一个反向指标:
-
阈值。比如,在 10 秒内出现 100 次“调用成功”并且耗时都小于 1 秒。
-
百分比。比如,在 10 秒内有 95% 请求“调用成功”并且 98% 的请求小于1秒。
同样包含「时间窗口」、「阈值」以及「百分比」。稍微不同的地方在于,大多数情况下,一个系统“不可用”的状态往往会持续一段时间,不会那么快就恢复过来。
所以我们不需要像第一步中识别“不可用”那样,无时无刻的记录请求状况,而只需要在每隔一段时间之后去进行探测即可。
所以,这里多了一个「间隔时间」的概念。这个间隔幅度可以是固定的,比如 30 秒。也可以是动态增加的,通过线性增长或者指数增长等方式。
这个用代码表述大致是这样:
- 全局变量 successCount = 0;
- //有个独立的线程每隔10秒(时间窗口)重置为0。
- //并且将下面的isHalfOpen设为false。
- 全局变量 isHalfOpen = true;
- //有个独立的线程每隔30秒(间隔时间)重置为true。
- //do some thing...
- if(success){
- if(isHalfOpen){
- successCount ++;
- if(successCount = 可用阈值){
- isOpenCircuitBreaker = false;
- }
- }
- return success;
- }
- else{
- errorcount++;
- if(errorcount == 不可用阈值){
- isOpenCircuitBreaker = true;
- }
- }
另外,尝试探测本质上是一个“试错”,要控制下“试错成本”。所以我们不可能拿 100% 的流量去验证,一般会有以下两种方式:
-
放行一定比例的流量去验证。
-
如果在整个通信框架都是统一的情况下,还可以统一给每个系统增加一个专门用于验证程序健康状态检测的独立接口。
这个接口额外可以多返回一些系统负载信息用于判断健康状态,如 CPU、I/O 的情况等。
重新恢复正常
一旦通过了衡量是否“可用”的验证,整个系统就恢复到了“正常”状态,此时需要重新开启识别“不可用”的策略。
就这样,系统会形成一个循环,如下图:
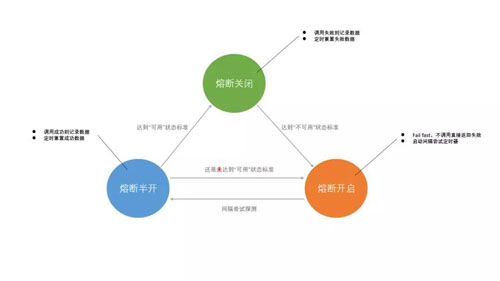
这就是一个完整的熔断机制的面貌。了解了这些核心思想,用什么框架去实施就变得不是那么重要了,因为大部分都是换汤不换药。
上面聊到的这些可以说是主干部分,还有一些最佳实践可以让你在实施熔断的时候拿捏的更到位。
做熔断的最佳实践
什么场景最适合做熔断
一个事物在不同的场景里会发挥出不同的效果。以下是我能想到最适合熔断发挥更大优势的几个场景:
-
所依赖的系统本身是一个共享系统,当前客户端只是其中的一个客户端。这是因为,如果其他客户端进行胡乱调用也会影响到你的调用。
-
所有依赖的系统被部署在一个共享环境中(资源未做隔离),并不独占使用。比如,和某个高负荷的数据库在同一台服务器上。
-
所依赖的系统是一个经常会迭代更新的服务。这点也意味着,越“敏捷”的系统越需要“熔断”。
-
当前所在的系统流量大小是不确定的。比如,一个电商网站的流量波动会很大,你能抗住突增的流量不代表所依赖的后端系统也能抗住。这点也反映出了我们在软件设计中带着“面向怀疑”的心态的重要性。
做熔断时还要注意的一些地方
与所有事物一样,熔断也不是一个完美的事物,我们特别需要注意两个问题。
首先,如果所依赖的系统是多副本或者做了分区的,那么要注意其中个别节点的异常并不等于所有节点都存在异常,需要区别对待。
其次,熔断往往应作为最后的选择,我们应优先使用一些「降级」或者「限流」方案。
因为“部分胜于无”,虽然无法提供完整的服务,但尽可能的降低影响是要持续去努力的。
比如,抛弃非核心业务、给出友好提示等等,这部分内容我们会在后续的文章中展开。
总结
本文主要聊了熔断的作用以及做法,并且总结了一些我自己的最佳实践。
从上面的这些代码示例中也可以看到,熔断代码所在的位置要么在实际方法之前,要么在实际方法之后。
它非常适合 AOP 编程思想的发挥,所以我们平常用到的熔断框架都会基于 AOP 去做。
熔断只是一个保护壳,在周围出现异常的时候保全自身。但是从长远来看平时定期做好压力测试才能更好的防范于未然,降低触发熔断的次数。
如果清楚的知道每个系统有几斤几两,在这个基础上再把「限流」和「降级」做好,这基本就将“高压”下触发熔断的概率降到最低了。