近期深度强化学习取得了很多成功,但也存在局限性:缺乏稳定性、可复现性差。来自 MIT 和 Two Sigma 的研究者重新检验了深度强化学习方法的概念基础,即目前深度强化学习的实践多大程度上反映了其概念基础框架的原则?该研究重点探讨深度策略梯度方法。
深度强化学习是现代机器学习最为人所知的成就,它造就了 AlphaGO 这样广为人知的应用。对很多人来说,该框架展示了机器学习对现实世界的影响力。但是,不像当前的深度(监督)学习框架,深度强化学习工具包尚未支持足够的工程稳定性。的确,近期的研究发现当前***的深度强化学习算法对超参数选择过于敏感,缺乏稳定性,且可复现性差。
这表明或许需要重新检验深度强化学习方法的概念基础,准确来说,该研究要解决的重要问题是:目前深度强化学习的实践多大程度上反映了其概念基础框架的原则?
该论文重点研究深度策略梯度方法,这是一种广泛使用的深度强化学习算法。研究目标是探索这些方法的当前***实现多大程度上体现了通用策略梯度框架的关键基元。
该论文首先检验重要的深度策略梯度方法近端策略优化(PPO)。研究发现 PPO 的性能严重依赖于非核心算法的优化,这表明 PPO 的实际成功可能无法用其理论框架来解释。
这一观察促使研究者进一步检查策略梯度算法及其与底层框架之间的关系。研究者对这些算法在实践中展示的关键强化学习基元进行了细致地检查。具体而言,研究了:
- 梯度估计(Gradient Estimation):研究发现,即使智能体的奖励有所提升,用于更新参数的梯度估计通常与真实梯度不相关。
- 价值预测(Value Prediction):实验表明价值网络能够训练并成功解决监督学习任务,但无法拟合真正的价值函数。此外,将价值网络作为基线函数仅能稍微降低梯度估计的方差(但能够显著提升智能体的性能)。
- ***化 Landscape:研究发现***化 Landscape 通常无法反映其真正奖励的潜在 Landscape,后者在相关的采样方案(sample regime)中通常表现不佳。
- 置信域:研究发现深度策略梯度算法有时会与置信域产生理论冲突。实际上,在近端策略优化中,这些冲突来源于算法设计的基础问题。
研究者认为以上问题以及我们对相关理论知识的缺乏是深度强化学习脆弱性和低复现性的主要原因。这表明构建可信赖的深度强化学习算法要求抛弃之前以基准为中心的评估方法,以便多角度地理解这些算法的非直观行为。
论文:Are Deep Policy Gradient Algorithms Truly Policy Gradient Algorithms?

论文链接:https://arxiv.org/pdf/1811.02553.pdf
摘要:本文研究了深度策略梯度算法对促进其发展的底层概念框架的反映程度。我们基于该框架的关键要素对当前***方法进行了精细分析,这些方法包括梯度估计、价值预测、***化 landscape 和置信域分析。我们发现,从这个角度来看,深度策略梯度算法的行为通常偏离其概念框架的预测。我们的分析开启了巩固深度策略梯度算法基础的***步,尤其是,我们可能需要抛弃目前以基准为中心的评估方法。
检查深度策略梯度算法的基元
1. 梯度估计的质量
策略梯度方法的核心前提是恰当目标函数上的随机梯度上升带来优秀的策略。具体来说,这些算法使用(代理)奖励函数的梯度作为基元:

这些方法的理论背后的底层假设是,我们能够获取对梯度的合理估计,即我们能够使用有限样本(通常大约 103 个)的经验平均值准确估计上面的期望项。因此研究者对实践中该假设的有效性很感兴趣。
我们计算出的梯度估计准确度如何?为了解决该问题,研究者使用了评估估计质量最自然的度量标准:经验方差(empirical variance)和梯度估计向「真正」梯度的收敛情况。

图 2
图 2:梯度估计的经验方差在 MuJoCo Humanoid 任务中可作为状态-动作对关于数量的函数,x 轴为状态-动作对,y 轴是梯度估计的经验方差。
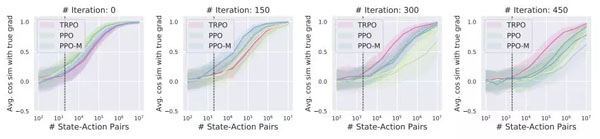
图 3
图 3:MuJoCo Humanoid 任务中梯度估计向「真正」期望梯度的收敛情况。
2. 价值预测

图 4
图 4:对于训练用于解决 MuJoCo Walker2d-v2 任务的智能体,在留出状态-动作对上的价值预测质量(度量指标为平均相对误差 MRE)。
3. 探索***化 landscape
策略梯度算法的另一个基础假设是对策略参数使用一阶更新可以带来性能更好的策略。因此接下来我们就来看该假设的有效性。
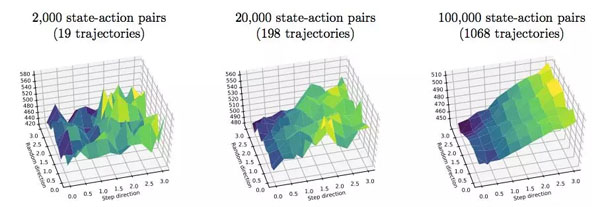
图 6:在 Humanoid-v2 MuJoCo 任务上,TRPO 的真正奖励函数 Landscape。
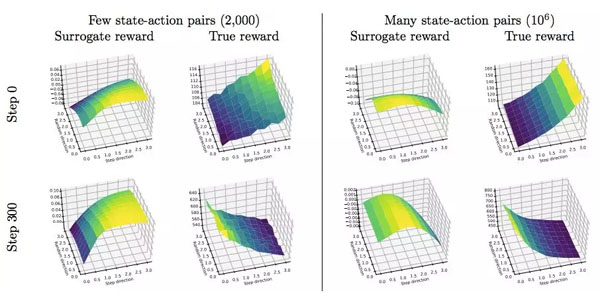
图 8:在 Humanoid-v2 MuJoCo 任务上,PPO 的真正和代理奖励函数 Landscape。
4. 置信域的优化

图 9
图 9:对于训练用于解决 MuJoCo Humanoid 任务的智能体,每一步的平均奖励、***速率(maximum ratio)、平均 KL 和 maximum versus mean KL 情况。
为深度强化学习奠定更好的基础
深度强化学习算法根植于基础稳固的经典强化学习框架,在实践中展示了巨大的潜力。但是,该研究调查显示,该底层框架无法解释深度强化学习算法的很多行为。这种分裂妨碍我们深入理解这些算法成功(或失败)的原因,而且成为解决深度强化学习所面临重要挑战的极大障碍,比如广泛的脆弱性和薄弱的可复现性。
为了解决这种分类,我们需要开发更加贴近底层理论的方法,或者构建能够捕捉现有策略梯度算法成功原因的理论。不管哪种情况,***步都要准确指出理论和实践的分岔点。这部分将分析和巩固前一章的发现和结果。
- 梯度估计。上一章的分析表明策略梯度算法使用的梯度估计的质量很差。即使智能体还在提升,此类梯度估计通常与真正的梯度几乎不相关(见图 3),彼此之间也不相关(见图 2)。这表明遵循现有理论需要算法获取更好的梯度估计。或者,我们需要扩展理论,以解释现代策略梯度算法为什么在如此差的梯度估计情况下还能取得成功。
- 价值预测。研究结果说明两个关键问题。一,尽管价值网络成功解决了接受过训练的监督学习任务,但它无法准确建模「真正」的价值函数。二,将该价值网络作为基线会降低梯度方差。但与「真」价值函数提供的方差减少程度对比来说则太少了。这些现象促使我们发问:建模真价值函数的失败是在所难免的吗?价值网络在策略梯度方法中的真正作用是什么?
- ***化 Landscape。由上一章可知,现代策略梯度算法的***化 Landscape 通常无法反映底层真正奖励的 Landscape。事实上,在策略梯度方法使用的采样方案中,真奖励的 Landscape 有噪声,且代理奖励函数通常具备误导性。因此我们需要深入理解为什么这些方有这么问题还能成功,更宽泛一点来看,如何更准确地展现真奖励函数的 Landscape。
- 置信域近似。该研究的发现表明策略需要局部类似可能存在大量原因,包括带噪声的梯度估计、较差的基线函数和代理 Landscape 未对齐。底层理论的置信域优化不仅未察觉到这些因素,将该理论转换成高效算法也非常困难。因此深度策略梯度方法放松对置信域的约束,这使得其性能难以理解和分析。因此,我们需要一种更加严格地执行置信域的技术,或者对于置信域放松的更严谨理论。
【本文是51CTO专栏机构“机器之心”的原创译文,微信公众号“机器之心( id: almosthuman2014)”】