第十个双11已圆满结束,但是技术的探索永不止步。阿里技术推出《十年牧码记》系列,邀请参与历年双11大战的核心技术大牛,一起回顾阿里技术的变迁。
近十年,机器智能在越来越多的领域走进和改变着我们的生活。在互联网领域,机器智能则是得到了更普遍和广泛的应用。作为电商平台的基石,商品搜索团队一直在打造适合电商平台的机器智能体系。而每年双11,则是验证智能化进程的试金石。今天,阿里资深算法专家元涵带你穿越时空,感受双11场景下搜索智能化的十年演进道路。
阿里搜索技术体系演进至今天,基本形成了由offline、nearline、online三层体系,分工协作,保证电商平台上,既能适应日常平稳流量下稳定有效的个性化搜索及推荐,也能够去满足电商平台对促销活动的技术支持,实现在短时高并发流量下的平台收益***化。
可以看到,十年双11的考验后,搜索智能化体系逐渐打造成型,已经成为电商平台稳定健康发展的核动力,主要分为四个阶段:自主研发的流式计算引擎Pora初露锋芒;双链路实时体系大放异彩;“深度学习+强化学习”初步探路;全面进入深度学习时代。下面我们就来一起看一下。
四大演进阶段:业务、算法、系统同步发展
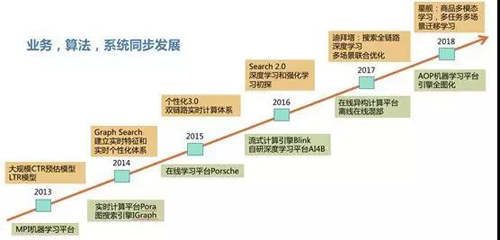
阶段一:初露锋芒——自主研发的流式计算引擎Pora
技术的演进是伴随解决实际业务问题和痛点发展和进化的。2014年双11,通过BI团队针对往年双11的数据分析,发现即将售罄的商品仍然获得了大量流量,剩余库存无法支撑短时间内的大用户量。主售款(热销sku)卖完的商品获得了流量,用户无法买到商品热销的sku,转化率低;与之相对,一些在双11当天才突然展露出来的热销商品却因为历史成交一般没有得到足够的流量。
针对以上问题,通过搜索技术团队自主研发的流式计算引擎Pora,收集预热期和双11当天全网用户的所有点击、加购、成交行为日志,按商品维度累计相关行为数量,并实时关联查询商品库存信息,提供给算法插件进行实时售罄率和实时转化率的计算分析,并将计算结果实时更新同步给搜索和推荐引擎,影响排序结果。***次在双11大促场景下实现了大规模的实时计算。算法效果上,也***次让大家感受到了实时计算的威力,PC端和移动端金额也得到显著提升。
阶段二:大放异彩——双链路实时体系
2014年双11,实时技术在大促场景上,实现了商品和用户的特征实时,表现不俗。
2015年搜索技术和算法团队继续推动在线计算的技术升级,基本确立了构筑基于实时计算体系的【在线学习+决策】搜索智能化的演进路线。
早先的搜索学习能力,是基于批处理的离线机器学习。在每次迭代计算过程中,需要把全部的训练数据加载到内存中计算。虽然有分布式大规模的机器学习平台,在某种程度上批处理方法对训练样本的数量还是有限制的。在线学习不需要缓存所有数据,以流式的处理方式可以处理任意数量的样本,做到数据的实时消费。
接下来,我们要明确两个问题:为什么需要在线学习呢?以及为什么实现秒级的模型更新?
在批量学习中,一般会假设样本独立服从一个未知的分布,但如果分布变化,模型效果会明显降低。而在实际业务中,很多情况下,一个模型生效后,样本的分布会发生大幅变化,因此学到的模型并不能很好地匹配线上数据。实时模型,能通过不断地拟合最近的线上数据,解决这一问题,因此效果会较离线模型有较大提升。那么为什么实现秒级分钟级的模型更新?在双11这种成交爆发力强、变化剧烈的场景,秒级实时模型相比小时级实时模型时效性的优势会更加明显。根据2015年双11实时成交额情况,前面1小时已经完成了大概总成交的1/3,小时模型就无法很好地捕获这段时间里面的变化。
基于此,搜索技术团队基于Pora开发了基于parameter server的在线学习框架,如下图所示,实现了在线训练,开发了基于pointwise的实时转化率预估模型,以及基于pairwise的在线矩阵分解模型。并通过swift输送模型到引擎,结合实时特征,实现了特征和模型双实时的预测能力。
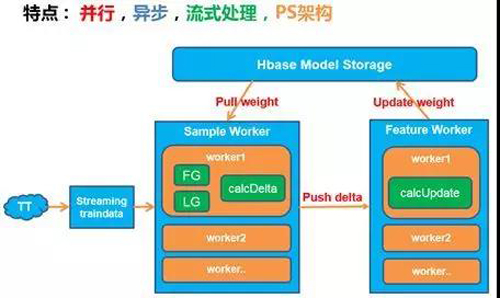
在线学习框架
但是,无论是离线训练还是在线学习,核心能力是尽可能提高针对单一问题的算法方案的准确度,却忽视了人机交互的时间性和系统性,从而很难对变幻莫测的用户行为以及瞬息万变的外部环境进行完整的建模。典型问题是在个性化搜索系统中容易出现反复给消费者展现已经看过的商品。
如何避免系统过度个性化,通过高效的探索来增加结果的丰富性?我们开始探索机器智能技术的另一方向——强化学习,运用强化学习技术来实现决策引擎。我们可以把系统和用户的交互过程当成是在时间维度上的【state,action,reward】序列,决策引擎的目标就是***化这个过程。
在线决策方面,我们***尝试了运用MAB和zero-order优化技术实现多个排序因子的***融合策略,取代以前依靠离线Learningto rank学到的排序融合参数。其结果是显著的,在双11当天我们也观察到,通过实时策略寻优,一天中不同时间段的***策略是不同的,这相比全天使用离线学习得到的一套固定排序权重是一个大的进步。
2015年双11双链路实时计算体系如下图所示:
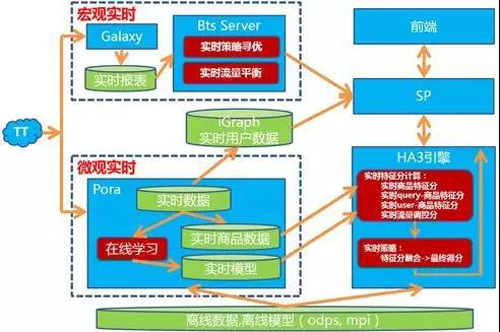
2015年双11的实时计算体系
阶段三:初步探路——“深度学习+强化学习”
2015年双11,在线学习被证明效果显著,然而回顾当天观察到的实时效果,也暴露出一些问题。
- 问题一:在线学习模型方面,该模型过度依赖从0点开始的累积统计信号,导致后场大部分热销商品都无法在累积统计信号得到有效的差异化表示,模型缺少针对数据的自适应能力。
- 问题二:在线决策方面。2015年双11,宏观实时体系中的MAB( Multi-ArmedBandit)实时策略寻优发挥了重要作用,通过算法工程师丰富经验制定的离散排序策略集合,MAB能在双11当天实时选择出***策略进行投放;然而,同时暴露出MAB基于离散策略空间寻优的一些问题,离散策略空间仍然是拍脑袋的智慧。同时为了保证MAB策略寻优的统计稳定性,几十分钟的迭代周期仍然无法匹配双11当天流量变化的脉搏。
针对***个问题,我们在2016年双11中也进行了优化和改进。对于从0点的累积统计信号到后场饱和以及统计值离散化缺少合理的抓手的问题,我们参考Facebook在AD-KDD的工作,在此基础上,结合在线学习,我们研发了Streaming FTRL stacking on DeltaGBDT模型,如下图所示。
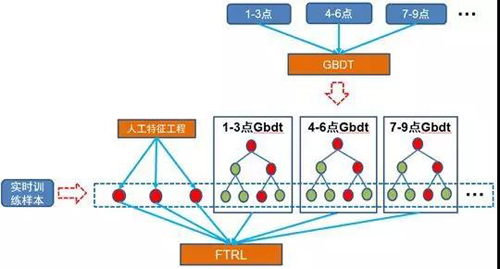
Streaming FTRL stacking on DeltaGBDT模型
分时段GBDT模型会持续为实时样本产出其在双11当天不同时段的有效特征,并由onlineFTRL去学习这些时效性特征的相关性。
对于在线决策方面的问题,我们进行了策略空间的***化探索,分别尝试了引入delay reward的强化学习技术,即在搜索中采用强化学习(ReinforcementLearning)方法对商品排序进行实时调控优化。我们把搜索引擎看作智能体(Agent)、把用户看做环境(Environment),则商品的搜索问题可以被视为典型的顺序决策问题(Sequential Decision-making Problem)。我们的目标就是要实现用平台长期累积收益的***化。
系统方面,2016年双11我们的实时计算引擎从istream时代平稳升级到到 Blink/Flink 时代,实现24小时不间断无延迟运转,机器学习任务从几个扩大到上百个job。为算法实现大规模在线深度学习和强化学习等前沿技术打下了坚实的基础。
阶段四:全面进入——深度学习时代
由于在线深度学习需要强大的计算资源来支持,2017年系统上我们重构了流式计算平台、机器学习平台和支持CPU/GPU的异构在线服务平台,能够支持更大规模的流式数据计算,超大规模深度模型在线学习和在线预估。
依托强大的计算能力,实现了深度学习在搜索的全面落地,包括语义搜索,深度用户兴趣感知,商品多模表示学习,在线深度机制模型,多场景协同智能决等技术创新:
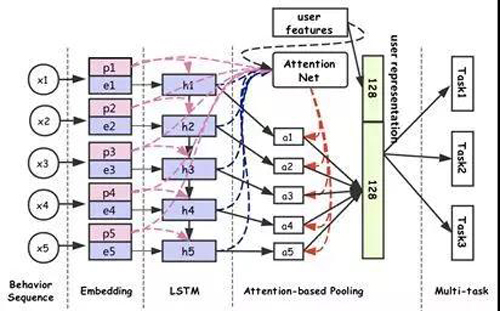
a) 深度用户感知模型:搜索或推荐中个性化的重点是用户的理解与表达,基于淘宝的用户画像静态特征和用户行为动态特征,我们提出基于multi-modals learning、multi-task representation learning以及LSTM的相关技术,从海量用户行为日志中直接学习用户的通用表达,该学习方法善于“总结经验”、“触类旁通”,使得到的用户表达更基础且更全面,能够直接用于用户行为识别、偏好预估、个性化召回、个性化排序等任务,在搜索、推荐和广告等个性化业务中有广泛的应用场景。(相关成果的论文已被KDD 2018 录用)
b)大规模商品多模表示学习:淘宝商品有文本、图像、标签、id 、品牌、类目、店铺,统计特征等多模态信息,这些特征彼此有一定程度的冗余和互补,我们利用多模学习将多维度特征融合在一起学习一个统一的商品向量,并通过attention机制实现不同特征维度在不同场景下的差异,比如女装下图片特征比较重要,3C下价格,销量比较重要等。
c)在线深度机制模型:由于不同用户和不同场景的优化目标不一样,我们把用户状态,场景相关特征加入到了机制模型中,实现了千人千面的排序机制模型。同时由于各种基础实时日志的qps和延迟都不太一样,为了保证在线学习的稳定性,我们构建了实时样本pool来维护一个稳定的样本集合供在线学习使用。
d) 全局排序:传统的排序模型只对单个文档打分,然后按照分数从高到底排序。这样方法无法考虑到商品之间相互的影响;传统的针对单个商品ctr、cvr都基于这样一个假设:商品的ctr、cvr不会受到同时展示出来的其他商品(我们称为展示context)的影响。而实际上一个商品的展示context可以影响到用户的点击或者购买决策:假如同一个商品周边的商品都和它比较类似,而且价格都比它便宜,那么用户买它的概率不会高;反之如果周边差不多的商品都比它贵,那么用户买它的概率就会大增。而全局排序就要解决这个问题,考虑商品之间的相互影响,实现整页效率的***化。(相关成果的论文已被IJCAI2018 录用)
e) 多场景协同智能决策:搜索多个不同的产品都是依托个性化来实现GMV***化,导致的问题是不同产品的搜索结果趋同。而导致这个问题的根本原因是不同场景的算法各自为战,缺乏合作和关联。今年做的一个重要工作是利用多智能体协同学习技术,实现了搜索多个异构场景间的环境感知、场景通信、单独决策和联合学习,实现联合收益***化,而不是此消彼长(相关成果的论文已被 www 2018录用)。
驱动搜索智能化体系的演进的三点
我们再回过头来看,是什么驱动了搜索智能化体系的演进?
目前,各大互联网公司的主流技术路线主要是运用机器学习技术来提升搜索/推荐平台的流量投放效率,随着计算力和数据的规模增长,大家都在持续地优化和深入。是什么驱动我们推动搜索的智能化体系从离线建模、在线预测向在线学习和实时决策方向演进呢?概括来说,主要有以下三点。
首先,众所周知,淘宝搜索具有很强的动态性,宝贝的循环搁置,新卖家加入,卖家新商品的推出,价格的调整,标题的更新,旧商品的下架,换季商品的促销,宝贝图片的更新,销量的变化,卖家等级的提升等等,都需要搜索引擎在***时间捕捉到这些变化,并在最终的排序环节,把这些变化及时地融入匹配和排序,带来结果的动态调整。
其次,从2013年起,淘宝搜索就进入千人千面的个性化时代,搜索框背后的查询逻辑,已经从基于原始Query演变为【Query+用户上下文+地域+时间】,搜索不仅仅是一个简单根据输入而返回内容的不聪明的“机器”,而是一个能够自动理解、甚至提前猜测用户意图(比如用户浏览了一些女士牛仔裤商品,然后进入搜索输入查询词“衬衫”,系统分析用户当前的意图是找女性相关的商品,所以会展现更多的女士衬衫,而不是男生衬衫),并能将这种意图准确地体现在返回结果中的聪明系统,这个系统在面对不同的用户输入相同的查询词时,能够根据用户的差异,展现用户最希望看到的结果。变化是时刻发生的,商品在变化,用户个体在变化,群体、环境在变化。在搜索的个性化体系中合理地捕捉变化,正是实时个性化要去解决的课题。
***,电商平台也完成了从PC时代到移动时代的转变,随着移动时代的到来,人机交互的便捷、碎片化使用的普遍性、业务切换的串行化,要求我们的系统能够对变化莫测的用户行为以及瞬息万变的外部环境进行完整的建模。基于监督学习时代的搜索和推荐,缺少有效的探索能力,系统倾向于给消费者推送曾经发生过行为的商品或店铺。
真正的智能化搜索和推荐,需要作为投放引擎的agent有决策能力,这个决策不是基于单一节点的直接收益来确定,而是当作一个人机交互的过程,消费者与平台的互动看成是一个马尔可夫决策过程,运用强化学习框架,建立一个消费者与系统互动的回路系统,而系统的决策是建立在***化过程收益基础上。
未来展望——让淘宝搜索拥有智慧化的体验
经过这么十年双11大促的技术锤炼后,围绕在线AI技术的智能框架初具规模,基本形成了在线学习加智能决策的智能搜索系统,为电商平台实现消费者、卖家、平台三方利益***化奠定了坚实的基础。这套具备学习加决策能力的智能系统也让搜索从一个简单的找商品的机器,慢慢变成一个会学习会成长,懂用户,体贴用户的“人”。
但在这个过程中,搜索排序学习到的知识更多都是通过已有的商品标签数据和用户行为数据来获取的,还缺少对商品和用户更深层次的认知,还无法完全理解用户的多元意图表达的真实需求。
比如,用户搜索了“性感连衣裙”,可能是想找“去参加晚场party的低胸晚装裙”,也可能是想找“去海边度假的露肩沙滩裙”;用户收藏了“登山鞋”和“拐杖”,可能有“登山装备”的需求,需要发现更多的和登山装备相关的其它品类商品。一个有孩子的爸爸,在暑假刚开始时,挑选“转换接头”,查看“大英博物馆门票”,可能是想带着家人一起“暑期英国亲子游”,需要发现更多相关的其它品类商品。
究其原因,目前机器智能技术特别是以深度学习为代表的模型,在现实应用中快速发展,最主要受益于海量大数据以及大规模计算能力,通过对物理世界的数字化抽象和程式化学习,使得机器智能具备很强的限定知识的获取能力,而很难获得数据之外的知识,就更不用说知识的类比、迁移和推理了。
而机器的认知智能,比如自主学习和发现,甚至创造能力才是人工智能的更高境界。当然通用的机器智能还有很多工作要做,在这个过程中,怎么样首先结合人类知识和机器智能做到初步的认知智能,让淘宝搜索拥有智慧化的体验是未来值得探索的方向。
我们有理由相信,随着智能技术的进一步升级,这个“人”会越来越聪明,实现机器智能,认知智能的***目标。
【本文为51CTO专栏作者“阿里巴巴官方技术”原创稿件,转载请联系原作者】