












大数据文摘出品
编译:李雷、韦梦夙、胡笳
如果说现代工作面试教会了我们什么,那就是“你***的弱点是什么?”的正确回答是“我工作太努力了。”
显然,真的要去谈论我们的弱点是很荒唐可笑的,我们为什么要提我们做不到的事情?虽然工作申请和LinkedIn不鼓励我们披露我们的弱点,但如果我们从不承认我们的缺点,那么我们就无法采取措施来解决它们。
要想在奋斗中变得更好其实很简单:
- 确定你目前的问题:找出缺点
- 弄清楚你要的目标:制定实现的计划
- 执行计划:每次一小步
但我们很少执行***步:特别是在技术领域,我们总是用已知的技能埋头苦干,而不是学习那些可以使工作更轻松或者获得新机会的新技能。自我反思 - 客观地评估自己 - 看起来好像是一个不相干的概念,但是如果能退一步,弄清楚我们怎样能把事情做得更好或更有效,这对于在任何领域取得进步都至关重要。
考虑到这一点,我试图客观地审视自己,并确定3个努力方向以使我成为更好的数据科学家:
- 软件工程
- 扩展数据科学
- 深度学习
我写这篇文章的目的有三。
- 首先,我真的想变得更好,所以我需要承认我的弱点。我的目的是通过概括我的不足以及如何改正它们,让自己有动力完成我的学习目标。
- 其次,我希望鼓励其他人思考他们可能不了解的技能以及他们怎样获得这些技能。你不必像我这样写篇文章来公开哪些东西你不会,但是如果你可以找到一项新技能来学习,那么花点时间考虑这个问题是值得的。
- ***,我想告诉你,要成为一名成功的数据科学家并不需要什么都知道。数据科学/机器学习的课题几乎是无穷无尽的,但实际上你能了解的有限。不管那些华而不实的求职简历是怎么写的,你不需要完全了解每个算法(或有5到10年的工作经验)才能成为一名职业数据科学家。我经常从初学者那里听到他们被自己所认为必学的课题数量压得不堪重负,而我的建议总是一样的:从基础开始,并且明白你不需要知道所有的一切!
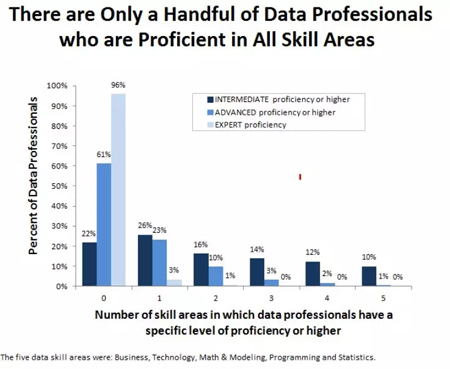
对于每个弱点,我已经做了概述以及我目前正在做的改进。确定一个人的弱项很重要,但制定如改进的计划也很重要。学习一项新技能需要时间,但计划一系列小而具体的步骤会大大增加你成功的机会。
软件工程
我最初的数据科学实践经验是在学术环境中获得的,之后我一直试图避免重拾某些以学术方式来研究数据科学的坏习惯。其中包括编写仅运行一次的代码,缺乏文档,编写没有统一风格且难以阅读的代码以及硬编码某些特定值。所有这些做法都反映了一个基本目标:开发一个数据科学解决方案,该解决方案只针对特定数据集做一次性工作,以便撰写论文。
其中一个典型的例子是我们的一个项目使用建筑能源数据,最初每隔15分钟采集一次,但当我们以5分钟为增量开始采集数据时,发现程序完全崩溃了,因为有数百个地方把采集间隔写死为15分钟。我们不能简单地查找和替换,因为这个间隔参数被写成很多种名字,如electricity_interval,timeBetweenMeasurements或dataFreq。没有一个研究人员考虑过代码的可读性或输入变量的灵活性。
相比之下,从软件工程的角度来看,代码必须使用大量不同的输入进行广泛测试,有良好的文档,在现有框架内工作,并遵守编码标准,以便其他开发人员能够理解。尽管我非常想这样做,但我偶尔也会像数据科学家而不是像软件工程师那样编写代码。我开始思考伟大的与普通的数据科学家之间的区别是在于使用软件工程***惯例编写代码 - 如果你的模型不够健壮或不适合整个架构,则不会被部署 - 现在我正在尝试培养自己像计算机科学家一样思考。
通常,对于技术技能的学习来说没有比实践更好的方法。幸运的是,在我目前的工作中,我能够同时为我们的内部工具和开源库做出贡献。这也迫使我获得了许多实践机会,包括:
- 编写单元测试
- 遵循编码风格指南
- 编写可以更改参数的函数
- 完整的代码文档
- 让其他人做代码审查
- 重构代码使其更简洁,更易于阅读
即使对于尚未有实际工作经验的数据科学家,你也可以通过协作参与开源项目获得这样的经验。另一个获取可靠编码实践的好方法是在GitHub上阅读流行库的源代码(Scikit-Learn是我的***之一)。获得其他人的反馈也至关重要,因此你可以找一个社区并向那些比你更有经验的人寻求建议。
像软件工程师一样思考需要改变你的思维模式,但如果你能够慢下来并牢记这些做法,那么实践他们并不困难。例如,每当我发现自己在Jupyter Notebook 中复制和粘贴代码并更改一些值时,我会试着停下来并意识到我不如使用函数来代替拷贝粘贴的代码,因为从长远来看这会让我更有效率。虽然我对这些惯例的实践还不算***,但我发现它们不仅让其他人更容易阅读我的代码,而且还更容易扩展我的工作。比起写代码,我们更多时候是在阅读代码,因此你未来会感激这些文档和统一的编程风格。
除了编写那些大型代码库的代码中用到这些,我仍然会坚持遵循部分惯例。编写数据分析的单元测试对于数据科学家来说可能看起来很奇怪,但是当您真正需要开发测试以确保代码按预期工作时,这是很好的做法。此外,还有许多工具可以检查您的代码是否遵循编码风格(我仍然在努力解决关键字参数周围的无空格的问题)。
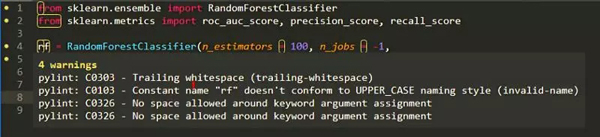
总有地方可以改进(在Sublime Text 3里使用pylint)
我还想研究计算机科学的许多其他方面,例如编写有效的实现代码而不是暴力法(例如使用矢量化而不是循环)。然而,同样重要的是要明白你不能一次改变所有东西,这就是为什么我专注于其中一些惯例并将它们变成我工作流程中的习惯。
虽然数据科学自成一体,但从业者仍可以通过借鉴软件工程等现有领域的***实践惯例而受益。
扩展数据科学
虽然你可以自学数据科学中的所有内容,但付诸实践部分有一些限制。其中一个是难以将分析或预测模型扩展到大型数据集。我们大多数人无法访问计算集群,又不想存钱购买个人超级计算机。这意味着当我们学习新算法时,我们倾向于将它们应用于小型,表现良好的数据集。
不幸的是,现实世界里的数据集不会对数据量大小或者数据干净程度有严格限制,所以,你必须使用不同的方法去解决数据量过大、脏数据等问题。首先,你或许需要突破个人电脑的安全限制,使用一个远程的实例,例如亚马逊的AWS EC2 甚至是多台机器。这意味着,你必须学习怎样远程连接机器和敲写命令行,因为你的EC2实例不能使用鼠标也没有操作界面。
当学习数据科学相关课程的时候,我使用亚马逊云的免费服务或者免费积分(如果你有多个邮箱可以注册多个账户来获得更多免费服务)在EC2机器做练习。这样能帮助我熟悉敲写命令行。然而,我还没有解决第二个问题——数据集大小能够超过机器的内存。我意识到这个限制让我回到了原点,现在是学习处理更大的数据集的时候了。
你甚至不用在电脑资源上花费数以千计美金,就可以实践这些超出内存限制的数据集的处理方法。这些方法包括每次遍历一个大数据集的一部分、把一个大数据集拆分成许多小数据集或者使用像Dask这种能够让你掌握大数据集处理细节的工具
我目前的方法是,对于内部项目数据集和外部开源数据集,都把单个数据集拆分成多个子集,开发一个能够处理子集数据的pipeline(程序、脚本等),然后用Dask 或者PSpark通过pipeline并行跑这些子集。这个方法不需要拥有超级电脑或者集群——你可以利用计算机的多核架构并行操作普通电脑。当你拥有更多资源的时候,你就可以自由的拓展程序规模。
幸亏有像Kaggle这样的数据宝藏,我已经找到了一些相当大的数据集,并且学习其他数据科学家处理它们的方法。我从中找到了很多有用的建议,例如,把数据类型改成dataframe以减小内存消耗。这些方法能帮助我更高效地处理各种数量级的数据集。
美国国会图书馆“只有”3PB的材料
虽然还没有处理过TB级的数据集,这些方法已经帮助我学到了处理大数据的基本策略。在最近的一些项目中,我已经能够运用所学技能在AWS的集群上做分析。希望接下来的几个月,我能逐步在更大的数据集上做分析。可以肯定的是在将来的分析中,数据集会越来越大,我还需要继续提高处理更大数据集的技能。
深度学习
虽然人工智能在繁荣和萧条中更迭,但是它最近在计算机视觉、自然语言处理、深度强化学习等领域的成功应用让我确信基于神经网络的深度学习不是昙花一现。
与软件工程和数据科学拓展领域不同,我现在的职位不需要任何深度学习知识:传统机器技术更能有效解决我们客户的问题。然而,我发现并不是每一个数据集都是行列结构化的,神经网络是文本或图像项目的***选择(目前来看)。我会继续利用已有技能解决当前的问题,但是,尤其在职业生涯早期,探索性课题同样拥有巨大的潜在价值。
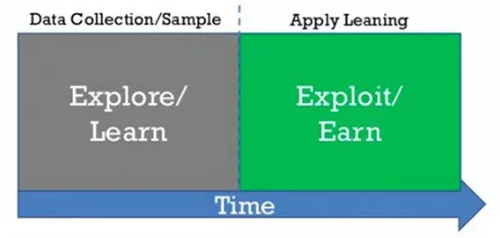
探索和利用的权衡在强化学习和你的生活中的应用
深度学习里有很多不同的分支领域,非常难分辨哪个方法和库将***胜出。虽然如此,我认为熟悉深度学习某一个领域并能实现其中某些技术,会让一个人能够解决问题的范围更广。解决问题驱使我更深入学习数据科学,所以把深度学习加入我的技能库是一项有价值的投资。
我对于深度学习的学习计划和当初把自己变成数据科学家的方法一样:
- 阅读着重部署应用的书籍和教程
- 在真实项目中练习技术和方法
- 通过写作分享和解释我的项目
当我学习一个技术课题时,一个有效的方法是边学边做。这意味起步时不是通过基础理论而是通过找到实际应用方法去解决问题。这个自上而下的方法意味着我要把许多精力放在着重于动手带有许多代码样例的工具书上。在我明白技术的实际应用以后,我再回到基础理论中,这样,我能够更高效的使用这些技术。
虽然没有机会在工作中学习到其他人的神经网络,要靠自己自学,但是在数据科学领域有着丰富的资源和广阔的社区。对于深度学习,我最初依赖这三部书:
- 《Deep Learning Cookbook》,作者Douwe Osinga
- 《Deep Learning with Python》,作者Francois Chollet
- 《Deep Learning》,作者Ian Goodfellow, Yoshua Bengio, and Aaron Courville
前两本书着重于通过神经网络实现解决方案,而第三本更偏向深入理论。只要情况允许,可以边读边在键盘上敲代码,这会将读技术文章变为有趣的体验。前两本书中的代码示例非常棒:我通常是在Jupiter Notebook中逐行敲写和运行,探究代码如何工作,并记录知识细节。
此外,我不仅仅是复制这些代码,而是尝试在自己的项目中实践它们。我在近期工作的一个实践项目是构建一个图书推荐系统,该系统是根据《Deep Learning Cookbook》中的类似示例代码改编的。从头开始创建自己的项目可能令人生畏,如果你想提升自己,可以从别人的轮子上搭起。
***,学习某个主题的最有效方法之一是把这个知识教给别人。从经验来看,如果我不能用简单的语句解释给别人,那么我就还没有完全理解这个知识。随着学习深度学习的每个主题,我将保持写作,并分析技术实现细节和概念性解释。
教学是***的学习方式之一,我计划将其作为学习深度学习的一项重要组成部分。
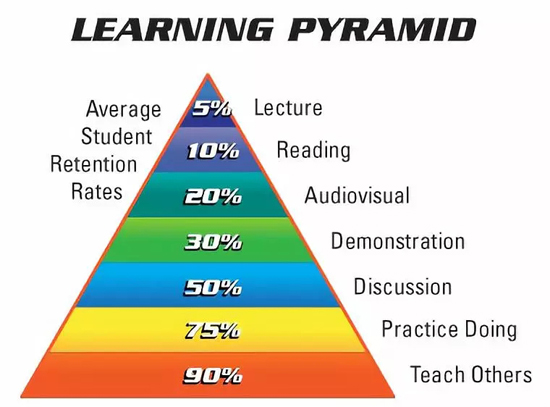
学习金字塔。左侧:平均掌握程度;右侧:讲义、阅读、音视频资料、示例、讨论、实践联系、教导其他人
总结
公开自己的弱点可能会感觉有点奇怪。写这篇文章的确会让我感觉不舒服,但是我写出来是因为它最终会帮助我成为一个更好的数据科学家。而且,我发现很多人,包括雇主们,会对你坦诚自己的弱点并探讨如何解决它们留下深刻印象。
不了解某些技能并不是弱点——真正的弱点是假装自己知道一切并停滞不前。
通过定位我在数据科学方面的弱点——软件工程,扩展分析/模型,深度学习——我的目标是高自己,鼓励他人思考自己的弱点,并向你展示想成为成功的数据科学家并不必要学习所有知识。虽然反思个人的弱点可能很痛苦,但是学习是快乐的:最有成就感的事情莫过于,经过一段时间的持续学习后回顾这个过程,你知道你已经比刚出发的时候懂得更多。
相关报道:
https://towardsdatascience.com/my-weaknesses-as-a-data-scientist-1310dab9f566
【本文是51CTO专栏机构大数据文摘的原创文章,微信公众号“大数据文摘( id: BigDataDigest)”】
















