【51CTO.com原创稿件】Push 作为一种有效的召回用户的产品,近几年来被各类 App 广泛应用。但是 Push 存在两面性,如果推荐的消息准确,则能够有效地召回用户,反之,就会对用户造成骚扰。
通过机器学习进行个性化 Push,给用户推送其感兴趣的内容,既能最大程度地降低对用户的骚扰,同时也能有效地提升 Push 的打开率。
2018 年 5 月 18-19 日,由 51CTO 主办的全球软件与运维技术峰会在北京召开。
在“人工智能技术探索”分会场,新浪微博的技术专家齐彦杰,给大家带来了《机器学习在微博个性化 Push 的应用》的主题演讲。
他和大家分享了微博个性化 Push 如何基于海量数据,通过机器学习有效提升打开效果的一些做法和思路。
本文按照如下四个部分展开:
- 为什么要做 Push 业务
- 微博个性化 Push 的场景
- 微博个性化 Push 的机制
- 微博基于机器学习的个性化 Push 应用
为什么要做 Push 业务
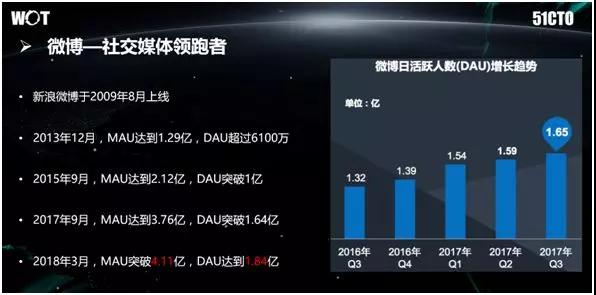
众所周知,微博是社交媒体中的领跑者,它于 2009 年 8 月份上线;2013 年底,MAU(月活用户数)突破了一亿;2015 年 9 月,DAU(日活用户数)突破了一亿。
2017 年 9 月,MAU 达到 3.76 亿;2018 年 3 月,微博的MAU突破了 4.11 亿。该增长速度是相当惊人的。
当微博的 MAU 超过 4.1 亿之后,这么庞大的用户体量以及用户关系,本身必定会更大发挥其社交媒体的属性。
下面我们来看为何要去做 Push 业务。如上图右边所示,这些都是大家印象非常深刻的事件。
如果我们能够在第一时间把这些事件推送给目标用户,一定会满足用户对重大消息及时性的需求。
所以,每当国内、外有重大事件发生的时候,我们都会做一些提醒发给大家。
同时我们又是一个社交媒体,当用户所关注的博主发出博文的时候,他们都希望能够以内容提醒的方式,收到自己感兴趣的通知类消息。
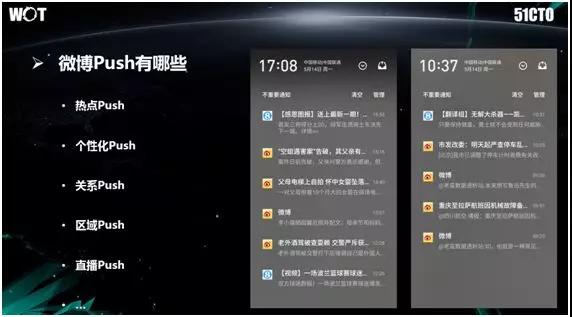
根据上述需求,我们将微博上的 Push 大概分为:热点 Push、个性化 Push、关系 Push、区域 Push 和直播 Push 等类型。
上图右侧是微博 Push 的展现形态,它们包括一些文案和简介,且都是在通知栏里展现出来的。

可见,Push 本身具有站方主动推送的特征,而用户则处于一种被动提醒的状态。
然而它的挑战性是:用户在信息流中通过一次性刷新,就能带来十多条的信息曝光,命中用户兴趣点的概率较大,而 Push 是单条曝光,命中的概率小了很多。
但是,如果 Push 的发送过于频繁,则会引起用户的反感。因此,我们希望在尽量少发的前提下,尽快找到用户的兴趣点。
它具有一定的复杂性和挑战性。即在降低对用户骚扰的同时,提升用户的点击规模。
所以,我认为 Push 的本质就是一个高效的内容分发系统,它能够在较短的时间内为各种内容找到其目标群体,并且发送给相应的消费者。
同时,对于个人用户来说,它应该是一个拥有足够丰富经验的私人秘书,帮助用户在海量的内容源中,找到喜欢的消息,并及时的提醒用户进行查阅。
微博个性化 Push 场景
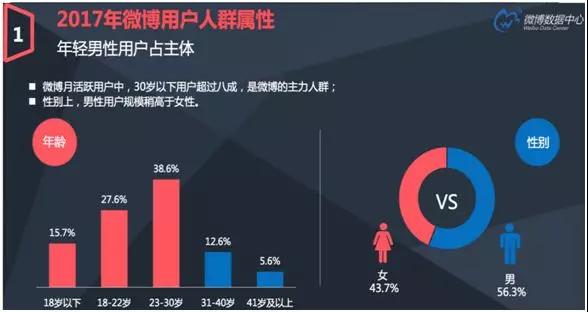
下面我们来看看个性化 Push 的场景。上图是 2017 年对于微博用户的分析,用户从 18 岁以下到 41 岁以上有着广泛的年龄层次分布。
相对于微博这种体量的平台,就算 41 岁以上的人群仅占 5.6%,其绝对数量也有几千万的群体。
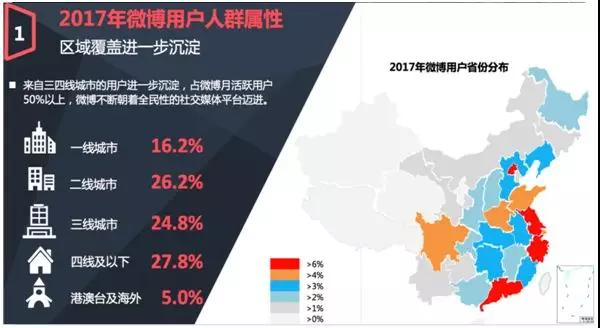
就地域而言,一、二、三、四线、及港澳台城市,都有大量用户的分布。

同时微博用户的兴趣点也是非常分散的。内容涉及明星、汽车、电影、美食等方面。
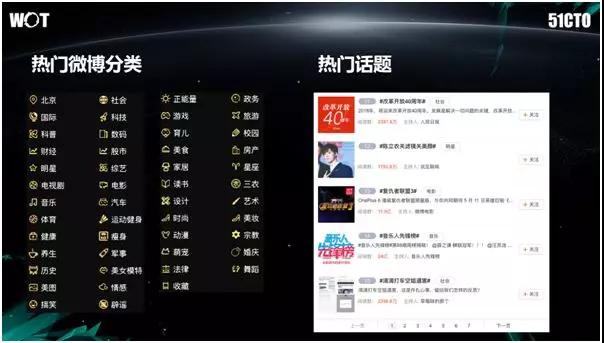
在如此庞大的用户群体和用户喜好分布的情况下,微博本身的内容品种也是非常丰富的。
如上图左侧所列的、微博热门的首页分类,以及右侧是某一时刻的、热门话题的列表,可见它是多么的丰富和繁杂。
鉴于用户有如此广泛的兴趣,我们该如何在较短的时间内,为他们匹配并推送喜欢的内容呢?
这就是我们个性化 Push 所要解决的问题。我们需要构建一个推荐系统,有针对性地为不同的用户找到他们所喜欢的内容。
微博个性化 Push 机制

由于所有的推荐系统,基本上都是从内容源头上去寻找用户喜欢的资源。那么对于微博而言,其源头就是全量的原创博文。
每天,这些博文以几千万的量级产生,但并非所有的内容都适合被推荐给用户的,因此我们需要进行机器和人工的双重筛选。
机器筛选,能帮助我们找到优质的素材。但由于 Push 本身是一个推送的过程,当它所推送的内容包含一些不良内容时,就会给用户带来巨大的困扰,因此,为了规避风险,我们加入了人工审核的环节。
在人工审核完成之后,我们会得到适合推荐的集合,该集合再利用算法去匹配博文和用户,即如果两者之间匹配的分数高,我们就会通过分发控制将内容下发过去。
同时,我们通过对“已读、已发”进行过滤,以保证所发出去的内容不是用户已经看过的。
另外,大家使用微博的时间偏好会有所不同。如果我们在用户工作的时候给他发送博文消息,那么由于他在此时并不想消费内容,因此会构成一定的骚扰。
而到了中午,当有空再去查看时,该内容已经过时了。所以我们需要选择用户最想看微博的时间段,将内容发送过去。

有了前面推荐系统的流程概念,我们具体来看一下评分的过程。首先,我们通过物料生成模型进行审核,筛选出全量优质的内容,并放入物料池之中。而物料池需要实时地更新其互动的内容。
例如,物料池根据某条博文在当前时间点的转发次数与评论次数,予以实时更新。
在完成更新之后,我们会以分钟为间隔单位,去拉取所需的物料和参与计算的用户,使用 Rank 模型算出分值和排序,并从中筛选出对于用户最感兴趣的博文予以下发。
上图的 Rank 模型旁边是“协同推荐”。在一般系统中,会将协同作为一种召回的方式,将协同所产生的内容,放在物料召回的部分中再做推荐。
但是在该场景下,根据我们做过的测试,协同推荐的效果好于排序模型,因此我们认为没有必要再“走”一遍排序模型,完全可以直接发送下去了。
而在经历了基础过滤的下发后,我们会实时地收取下发日志和点击日志。这两种日志再通过更新物料池,影响物料生成模型和运营审核部分,从而为筛选环节提供帮助。
微博基于机器学习的个性化 Push 应用
理解了推荐系统的结构,我们再来看如何将机器学习在个性化 Push 中进行具体应用。
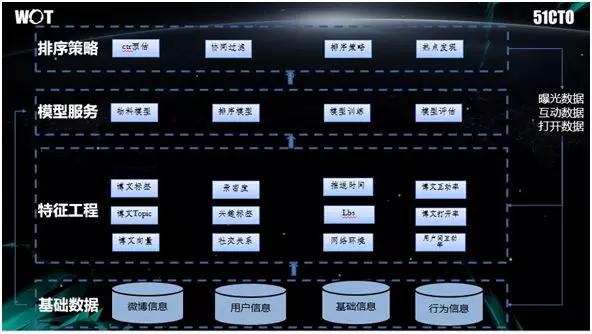
上图是我们整体的架构,其最下端是博文信息、用户信息、行为信息等。我们会根据这些信息挖掘出各种非常具象的特征。
利用这些特征进行模型训练和评估,就能得出排序模型和物料模型。当新模型达到需求,我们就会将这些模型运用到线上,进行排序策略、和 CTR 预估。
最后线上的数据被再次“传导”回来,成为下面的基础数据部分,以供模型下一次的训练与迭代。
特征构建
上面提到了特征的构建,那么我们如何来具象各种特征呢?
兴趣维度
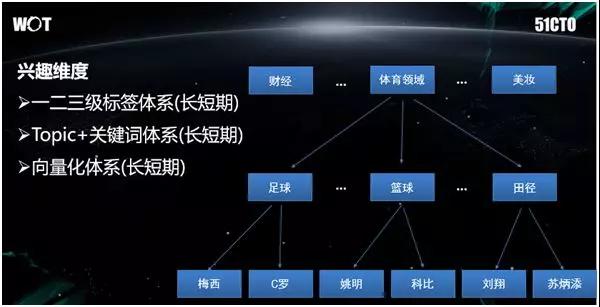
对于一篇博文而言,微博通过“三级标签体系”来具现它所代表的特征含义。通过记录用户对博文的消费来记录其兴趣方向。
如上图所示:首先,最上面的是比较宽泛的,如“体育领域”;其次是“足球”;“足球”下面会有“梅西”、“C 罗”。
在某个用户消费了带有“梅西”标签的博文后,只要他多次打开或互动,我们就认为该用户是对于“梅西”感兴趣的,就会把“梅西”标签记录在用户信息中。
我们把用户兴趣标签和博文标签作为特征加入到模型中,进行训练,就能表示用户对博文内容的兴趣程度。
关系维度

检查某个用户与其关注的博主是否有过直接的互动行为。如果他们在历史上的互动次数非常频繁的话,我们就认为该博主所会产生的博文特别契合此用户的需求,那么他们的关系也可以作为一个纬度特征,被加入进来。
实时维度

或称“先验”纬度。由于 Push 在其应用的场景中所使用的物料相对较少,其“曝光”的机会更少,因此所推送的内容必须是热点中的热点。
我们通常会将各种博文在其他领域里的消费点击率作为“先验”数据传导回来,通过导入至模型中,以给我们提供帮助。
环境维度
包括推送的时间、设备的网络信息、和设备本身的信息等。
模型升级

有了上述各种特征之后,我们再讨论一下 Push 业务的模型升级过程。首先,我们从 LR(Logistic Regression)开始做了一个 Base Line。
由于 LR 模型在实践中不但非常简单,同时解释性也不错,而且它特别适合于大规模的计算,因此我们将其作为 Base Line 之后,就有了一个基础性的数据。
在那之后,我们升级到了FM(Factorization Machines)模型,以及现在所做的 Wide&Deep 模型。
线性模型

上图是对 LR 模型的介绍。由于该模型比较难以捕捉用户的组合特征,因此在被使用时,大家往往会增加一些人工的组合特征进去。

例如,我们在此改进为“两两特征组合”,当然也可使用多维特征的组合方式。
不过它存在的问题是:由于本身特征就很稀疏,如果做了组合,其对应的样本变得更加稀少。
而对于模型而言,样本是至关重要的,因此我们使用该模型无法学习到足够多的信息。
FM 模型

在此基础上,业内专家想了一种模型--FM 模型,它是把 LR 模型+“Dense 化两两特征组合”。
即并不直接对 WIJ 进行求导,而是把 WIJ 拆分成了两个向量纬度的乘积予以表现。
同时,它的向量与所有特征共同计算,因此它在泛化能力上有所提升。
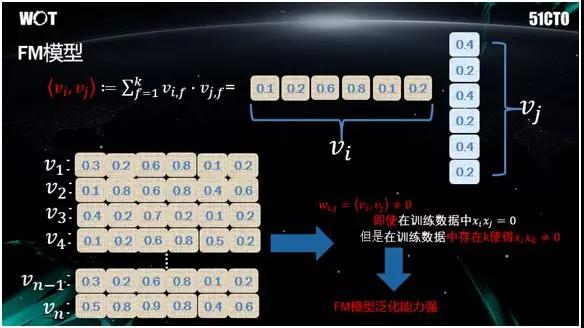
具体实现方式如上图所示。该模型在上线之后,在 Push 业务效果的提升非常明显。
Wide&Deep 模型
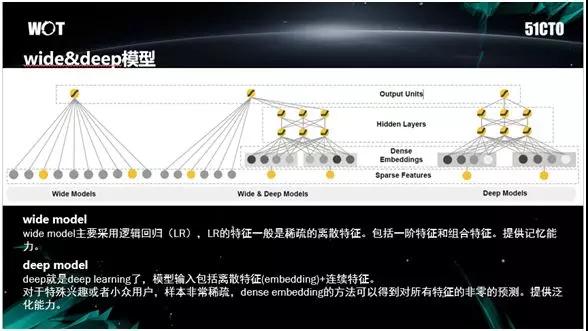
有了上述的两两特征组合之后,我们还引入了 Wide&Deep 模型。即:通过把 Wide 模型和 Deep 模型相结合,既保留了 Wide 模型里面的记忆能力,又具有一些高阶的特征组合优势。
因此,该模型具有更强的表现能力。当然,它也带来了计算量增加的问题。
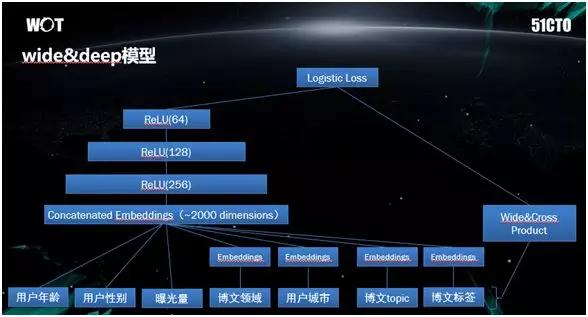
深度模型通常网络节点很多,用于线上业务计算量比较大,因此我们相对于原论文,进行了适当地裁剪。
我们使用该模型的网络结构如上图所示,三层网络节点分别是 64、128、256。尽量保证在离线指标下降较小的情况下,简化网络。
模型训练

下面和大家分享一下,我们在工作中遇到过的一些问题和使用的技巧。
对于微博中不同频次的用户而言,由于他们的使用习惯差异较大,如果简单地将其放入同一个模型,则效果不佳。
因此,我们对于不同用户的频次进行了拆分,分别训练了高频次、中频次和低频次类型的用户。同时,我们在负样本的选择上做了一些调整。
由于服务器在做推送(Push)的时候,用户不一定能真的收到、收到了也不一定会被系统所展示出来、就算系统展示出来了也不一定会被用户所看到。
因此我们不能简单地将推送曝光的样本作为负样本,而应当选取历史上有过正样本的用户,将他们在获得正样本触发时,所并未点击到的上下几条曝光,来作为负样本。
籍此,我们的表现能力、点击量和点击率都有了显著的提升。

其他的方法与技巧还包括:
- 在物料模型上,我们采取的是机器投稿+人工审核的方式。
- 在物料召回上,我们采用了兴趣领域召回、热点召回、和文本 embedding 召回等。
- 在排序的方面,我们使用了分片批量计算。因为我们每天要发送几个亿规模的推送量,如果每次都是进行全量计算的话,对于服务器的资源消耗会过大,当然也没有必要。

下面分享我们的两个方案。
BoostPush 方案
如果某个物料在未经充分验证的情况下,对所有的用户进行计算,那么就可能因为某一特征的影响导致分值特别高,而造成过大范围的下发。
如此,该不良物料会被展现给成百上千万用户。因此,我们首先会在一个特别小的范围内进行尝试,如果点击率特别高的话,我们再逐渐扩大其权限,层层扩量,直至全站。
通过该 BoostPush 方式,我们既控制了不良物料下发的范围,又将曝光的机会让给了充分验证完成的物料。通过此法,我们的点击量得到了大幅提升。
协同过滤方案
Push 除了能给用户带来最及时的消息推送以外,它还有一项非常重要的作用--给 App 的服务方提供“拉活”效果。
对于一般不常打开 App 的用户而言,推送在“拉活”方面的效果并不明显。
因此,我们需要选取曾经时常点击并打开 Push 消息的那些用户,以他们的行为作为推送的参考,来进行各种相应的协同下发方面的尝试。这对于我们“拉来”新的用户会十分有效。
上面就是我们在实际生产过程中所遇到过的问题,和相应的解决方案。
齐彦杰,新浪微博技术专家。毕业于郑州大学计算机系,微博研发中心技术专家。曾任职于某搜索公司高级架构师,多年从事爬虫、索引、检索、数据分析等方向的研发工作。目前在微博 User Growth 方向中,关注领域在数据挖掘、用户画像、自然语言处理、个性化推荐系统等领域,负责访客信息流推荐、Push 平台信息推荐、用户转化等业务。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】