一、实际问题
我们知道在流计算场景中,数据是源源不断的流入的,数据流永远不会结束,那么计算就永远不会结束,如果计算永远不会结束的话,那么计算结果何时输出呢?本篇将介绍Apache Flink利用持续查询来对流计算结果进行持续输出的实现原理。
二、数据管理
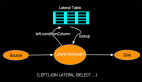
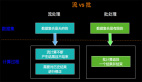
在介绍持续查询之前,我们先看看Apache Flink对数据的管理和传统数据库对数据管理的区别,以MySQL为例,如下图:

如上图所示传统数据库是数据存储和查询计算于一体的架构管理方式,这个很明显,oracle数据库不可能管理MySQL数据库数据,反之亦然,每种数据库厂商都有自己的数据库管理和存储的方式,各自有特有的实现。在这点上Apache Flink海纳百川(也有corner case),将data store 进行抽象,分为source(读) 和 sink(写)两种类型接口,然后结合不同存储的特点提供常用数据存储的内置实现,当然也支持用户自定义的实现。
那么在宏观设计上Apache Flink与传统数据库一样都可以对数据表进行SQL查询,并将产出的结果写入到数据存储里面,那么Apache Flink上面的SQL查询和传统数据库查询的区别是什么呢?Apache Flink又是如何做到求同(语义相同)存异(实现机制不同),***支持ANSI-SQL的呢?
三、静态查询
传统数据库中对表(比如 flink_tab,有user和clicks两列,user主键)的一个查询SQL(select * from flink_tab)在数据量允许的情况下,会立刻返回表中的所有数据,在查询结果显示之后,对数据库表flink_tab的DML操作将与执行的SQL无关了。也就是说传统数据库下面对表的查询是静态查询,将计算的最终查询的结果立即输出,如下:
- select * from flink_tab;
- +----+------+--------+
- | id | user | clicks |
- +----+------+--------+
- | 1 | Mary | 1 |
- +----+------+--------+
- 1 row in set (0.00 sec)
当我执行完上面的查询,查询结果立即返回,上面情况告诉我们表 flink_tab里面只有一条记录,id=1,user=Mary,clicks=1; 这样传统数据库表的一条查询语句就完全结束了。传统数据库表在查询那一刻我们这里叫Static table,是指在查询的那一刻数据库表的内容不再变化了,查询进行一次计算完成之后表的变化也与本次查询无关了,我们将在Static Table 上面的查询叫做静态查询。
四、持续查询
什么是连续查询呢?连续查询发生在流计算上面,在 《Apache Flink 漫谈系列 - 流表对偶(duality)性》 中我们提到过Dynamic Table,连续查询是作用在Dynamic table上面的,永远不会结束的,随着表内容的变化计算在不断的进行着...
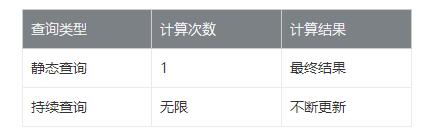
五、静态/持续查询特点
静态查询和持续查询的特点就是《Apache Flink 漫谈系列 - 流表对偶(duality)性》中所提到的批与流的计算特点,批一次查询返回一个计算结果就结束查询,流一次查询不断修正计算结果,查询永远不结束,表格示意如下:
六、静态/持续查询关系
接下来我们以flink_tab表实际操作为例,体验一下静态查询与持续查询的关系。假如我们对flink_tab表再进行一条增加和一次更新操作,如下:
- MySQL> insert into flink_tab(user, clicks) values ('Bob', 1);
- Query OK, 1 row affected (0.08 sec)
- MySQL> update flink_tab set clicks=2 where user='Mary';
- Query OK, 1 row affected (0.06 sec)
这时候我们再进行查询 select * from flink_tab ,结果如下:
- MySQL> select * from flink_tab;
- +----+------+--------+
- | id | user | clicks |
- +----+------+--------+
- | 1 | Mary | 2 |
- | 2 | Bob | 1 |
- +----+------+--------+
- 2 rows in set (0.00 sec)
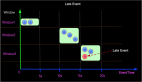
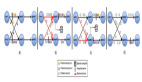
那么我们看见,相同的查询SQL(select * from flink_tab),计算结果完全 不 一样了。这说明相同的sql语句,在不同的时刻执行计算,得到的结果可能不一样(有点像废话),就如下图一样:
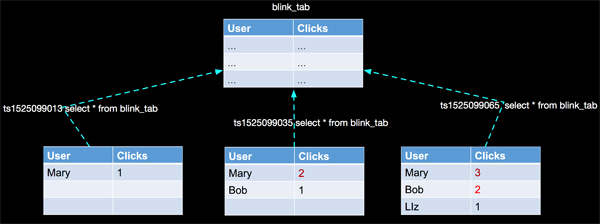
假设不断的有人在对表flink_tab做操作,同时有一个人间歇性的发起对表数据的查询,上图我们只是在三个时间点进行了3次查询。并且在这段时间内数据表的内容也在变化。引起上面变化的DML如下:
- MySQL> insert into flink_tab(user, clicks) values ('Llz', 1);
- Query OK, 1 row affected (0.08 sec)
- MySQL> update flink_tab set clicks=2 where user='Bob';
- Query OK, 1 row affected (0.01 sec)
- Rows matched: 1 Changed: 1 Warnings: 0
- MySQL> update flink_tab set clicks=3 where user='Mary';
- Query OK, 1 row affected (0.05 sec)
- Rows matched: 1 Changed: 1 Warnings: 0
到现在我们不难想象,上面图内容的核心要点如下:
- 时间
- 表数据变化
- 触发计算
- 计算结果更新
接下来我们利用传统数据库现有的机制模拟一下持续查询...
1. 无PK的 Append only 场景
接下来我们把上面隐式存在的时间属性timestamp作为表flink_tab_ts(timestamp,user,clicks三列,无主键)的一列,再写一个 触发器(Trigger) 示例观察一下:
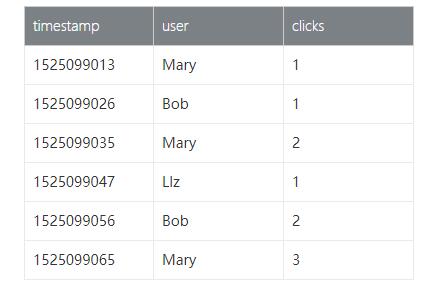
- // INSERT 的时候查询一下数据flink_tab_ts,将结果写到trigger.sql中
- DELIMITER ;;
- create trigger flink_tab_ts_trigger_insert after insert
- on flink_tab_ts for each row
- begin
- select ts, user, clicks from flink_tab_ts into OUTFILE '/Users/jincheng.sunjc/testdir/atas/trigger.sql';
- end ;;
- DELIMITER ;
上面的trigger要将查询结果写入本地文件,默认MySQL是不允许写入的,我们查看一下:
- MySQL> show variables like '%secure%';
- +--------------------------+-------+
- | Variable_name | Value |
- +--------------------------+-------+
- | require_secure_transport | OFF |
- | secure_file_priv | NULL |
- +--------------------------+-------+
- 2 rows in set (0.00 sec)
上面secure_file_priv属性为NULL,说明MySQL不允许写入file,我需要修改my.cnf在添加secure_file_priv=''打开写文件限制;
- MySQL> show variables like '%secure%';
- +--------------------------+-------+
- | Variable_name | Value |
- +--------------------------+-------+
- | require_secure_transport | OFF |
- | secure_file_priv | |
- +--------------------------+-------+
- 2 rows in set (0.00 sec)
下面我们对flink_tab_ts进行INSERT操作:

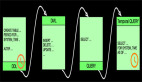
我们再来看看6次trigger 查询计算的结果:

大家到这里发现我写了Trigger的存储过程之后,每次在数据表flink_tab_ts进行DML操作的时候,Trigger就会触发一次查询计算,产出一份新的计算结果,观察上面的查询结果发现,结果表不停的增加(Append only)。
2. 有PK的Update场景
我们利用flink_tab_ts的6次DML操作和自定义的触发器TriggerL来介绍了什么是持续查询,做处理静态查询与持续查询的关系。那么上面的演示目的是为了说明持续查询,所有操作都是insert,没有基于主键的更新,也就是说Trigger产生的结果都是append only的,那么大家想一想,如果我们操作flink_tab这张表,按主键user进行插入和更新操作,同样利用Trigger机制来进行持续查询,结果是怎样的的呢? 初始化表,trigger:
- drop table flink_tab;
- create table flink_tab(
- user VARCHAR(100) NOT NULL,
- clicks INT NOT NULL,
- PRIMARY KEY (user)
- );
- DELIMITER ;;
- create trigger flink_tab_trigger_insert after insert
- on flink_tab for each row
- begin
- select user, clicks from flink_tab into OUTFILE '/tmp/trigger.sql';
- end ;;
- DELIMITER ;
- DELIMITER ;;
- create trigger flink_tab_trigger_ after update
- on flink_tab for each row
- begin
- select ts, user, clicks from flink_tab into OUTFILE '/tmp/trigger.sql';
- end ;;
- DELIMITER ;
同样我做如下6次DML操作,Trigger 6次查询计算:
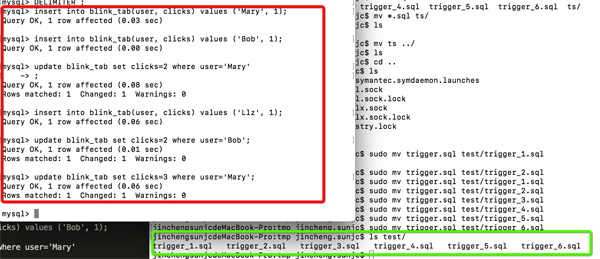
在来看看这次的结果与append only 有什么不同?

我想大家早就知道这结果了,数据库里面定义的PK所有变化会按PK更新,那么触发的6次计算中也会得到更新后的结果,这应该不难理解,查询结果也是不断更新的(Update)!
3. 关系定义
上面Append Only 和 Update两种场景在MySQL上面都可以利用Trigger机制模拟 持续查询的概念,也就是说数据表中每次数据变化,我们都触发一次相同的查询计算(只是计算时候数据的集合发生了变化),因为数据表不断的变化,这个表就可以看做是一个动态表Dynamic Table,而查询SQL(select * from flink_tab_ts) 被触发器Trigger在满足某种条件后不停的触发计算,进而也不断地产生新的结果。这种作用在Dynamic Table,并且有某种机制(Trigger)不断的触发计算的查询我们就称之为 持续查询。
那么到底静态查询和动态查询的关系是什么呢?在语义上 持续查询 中的每一次查询计算的触发都是一次静态查询(相对于当时查询的时间点), 在实现上 Apache Flink会利用上一次查询结果+当前记录 以增量的方式完成查询计算。
特别说明: 上面我们利用 数据变化+Trigger方式描述了持续查询的概念,这里有必要特别强调一下的是数据库中trigger机制触发的查询,每次都是一个全量查询,这与Apache Flink上面流计算的持续查询概念相同,但实现机制完全不同,Apache Flink上面的持续查询内部实现是增量处理的,随着时间的推移,每条数据的到来实时处理当前的那一条记录,不会处理曾经来过的历史记录!
七、Apache Flink 如何做到持续查询
1. 动态表上面持续查询
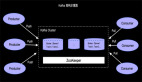
在 《Apache Flink 漫谈系列 - 流表对偶(duality)性》 中我们了解到流和表可以相互转换,在Apache Flink流计算中携带流事件的Schema,经过算子计算之后再产生具有新的Schema的事件,流入下游节点,在产生新的Schema的Event和不断流转的过程就是持续查询作用的结果,如下图:

2. 增量计算
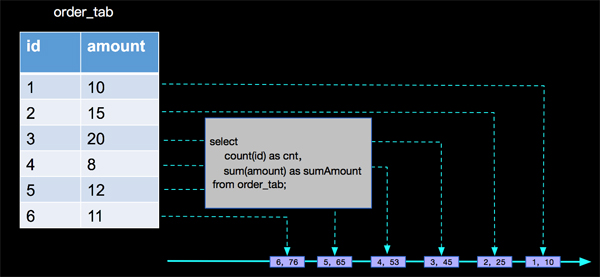
我们进行查询大多数场景是进行数据聚合,比如查询SQL中利用count,sum等aggregate function进行聚合统计,那么流上的数据源源不断的流入,我们既不能等所有事件流入结束(永远不会结束)再计算,也不会每次来一条事件就像传统数据库一样将全部事件集合重新整体计算一次,在持续查询的计算过程中,Apache Flink采用增量计算的方式,也就是每次计算都会将计算结果存储到state中,下一条事件到来的时候利用上次计算的结果和当前的事件进行聚合计算,比如 有一个订单表,如下:
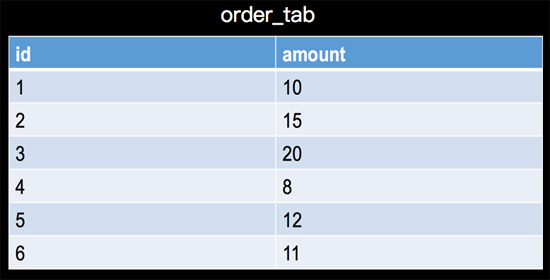
一个简单的计数和求和查询SQL:
- // 求订单总数和所有订单的总金额
- select count(id) as cnt,sum(amount)as sumAmount from order_tab;
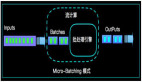
这样一个简单的持续查询计算,Apache Flink内部是如何处理的呢?如下图:

如上图,Apache Flink中每来一条事件,就进行一次计算,并且每次计算后结果会存储到state中,供下一条事件到来时候进行计算,即:
- result(n) = calculation(result(n-1), n)。
3. 无PK的Append Only 场景
在实际的业务场景中,我们只需要进行简单的数据统计,然后就将统计结果写入到业务的数据存储系统里面,比如上面统计订单数量和总金额的场景,订单表本身是一个append only的数据源(假设没有更新,截止到2018.5.14日,Apache Flink内部支持的数据源都是append only的),在持续查询过程中经过count(id),sum(amount)统计计算之后产生的动态表也是append only的,种场景Apache Flink内部只需要进行aggregate function的聚合统计计算就可以,如下:
4. 有PK的Update 场景
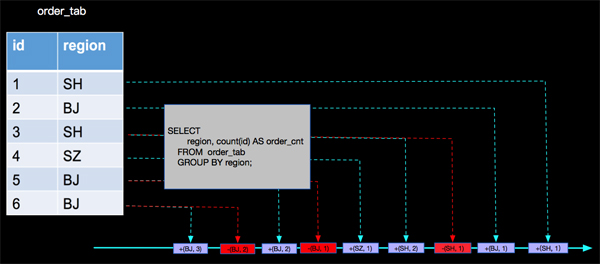
现在我们将上面的订单场景稍微变化一下,在数据表上面我们将金额字段amount,变为地区字段region,数据如下:
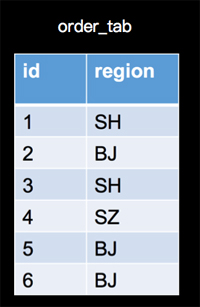
查询统计的变为,在计算具有相同订单数量的地区数量;查询SQL如下:
- CREATE TABLE order_tab(
- id BIGINT,
- region VARCHAR
- )
- CREATE TABLE region_count_sink(
- order_cnt BIGINT,
- region_cnt BIGINT,
- PRIMARY KEY(order_cnt) -- 主键
- )
- -- 按地区分组计算每个地区的订单数量
- CREATE VIEW order_count_view AS
- SELECT
- region, count(id) AS order_cnt
- FROM order_tab
- GROUP BY region;
- -- 按订单数量分组统计具有相同订单数量的地区数量
- INSERT INTO region_count_sink
- SELECT
- order_cnt,
- count(region) as region_cnt
- FROM order_count_view
- GROUP BY order_cnt;
上面查询SQL的代码结构如下(这个图示在Alibaba 对 Apache Flink 的增强的集成IDE环境生成的,了解更多):

上面SQL中我们发现有两层查询计算逻辑,***个查询计算逻辑是与SOURCE相连的按地区统计订单数量的分组统计,第二个查询计算逻辑是在***个查询产出的动态表上面进行按订单数量统计地区数量的分组统计,我们一层一层分析。
5. 错误处理
- ***层分析:SELECT region, count(id) AS order_cnt FROM order_tab GROUP BY region;
- 第二层分析:SELECT order_cnt, count(region) as region_cnt FROM order_count_view GROUP BY order_cnt;
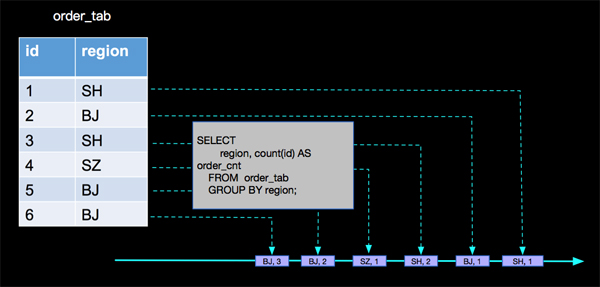
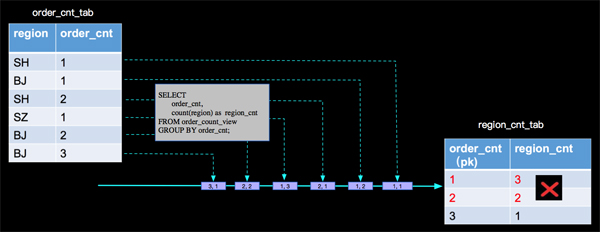
按照***层分析的结果,再分析第二层产出的结果,我们分析的过程是对的,但是最终写到sink表的计算结果是错误的,那我们错在哪里了呢?
其实当 (SH,2)这条记录来的时候,以前来过的(SH, 1)已经是脏数据了,当(BJ, 2)来的时候,已经参与过计算的(BJ, 1)也变成脏数据了,同样当(BJ, 3)来的时候,(BJ, 2)也是脏数据了,上面的分析,没有处理脏数据进而导致最终结果的错误。那么Apache Flink内部是如何正确处理的呢?
6. 正确处理
- ***层分析:SELECT region, count(id) AS order_cnt FROM order_tab GROUP BY region;
- 第二层分析:SELECT order_cnt, count(region) as region_cnt FROM order_count_view GROUP BY order_cnt;
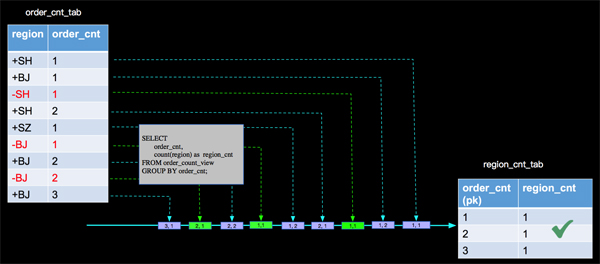
上面我们将有更新的事件进行打标的方式来处理脏数据,这样在Apache Flink内部计算的时候 算子会根据事件的打标来处理事件,在aggregate function中有两个对应的方法(retract和accumulate)来处理不同标识的事件,如上面用到的count AGG,内部实现如下:
- def accumulate(acc: CountAccumulator): Unit = {
- acc.f0 += 1L // acc.f0 存储记数
- }
- def retract(acc: CountAccumulator, value: Any): Unit = {
- if (value != null) {
- acc.f0 -= 1L //acc.f0 存储记数
- }}
Apache Flink内部这种为事件进行打标的机制叫做 retraction。retraction机制保障了在流上已经流转到下游的脏数据需要被撤回问题,进而保障了持续查询的正确语义。
八、Apache Flink Connector 类型
本篇一开始就对比了MySQL的数据存储和Apache Flink数据存储的区别,Apache Flink目前是一个计算平台,将数据的存储以高度抽象的插件机制与各种已有的数据存储无缝对接。目前Apache Flink中将数据插件称之为链接器Connector,Connnector又按数据的读和写分成Soruce(读)和Sink(写)两种类型。对于传统数据库表,PK是一个很重要的属性,在频繁的按某些字段(PK)进行更新的场景,在表上定义PK非常重要。那么作为完全支持ANSI-SQL的Apache Flink平台在Connector上面是否也支持PK的定义呢?
1. Apache Flink Source
现在(2018.11.***pache Flink中用于数据流驱动的Source Connector上面无法定义PK,这样在某些业务场景下会造成数据量较大,造成计算资源不必要的浪费,甚至有聚合结果不是用户“期望”的情况。我们以双流JOIN为例来说明:
- SQL:
- CREATE TABLE inventory_tab(
- product_id VARCHAR,
- product_count BIGINT
- );
- CREATE TABLE sales_tab(
- product_id VARCHAR,
- sales_count BIGINT
- ) ;
- CREATE TABLE join_sink(
- product_id VARCHAR,
- product_count BIGINT,
- sales_count BIGINT,
- PRIMARY KEY(product_id)
- );
- CREATE VIEW join_view AS
- SELECT
- l.product_id,
- l.product_count,
- r.sales_count
- FROM inventory_tab l
- JOIN sales_tab r
- ON l.product_id = r.product_id;
- INSERT INTO join_sink
- SELECT
- product_id,
- product_count,
- sales_count
- FROM join_view ;
代码结构图:
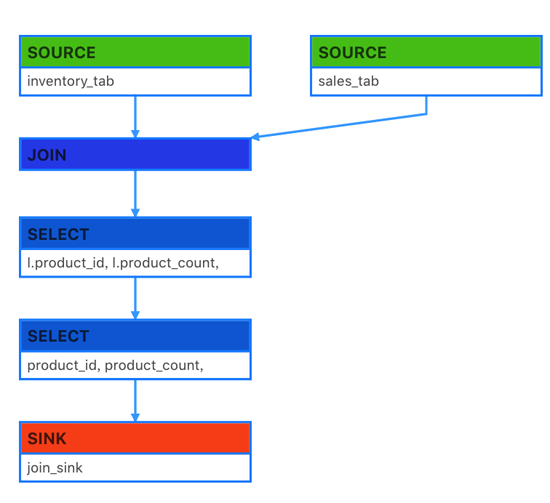
实现示意图:

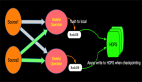
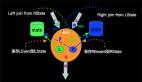
上图描述了一个双流JOIN的场景,双流JOIN的底层实现会将左(L)右(R)两面的数据都持久化到Apache Flink的State中,当L流入一条事件,首先会持久化到LState,然后在和RState中存储的R中所有事件进行条件匹配,这样的逻辑如果R流product_id为P001的产品销售记录已经流入4条,L流的(P001, 48) 流入的时候会匹配4条事件流入下游(join_sink)。
2. 问题
上面双流JOIN的场景,我们发现其实inventory和sales表是有业务的PK的,也就是两张表上面的product_id是唯一的,但是由于我们在Sorure上面无法定义PK字段,表上面所有的数据都会以append only的方式从source流入到下游计算节点JOIN,这样就导致了JOIN内部所有product_id相同的记录都会被匹配流入下游,上面的例子是 (P001, 48) 来到的时候,就向下游流入了4条记录,不难想象每个product_id相同的记录都会与历史上所有事件进行匹配,进而操作下游数据压力。
那么这样的压力是必要的吗?从业务的角度看,不是必要的,因为对于product_id相同的记录,我们只需要对左右两边***的记录进行JOIN匹配就可以了。比如(P001, 48)到来了,业务上面只需要右流的(P001, 22)匹配就好,流入下游一条事件(P001, 48, 22)。 那么目前在Apache Flink上面如何做到这样的优化呢?
3. 解决方案
上面的问题根本上我们要构建一张有PK的动态表,这样按照业务PK进行更新处理,我们可以在Source后面添加group by 操作生产一张有PK的动态表。如下:
- SQL:
- CREATE TABLE inventory_tab(
- product_id VARCHAR,
- product_count BIGINT
- )
- CREATE TABLE sales_tab(
- product_id VARCHAR,
- sales_count BIGINT
- )
- CREATE VIEW inventory_view AS
- SELECT
- product_id,
- LAST_VALUE(product_count) AS product_count
- FROM inventory_tab
- GROUP BY product_id;
- CREATE VIEW sales_view AS
- SELECT
- product_id,
- LAST_VALUE(sales_count) AS sales_count
- FROM sales_tab
- GROUP BY product_id;
- CREATE TABLE join_sink(
- product_id VARCHAR,
- product_count BIGINT,
- sales_count BIGINT,
- PRIMARY KEY(product_id)
- )WITH (
- type = 'print'
- ) ;
- CREATE VIEW join_view AS
- SELECT
- l.product_id,
- l.product_count,
- r.sales_count
- FROM inventory_view l
- JOIN sales_view r
- ON l.product_id = r.product_id;
- INSERT INTO join_sink
- SELECT
- product_id,
- product_count,
- sales_count
- FROM join_view ;
代码结构:
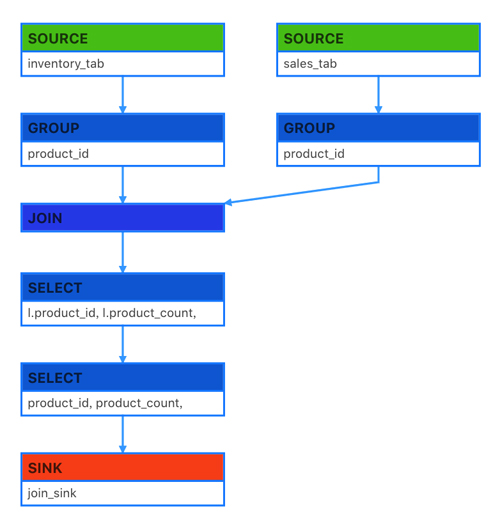
示意图:

如上方式可以将无PK的source经过一次节点变成有PK的动态表,以Apache Flink的retract机制和业务要素解决数据瓶颈,减少计算资源的消耗。
说明1: 上面方案LAST_VALUE是Alibaba对 Apache Flink 的增强的功能,社区还没有支持。
4. Apache Flink Sink
在Apache Flink上面可以根据实际外部存储的特点(是否支持PK),以及整体job的执行plan来动态推导Sink的执行模式,具体有如下三种类型:
Append 模式 - 该模式用户在定义Sink的DDL时候不定义PK,在Apache Flink内部生成的所有只有INSERT语句;
Upsert 模式 - 该模式用户在定义Sink的DDL时候可以定义PK,在Apache Flink内部会根据事件打标(retract机制)生成INSERT/UPDATE和DELETE 语句,其中如果定义了PK, UPDATE语句按PK进行更新,如果没有定义PK UPDATE会按整行更新;
Retract 模式 - 该模式下会产生INSERT和DELETE两种信息,Sink Connector 根据这两种信息构造对应的数据操作指令;
九、小结
本篇以MySQL为例介绍了传统数据库的静态查询和利用MySQL的Trigger+DML操作来模拟持续查询,并介绍了Apache Flink上面利用增量模式完成持续查询,并以双流JOIN为例说明了持续查询可能会遇到的问题,并且介绍Apache Flink以为事件打标产生delete事件的方式解决持续查询的问题,进而保证语义的正确性,***的在流计算上支持续查询。
# 关于点赞和评论
本系列文章难免有很多缺陷和不足,真诚希望读者对有收获的篇章给予点赞鼓励,对有不足的篇章给予反馈和建议,先行感谢大家!
作者:孙金城,花名 金竹,目前就职于阿里巴巴,自2015年以来一直投入于基于Apache Flink的阿里巴巴计算平台Blink的设计研发工作。
【本文为51CTO专栏作者“金竹”原创稿件,转载请联系原作者】