达达-京东到家作为优秀的即时配送物流平台,实现了多渠道的订单配送,包括外卖平台的餐饮订单、新零售的生鲜订单、知名商户的优质订单等。为了提升平台的用户粘性,我们需要兼顾商户和骑士的各自愿景:商户希望订单能够准时送达,骑士希望可以高效抢单。那么在合适的时候提升订单定制化的曝光率,是及时送物流平台的核心竞争力之一。
本文将描述订单派发系统从无到有的系统演进以及方案设计与关键要点,为大家在解决相关业务场景上提供一个案例参考。
订单派发架构演进
在公司发展的初期,我们的外卖订单从商户发单之后直接出现在抢单池中,3公里之内的骑士能够看到订单,并且从订单卡片中获取配送地址、配送时效等关键信息。这种暴力的显示模式,很容易造成骑士挑选有利于自身的订单进行配送,从而导致部分订单超时未被配送。这样的模式,在一定程度上导致了商户的流失,同时也浪费了骑士的配送时间。
从上面的场景可以看出来,我们系统中缺少一个订单核心调度者。有一种方案是选择区域订单的订单调度员,由调度员根据骑士的接单情况、配送时间、订单挤压等实时情况来进行订单调度。这种模式,看似可行,但是人力成本投入太高,且比较依赖个人的经验总结。
核心问题已经出来了:个人的经验总结会是什么呢?
- 骑士正在配送的订单的数量,是否已经饱和
- 骑士的配送习惯是什么
- 某一阶段的订单是否顺路,骑士是否可以一起配送
- 骑士到店驻留时间的预估
- ...
理清核心问题的答案,我们的系统派单便成为了可能。基于以上的原理,订单派发模式就可以逐渐从抢单池的订单显示演变成系统派单。
我们将会记录商户发单行为、骑士配送日志及运行轨迹等信息,并且经过数据挖掘和数据分析,获取骑士的画像、骑士配送时间的预估、骑士到店驻留时间的预估等基础信息;使用遗传算法规划出最优的配送路径...经过上述一系列算法,我们将在骑士池中匹配出最合适的骑士,进而使用长连接(Netty)不间断的通知到骑士。
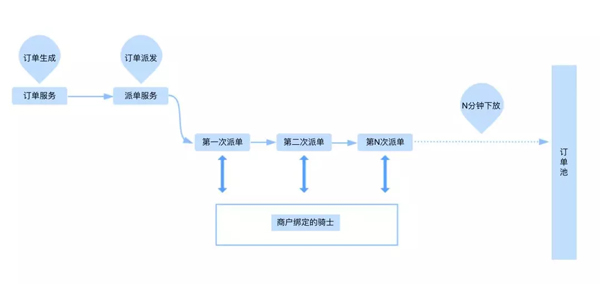
随着达达业务的不断迭代,订单配送逐渐孵化出基于大商户的驻店模式:基于商户维护一批固定的专属骑士,订单只会在运力不足的时候才会外发到抢单池中,正常情况使用派单模式通知骑士。
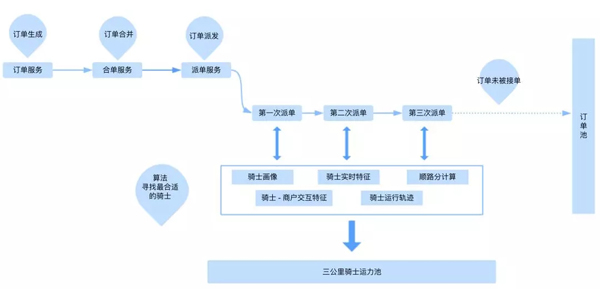
订单派发模型
订单派发可以浅显的认为是一种信息流的推荐。在订单进入抢单池之前,我们会根据每个城市的调度情况,先进行轮询N次的派单。大概的表现形式如下图:
举例有笔订单需要进行推送,在推送过程中,我们暂且假设一直没有骑士接单,那么这笔订单会每间隔N秒便会进行一次普通推荐,然后进入抢单池。
从订单派发的流程周期上可以看出来,派发模型充斥着大量的延迟任务,只要能解决订单在什么时候可以进行派发,那么整个系统 50% 的功能点就能迎刃而解。
我们先了解一下经典的延迟方案:
1. 数据库轮询
通过一个线程定时的扫描数据库,获取到需要派单的订单信息
- 优点:开发简单,结合quartz即可以满足分布式扫描
- 缺点:对数据库服务器压力大,不利于项目后续发展
2. JDK的延迟队列 - DelayQueue
DelayQueue是Delayed元素的一个无界阻塞队列,只有在延迟期满时才能从中提取元素。队列中对象的顺序按到期时间进行排序。
- 优点:开发简单,效率高,任务触发时间延迟低
- 缺点:服务器重启后,数据会丢失,要满足高可用场景,需要hook线程二次开发;宕机的担忧;如果数据量暴增,也会引起OOM的情况产生
3. 时间轮 - TimingWheel
时间轮的结构原理很简单,它是一个存储定时任务的环形队列,底层是由数组实现,而数组中的每个元素都可以存放一个定时任务列表,列表中的每一项都表示一个事件操作单元,当时间指针指向对应的时间格的时候,该列表中的所有任务都会被执行。 时间轮由多个时间格组成,每个时间格代表着当前实践论的跨度,用tickMs代表;时间轮的个数是固定的,用wheelSize代表;整个时间轮的跨度用interval代表,那么指针转了一圈的时间为:
- interval = tickMs * wheelSize
如果tickMs=1ms,wheelSize=20,那么便能计算出此时的时间是以20ms为一转动周期,时间指针(currentTime)指向wheelSize=0的数据槽,此时有5ms延迟的任务插入了wheelSize=5的时间格,随着时间的不断推移,指针currentTime不断向前推进,过了5ms之后,当到达时间格5时,就需要将时间格5所对应的任务做相应的到期操作。
如果此时有个定时为180ms的任务该如何处理?很直观的思路是直接扩充wheelSize?这样会导致wheelSize的扩充会随着业务的发展而不断扩张,这样会使时间轮占用很大的内存空间,导致效率低下,因此便衍生出了层级时间轮的数据结构。
180ms的任务会升级到第二层时间轮中,最终被插入到第二层时间轮中时间格#8所对应的TimerTaskList中。如果此时又有一个定时为600ms的任务,那么显然第二层时间轮也无法满足条件,所以又升级到第三层时间轮中,最终被插入到第三层时间轮中时间格#1的TimerTaskList中。注意到在到期时间在[400ms,800ms)区间的多个任务(比如446ms、455ms以及473ms的定时任务)都会被放入到第三层时间轮的时间格#1中,时间格#1对应的TimerTaskList的超时时间为400ms。
随着时间轮的转动,当TimerTaskList到期时,原本定时为450ms的任务还剩下50ms的时间,还不能执行这个任务的到期操作。便会有个时间轮降级的操作,会将这个剩余时间50ms的定时任务重新提交到下一层级的时间轮中,所以该任务被放到第二层时间轮到期时间为 [40ms,60ms) 的时间格中。再经历了40ms之后,此时这个任务又被触发到,不过还剩余10ms,还是不能立即执行到期操作。所以还要再一次的降级,此任务会被添加到第一层时间轮到期时间为[10ms,11ms)的时间格中,之后再经历10ms后,此任务真正到期,最终执行相应的到期操作。
- 优点:效率高,可靠性高(Netty,Kafka,Akka均有使用),便于开发
- 缺点:数据存储在内存中,需要自己实现持久化的方案来实现高可用
订单派发实现方案
结合了上述的三种方案,最后决定使用redis作为数据存储,使用timingWhell作为时间的推动者。这样便可以将定时任务的存储和时间推动进行解耦,依赖Redis的AOF机制,也不用过于担心订单数据的丢失。
kafka中为了处理成千上万的延时任务选择了多层时间轮的设计,我们从业务角度和开发难度上做了取舍,只选择设计单层的时间轮便可以满足需求。
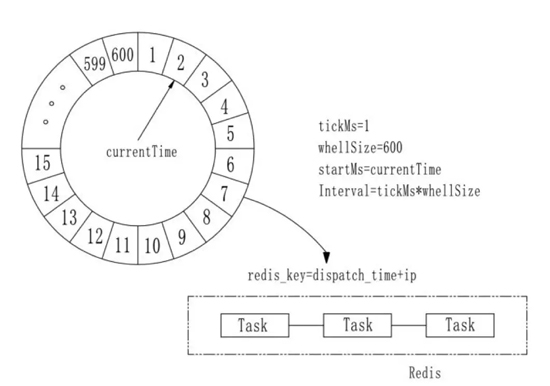
1. 时间格和缓存的映射维护
假设当前时间currentTime为11:49:50,订单派发时间dispatchTime为11:49:57,那么时间轮的时间格#7中会设置一个哨兵节点(作为是否有数据存储在redis的依据 )用来表示该时间段是否会时间事件触发,同时会将这份数据放入到缓存中(key=dispatchTime+ip), 当7秒过后,触发了该时间段的数据,便会从redis中获取数据,异步执行相应的业务逻辑。最后,防止由于重启等一些操作导致数据的丢失,哨兵节点的维护也会在缓存中维护一份数据,在重启的时候重新读取
2. 缓存的key统一加上IP标识
由于我们的时间调度器是依附于自身系统的,通过将缓存的key统一加上IP的标识,这样就可以保证各台服务器消费属于自身的数据,从而防止分布式环境下的并发问题,也可以减轻遍历整个列表带来的时间损耗(时间复杂度为O(N))
3. 使用异步线程处理时间格中对应的数据
使用异步线程,是考虑到如果上一个节点发生异常或者超时等情况,会延误下一秒的操作,如果使用异常可以改善调度的即时性问题。
我们在设计系统的时候,系统的完善度和业务的满足度是互相关联影响的,单从上述的设计看,是会有些问题的,比如使用IP作为缓存的key,如果集群发生变更便会导致数据不会被消费;使用线程池异步处理也有概率导致数据不会被消费。这些不会被消费的数据会进入到抢单池中。从派单场景的需求来看,这些场景是可以被接受的,当然了,我们系统会有脚本来进行定期的筛选,将那些进入抢单池的订单进行再次派单。
为什么不使用ScheduledThreadPoolExecutor来定时轮询redis? 即便这样可以完成业务上的需求,获取定时触发的任务,但是带来的空查询不但会拉高服务的CPU,redis的QPS也会被拉高,可能会导致redis的慢查询会显著增多。
结语
我们在完成一个功能的时候,往往需要一些可视化的数据来确定业务发展的正确性。因此我们在开发的时候,也相应的记录了一些订单与骑士的交互动作。从每天的报表数据可以看出来,90% 以上的订单是通过派单发出并且被骑士认可接单。
订单派发的模式是提升订单曝光率有效的技术手段,我们一直结合大数据、人工智能等技术手段希望能更好的做好订单派发,能提供更加多元化的功能,将达达打造成更加一流的配送平台。
作者:季炳坤,任职Java工程师,负责订单派发,订单权限,合并订单等相关工作。
【本文来自51CTO专栏作者张开涛的微信公众号(开涛的博客),公众号id: kaitao-1234567】