阿里一面
1.自我介绍下:
我是XXX的硕士,机器学习专业,我研究方向偏向于深度学习;然后我本科是XXX的物联网工程专业,本科做过两个项目:
(1)基于大数据的股票市场分析(2)基于用户操作的推荐系统 ;研究生阶段目前印象最深是做了两个项目:
1)机器人课程作业中的challenge
2)现在正在做的基于model的智能机器学习框架,着重介绍在***一个,然后问了下实际工作,完成程度,贡献度。***追问了一个对于物联网的看法。
2.hashmap介绍
先说了下自己知道JAVA的hash map的用法,python中dictionary也是用hash表实现的:首先利用hash()将key和value映射到一个地址,它通过把key和value映射到表中一个位置来访问记录,这种查询速度非常快,更新也快。而这个映射函数叫做哈希函数,存放值的数组叫做哈希表。 哈希函数的实现方式决定了哈希表的搜索效率。具体操作过程是:
1)数据添加:把key通过哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。
2)数据查询:再次使用哈希函数将key转换为对应的数组下标,并定位到数组的位置获取value。
但是,对key进行hash的时候,不同的key可能hash出来的结果是一样的,尤其是数据量增多的时候,这个问题叫做哈希冲突。如果解决这种冲突情况呢?通常的做法有两种,一种是链接法,另一种是开放寻址法,Python选择后者。
开放寻址法(open addressing):
开放寻址法中,所有的元素都存放在散列表里,当产生哈希冲突时,通过一个探测函数计算出下一个候选位置,如果下一个获选位置还是有冲突,那么不断通过探测函数往下找,直到找个一个空槽来存放待插入元素。
3.算法:快排的时间复杂度和空间复杂度?平均多少?最差多少?还有那些排序的时间复杂度是O(nlogn)?知道排序中的稳定性吗?我:快排的时间复杂度我记很清楚是O(nlogn),空间复杂度是O(1),平均就是O(nlogn),最差是O(n^2),退化成了冒泡排序;此外还有时间复杂度为O(nlogn)的还有堆排序和归并排序;排序的稳定性知道是在排序之前,有两个元素A1,A2,A1在A2之前,在排序之后还是A1在A2之前。
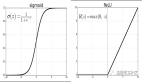
4.SVM和Logistic Regression对比:首先我介绍了下logistics regression的过程,就是把y=wx+b的结果放到sigmoid函数里,把sigmoid作为一个分类器,这样做的原因是sigmoid函数能把所有范围的值域控制在(0,1)区间内,然后我们把0.5作为一个分类的阈值,大于0.5的作为正类,小于0.5的作为负类。然后SVM是一个利用超平面将数据隔开分类的问题,首先我们在max所有距离平面最近的点的margin,同时subject to y(wx+b)>0,意味着分类正确:
然后:我们可以的到最近点到平面的距离:
我们***再用拉格朗日乘子式将subjuct to 条件转换成一个等式求解***的w,b 然后求得最有超平面。我说SVM有很多kernel,这个有点像regulation,面试官说错了,你讲讲kernel是什么干什么用的?我说kernel是把数据把低维映射到高维,因为有些数据在低维不可分,映射高维可以找到超平面去划分,更好准确。
***说了LR比较方便计算,SVM 高维kernel计算复杂,但是准确。如果数据多,要求实时得到预测结果,用LR;如果数据不多,要求准确率,我选择SVM。另外SVM可以用于多分类,而LR只能用于二分类
5.解决Overfitting、regulation的方法:regulation,我才总结下了,大致主要聊了2点:
(1)dropout,介绍dropout的概念啊,问了下train和test阶段的不一样过程细节。
主要讲了下test把active function的输出都乘以P,这样就把train和test的输出期望都scale到了一个range,这样才是更加准确的。
(2)Batch Normalisation:BN,BN的原理,问什么好,好在哪里?
1)降低了样本之间的差异,scale到(0,1)。
2)降低了层层之间的依赖,主要体现在前一层的输出是下一层的输入,那么我们把所有数据都scale到了(0,1)的distribution,那么降低了层层之间的依赖关系,从而使数据更加准确。
全程聊了一个小时,我人都傻了,一面不是面简历吗?(内心OS。***问了面试官两个问题:1)我本来跟老板汇报了工作在路上走着,电话就来了,我就说没准备好问了下面试官对我的评价,然后面试官很nice说基本面不错,给我评价偏正面;2)问了面试官的部门工作内容,balala讲了一堆。然后跟我说,后面可能有人联系你,也可能没人联系你,有人联系的话,可能是他同事。
二面
一,介绍自己及项目:主要介绍自己在TensorLayer框架的制作,贡献,太细节了,导致面试官说本来要问我的都说了。
二.基础考察:
1.你知道感知野吗?什么作用?你知道卷积的作用吗?你用过池化层吗?有哪些?
当时一脸懵逼,感知野是神马啊?***再次确认了感知野其实就是在多个kernel做卷积的时候的窗口区域,就是3个33等于1个77的感知大小。
卷积的作用是提取特征,前面的卷积提取类似于人眼能识别的初步特征,后面的卷积是能够提取更加不容易发现但是真实存在的特征。
Pooling 用过,max pooling, average pooling, global average pooling。再问这两个分别有什么用?
max pooling我蠢到说提取最有特征的特征,其实就是***有代表性的特征;average pooling提取的是比较general 的特征;global average pooling用来分类的,因为后面网络的加深,full connected layer参数太多了,不容易训练,为了快速准确得到结果,采用global average pooling,没有参数,但是得到的分类效果跟FC差不多。
2. 讲到这里有点尬,你说你做过爬虫,自己写的还是用的框架?
用的框架,现在基本不用java我觉得我还是要补一补,差不多都忘光了,我所做的就是用Xpath找到爬取的元素,然后保存下来,再用脚本转成待用Jason。
3.你机器学习的,知道sequence to sequence吗?
我***反应是RNN,我说RNN没了解,主要我只做深度学习CNN相关工作,大佬呵呵一笑,说你们要补补基础啊。
4. 在线编程:
给个题目你写写吧,不用math中的取平法差,判断一个自然数是不是可以开方(时间复杂度尽量低)?
妈耶,***反应二分查找。
一上去尬了写了一个boolean,然后删除,搞了个def开始写函数。
***问了2个问题,他又问了我2个问题:(1)(这次是个P8大佬)在杭州,你工作地点介不介意?(我多说了几句话,开了地图炮,真的内心话)(2)你作为tensorlayer的contributor,对标Kreas,优势在哪里?他说Kears底层支持好多库caffe2,Pytorch,等等,我说TensorLayer出发点不一样,怎么样比比了一通,方正我觉得没逻辑~感觉自己凉了~因为面试官给我回馈就是你要拓展你的机器学习知识面啊啊啊,我一个搞机器学习被吐槽这样。。。
三面
全程50分钟,主要讲的是项目:针对项目提出几个优化问题;
1.对于提供可以自由裁剪pre-train model,怎么保证你输出的前面部分的check point 参数与模型结构 freeze在一起能在新的任务里,表现好?有没有实验数据支撑?
2.你知道depthwise-CNN吗?讲讲具体原理?那1*1的kernel的作用是什么呢?对网络model有什么影响?
3.你还知道或者学习过那些传统机器学习算法?XGBoost?HMM?SVM等等都清楚吗?
4. 你学过那些基本算法?数据结构的运用?
5. 你是哪里人?老家?籍贯?
6.问我大学经历,未来打算,为什么工作?听出来我想先工作,问我后面想不想读博?
交换问题,
1.面试官的工作内容。
2.对自己的评价及建议:短时间内展示自己最闪亮的部分(第二天进四面,等待通知) 。