【51CTO.com原创稿件】技术领域
互联网电子商务领域,尤其涉及到快速实现业务部门数据分析需求的处理方法以及系统。
背景技术
随着计算机通讯技术的发展,苏宁易购各业务系统产生的业务数据的规模也越来越大,对如此庞大的数据进行快速分析传统的框架和技术已显得力不从心,并且随着数据挖掘技术的发展,对其海量数据的分析往往都是随机维度的自由组合,对此类需求传统的做法都是一个固化离线统计分析,消耗大量的人力、物力,并且都不能实时分析。针对以上问题,我们设计出了一套可以快速响应苏宁各业务部门数据需求分析的工具,不仅支持多维度的自由组合、个性化的设置,而且还能快速统计出用户随机指定的相关维度、指标数据。高效实现了用户的个性化需求,达到创新!
创新的内容(技术创新和业务价值)
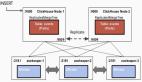
主要创新在于:首先我们将数据进行分类,如苏宁的业务数据可以归类为时序化和非时序化,汇总类和明细类数据等,然后采用不同的架构技术方案进行处理。如针对时序化的数据,我们基于Druid做了相关的设计和封装,可以将能预汇总的数据存储于此。时序化的明细数据我们基于ElasticSerach技术作了封装,可以将历史数据通过Spark直接初始化到ElasticSerach,增量数据可以开启ElasticSerach服务获取Kafka实时增量数据信息。针对一些特殊场景如精确去重计算,涉及多表关联,我们采用了基于PostGreSql进行了相关的组件封装,整套的技术架构方案,能覆盖用户在海量数据中快速自定义维度、指标进行数据分析的大部分场景。对于业务系统产生的海量数据,无论是实时还是离线的,都可以自由的进行维度、指标组合,个性化的设置,对用户数据分析需求进行快速统计。其特点为:对存储海量的业务数据无论是汇总和明细查询都能够高效的查询,个性化的维度、指标的自由组合,能够很好支持业务部门的大部分数据分析需求。
1、解决的问题
(1)业务部门数据分析需求问题
苏宁易购各业务系统(如订单,价格,购物车,促销等电商业务系统)每天产生海量的数据,各业务部门在业务数据产生后,都会对业务数据进行数据分析和相关的明细查询操作。然而这种数据分析往往带有随机和不确定性,每个部门不同的岗位想看的、想分析的往往会截然不同,这样就会产生了大量的报表需求,给开发部门带来了巨大的工作量。针对此需求背景,我们进行了架构的调整和设计,实现能够让客户自由选择不同维度和指标进行个性化需求分析,快速的统计出用户想要的数据。在明细数据查询的时候,根据用户选择的日期、维度和指标也能快速的响应。用这种支持用户个性化的定义分析工具,可以解决大部分的日常的数据分析需求,为公司节约了成本。
(2)海量数据高效汇总问题
无论是面对海量的离线数据还是实时的数据,对如此庞大的数据进行数据分析都是困难的,之前我们针对实时数据的汇总一般采用STORM进行汇总再存入到DB或者其他的缓存中供查询,但是这种定时调度存在延迟,不能进行实时的查询。在海量的离线数据做汇总的时候,之前往往我们借助于HADOOP的离线计算,根据先定义好的维度统计相关的指标再入库或缓存操作,这样预先需要定义大量的不同维度组合,离线计算时效性也很差。基于以上的实时和离线的汇总统计出现的瓶颈,我们后续进行了架构的调整,先在DRUID定义一张大宽表,将相关的维度和指标都定义在这个宽表中,数据在存储的时候会按照维度进行预汇总,在查询的时候可以快速相应,彻底解决了海量数据汇总效率低的问题。
(3)海量明细数据高效查询问题
对于业务中需要查询大量的明细数据问题,之前传统的做法都是分库分表存储在DB里,这样在查询数据集较大的情况下存在很大的延迟问题,在存储上和归档上也是极其不便,我们进行了相关的架构调整,存储海量的业务明细数据采用了ElasticSearch存储介质,ElasticSearch是基于Lucene搜索引擎的其查询效率很高,彻底解决了海量业务明细数据查询高延迟问题。
(4)精确去重(count distinct)和多表关联问题
苏宁的业务分析中涉及统计到很多需要去重的维度、指标,利用Druid以及ElasticSearch去重都会有丢失精度问题,利用传统的关系数据库则统计的效率较低。鉴于此类场景,我们就PostgreSql进行了封装,利用其自身Sharding 和分片技术实现了高效的查询,满足了精确去重、多表关联并且高效查询。
(5)为大促提供保障
苏宁每年的大促都会进行大力的促销活动,其交易量会是平时的几十倍,对海量数据的存储和分析对于传统的架构来说显然很吃力,本方案运用到诸葛大师的塔罗以及实时GMV项目中,很好的解决了该问题。自定义销售塔罗我们设计一张大宽表,将可以汇总的数据入Druid进行预汇总,只保留汇总后的数据,业务部门可以根据随机选取的维度和指标进行组合查询。将明细不需要汇总的数据我们放入到ElasticSerach中去,利用其高效的Lucene搜索引擎可以快速查询出业务需要的明细数据。对于需要精确去重以及多表关联的特殊场景数据,我们存储到PostGreSql中,用户可以根据选择需要去重的维度和指标进行查询,也能快速的相应。利用此发明我们已经多次立项,其中主要内容包含实时GMV、历史GMV、销售塔罗、会员塔罗、库存塔罗以及自定义塔罗等,在大促期间给领导、用户、业务人员能够快速的进行数据分析提供保障。
2、核心创新点
我们针对海量的数据下自定义维度和指标进行快速响应做了一套方案,对各种业务场景的覆盖,对现有的开源技术Druid、ElasticSearch和PostGreSql进行封装,制作成适合支持苏宁此类业务场景个性化的组件,用此整套架构方案我们可以快速实现业务部门数据分析,实现用户可以随机定义维度和指标进行快速分析,无须再进行大量的个性化报表开发,不仅用户体验得到提高,同时也释放了大量的开发资源。
3、技术方案
***步:数据的接入 ;
将时序化类型的汇总增量的实时流式数据和全量需要初始化的离线数据接入到Druid中,个性化的汇总数据分析都是基于DRUID实现的。海量的时序化的明细数据信息接入到ElasticSearch,离线数据我们通过Spark组件初始化到ElasticSerach,增量的流式数据我们通过ElasticSearch监控服务去从kafka拉取,所有的个性化的明细数据查询都是基于ElasticSearch实现的。非时序化需要进行精确去重以及多表关联的数据我们初始化到PostGreSql中,在PG 中我们支持汇总和明细各种场景的海量数据快速查询。
第二步:个性化的数据分析汇总查询;
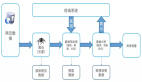
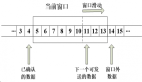
个性化的数据分析汇总主要是基于Druid操作的,首先设计一张大宽表,这个大宽表包含了业务域的所有的维度和指标,再将实时和离线数据接入到这个基于Druid的大宽表中,数据会根据这个大宽表的定义的维度进行预汇总,存储的并非明细数据,界面提供用户选择的维度和指标,可以任意的组合,支持个性化的配置,将选择好的维度和指标固化后进入到查询界面,再从Druid中开始查询已经配置好的维度和指标进行数据分析。
举例:
销售塔罗:苏宁的销售数据有实时数据和历史数据,在统计销售数据的时候会有很多维度进行统计、如统计各大区的付款金额和订单数量、各品牌、品类的付款金额和订单数量、各业务渠道的同期和本期的销售额等,这样就会有大量的报表需要开发人员去开发,而且销售的维度和指标有很多,涉及到数据挖掘那组合就更多了。之前的做法是实时数据我们基于STORM汇总后落入DB提供展示,但是这种设计不能满足用户个性化的操作,不能随意的选择维度和指标,往往都是先提需求再进行相关的开发,仍然有大量的开发工作量。后续我们基于Druid存储后,将所有的销售维度和指标都放在一张大宽表中,数据基于维度预汇总进行存储,页面支持个性化的配置,这样就能够快速的实现业务部门的数据分析需求。
第三步:个性化的数据分析明细查询;
个性化的数据分析明细查询主要是基于ElasticSearch操作的,在ElasticSearch中我们定义了索引和类型,将涉及到的维度和指标信息都定义在其中,接着我们将明细数据灌入其中,因ElasticSearch是基于Lucene框架的全文搜索引擎,其支持海量明细数据高效的查询。如像订单明细数据,每天约数十万数据量,两年数据存储在ElasticSearch中,在对两年订单明细数据进行随意过滤查询,其相应速度都是秒级,用户体验较好。
第四步:非时序需要精确查询和多表关联的查询
非时序化的需要精确查询以及多表关联的数据我们存储在PostGreSql中,在PostGreSql中我们设置了分片表、本地表,对不同场景设置了不同的索引如:B-tree, Hash, GiST, GIN等,利用其Sharding, point-in-time recovery(PITR)等非常棒的特性实现了高可用、负载均衡与复制功能,从而保障了数据可以快速存储到PostGreSql中并且能高效的查询出来。对于需要精确去重的业务场景,我们可以直接采用和关系型数据库一样的操作count(distinct)即可,对于多表关联,PostGreSql能很好支持大部分 SQL标准并且提供了许多其它特性。
总结
随着数据量的不断增长和业务对快速分析的要求,传统的框架和技术已无法应对新的挑战。新的挑战逼迫技术人员要找到能满足海量数据和快速分析需求的解决方案。本文所述的“海量数据条件下企业自定义数据分析需求的实现”是在新的条件下应对以上挑战的一种探索,解决了海量数据的汇总、查询问题,帮助业务部门快速进行数据的分析和挖掘,为各个业务部门的决策和行为提供数据支撑,特别是在大促期间能对精准营销等业务提供数据方面的保障,为公司的“数据经营”添砖加瓦。
附图

图1 业务系统技术架构图

图2 业务系统应用架构图

图3 业务系统应用集成图

图4 销售塔罗数据流向图

图5 用户可自由选择关心的指标及维度
作者:丁安国,苏宁易购IT总部大数据中心基础分析研发部经理,15年从业背景,苏宁架构师职称。对于基于大数据的数据分析系统的建设有丰富的经验,对于电商订单、购物车、价格等高并发系统的设计、开发和运维也有独到的见解,目前致力于苏宁基于大数据的各类分析平台的建设。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】