现在的网络安全领域由各种各样的门派,最火的莫属web领域的网络安全,还有物联网安全等等。缓冲区溢出安全漏洞有一种忽视的感觉,起始最开始的、最有威力的还是缓冲区溢出漏洞,很多零日漏洞也是基于缓冲区漏洞的,最具破坏力的也是缓冲区漏洞。这篇文章简单讲解一下缓冲区漏洞的原理知识,后期结合metasploit和靶机系统,推出实战方面的课程。
1. 内存攻防技术
很多学习网络安全的人员有这样的一种感觉,对于缓冲区溢出、栈溢出、堆溢出、shellcode等有一定的了解,模模糊糊的了解术语和概念,但是如果实践编写一些渗透代码时,总感觉无从下手,也许是没有迈过技术门槛。
内存攻击指的是利用软件的安全漏洞,构造恶意的输入导致软件在处理输入数据是出现非预期的错误,导致数据被写到特定的位置,改变了软件的控制流程,转而执行外部输入的指令,造成目标系统被远程控制或者拒绝服务。
内存攻击的3个重点:
- 软件存在安全漏洞
- 恶意的输入触发安全漏洞
- 改变软件的控制流程

2. 缓冲区溢出漏洞机制
缓冲区溢出漏洞是由于程序没有对缓冲区的边界条件进行检查,导致引发的异常行为,向缓冲区写入数据,内容超过了程序员设定的缓冲区边界,覆盖了相邻的内存区域,覆盖了其他变量还有可能影响程序的控制流程。
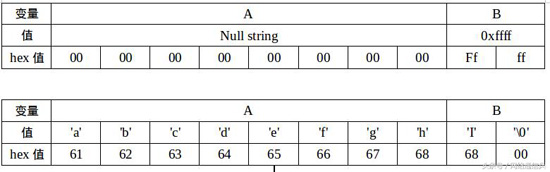
这里举个例子,如下图所示,内存中存在两个相邻的变量,A是char[]类型的,用于接收外部的数据,输入为8个字节,B是短整型的,B的初始值是65535(0xffff)。如果用户输入的是"abcdefghi",9个字节,那么B就被修改为0x0069,如下图所示
根据缓冲区位置的不同,可以分为:
- 栈溢出(Stack Overflow)
- 堆溢出(Heap Overflow)
3. 栈溢出漏洞原理
栈是由操作系统创建和维护的,支持程序内的函数调用功能。
函数调用时,程序会将返回地址压入栈中,执行换被调用函数的代码后,通过ret命令从栈中弹出返回地址,放入eip寄存器,继续程序的运行。
栈溢出的原理:程序向栈中写入数据时,当写入的数据长度超过栈分配的缓冲区空间时,就造成了栈溢出。
栈溢出最常见的利用方式有:
- 覆盖函数返回地址
- 覆盖异常处理结构
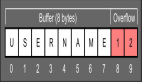
这里举个例子,说明覆盖函数返回地址的情况,一般发生在函数调用时,程序将主程序的下一条指令地址保存到栈中,子函数执行结束后,从栈中弹出主程序的指令地址,继续执行。这样程序的返回地址、函数的调用参数、局部变量均位于同一个栈中,就给栈溢出改写程序流程提供了机会。看下面一段代码
- #include<string.h>
- void foo(char *bar)
- {
- char c[8];
- strcpy(c,bar);
- }
- int main()
- {
- char array[]='abcdabcdabcd\x18\xff\x18\x00';
- foo(array);
- return 0;
- }
注意上述代码中的strcpy(c,bar)并没有进行边界检查,这段代码执行结束前后的堆栈空间的分配情况如下图所示。源字符串array的16个字符复制到C中,最后的4个字符覆盖了栈的返回地址,改为0x0018ef18,当函数foo返回之后,程序就会跳转到0x0018ef18这个地址执行相关指令。