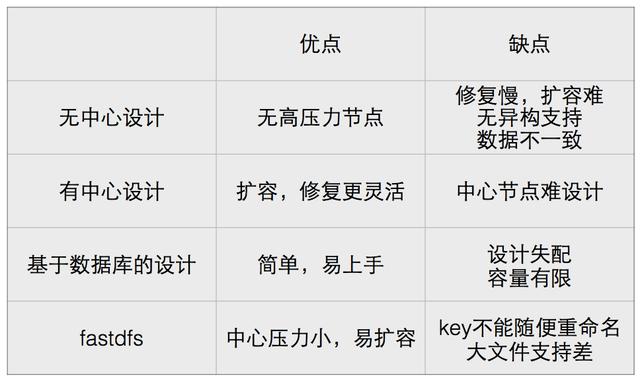
常规的存储设计方法主要有以下几类。
- 无中心的存储设计,如GlusterFS。
- 有中心的存储设计,如Hadoop。
- 基于数据库的存储设计,如GridFS和HBase。
- 绕过元数据的存储设计,如FastDFS。
下面我们逐一讲述。
无中心的存储设计:GlusterFS
目前,GlusterFS在互联网行业中用的较少,在大型计算机中用的较多。它在设计上具有以下几个特点。
- 兼容POSIX文件系统:单机上的应用程序无需修改就可以放到GlusterFS运行。
- 没有中心节点:不存在单点故障和性能瓶颈。
- 扩展能力:因为没有中心节点,所以GlusterFS的扩展能力无限,扩展多少台服务器都没有问题。
我们不讨论POSIX兼容的优劣,集中通过GlusterFS来讨论无中心节点设计中普遍遇到的一些难点。
1. 坏盘修复。无中心暗示着可通过key推算这个key的存储位置。但是,磁盘坏了(单盘故障)怎么办呢?直接的处理方式是去掉坏盘,换上新盘,将这些数据拷贝过来。这样的处理方式在小型系统上非常适用。但是一个4T的Sata盘,即使在千兆网下写入速度也只能达到100MB/s,修复时间会是11小时。考虑到一般的存储满指的是全部存储量的80%,那么修复时间将达到八到九个小时,所以不适合用于大型系统。大型系统磁盘多,每天会坏很多块磁盘。如果磁盘是同一批购买的,由于对称设计,读写的特性很相似,那么在坏盘修复的八九个小时里,其他磁盘同时坏的概率非常高。这时,整个系统的可靠性会比较低,只能达到6个9或7个9。如果想达到更高的可靠性,只能通过疯狂增加副本数这种会让成本大量提高的方法来解决。
GlusterFS本身不用这种修复设计,它的修复方式是在读磁盘时发现有坏块就触发修复,但这种设计的修复时间会更长。该如何回避掉这个问题呢?最简单的方法是将磁盘分成多个区,确保每个区尽量小。例如,将4T盘分成50个区,每个区只有80GB,并且记录各个区的一些元信息。在我们从key推算存储位置时,先计算出这个 key 所在区的编号,再通过刚才的元信息获得这个区对应的机器、磁盘和目录。这样带来的好处是,在磁盘坏了的时候,不用等换盘就可以开始修复,并且不一定要修复到同一块磁盘上,可以修复到有空间的多块磁盘上,从而得到一种并发的修复能力。如果将4T盘分成50个区(每个区80G),那么修复时间就可以从8到9个小时缩减到13分钟左右。
2. 扩容。如前所述,在无中心节点的设计中,从key可以推算它存储的位置,并且我们要求key是均匀Hash的。这时,如果集群规模从一百台扩容到二百台,会出现什么问题呢?Hash是均匀的,意味着新加的一百台机器的存储负载要和以前的一致,有一半的数据要进行迁移。但集群很大时,数据迁移过程中所花的时间通常会很长,这时会出现网络拥塞。同时数据迁移过程中的读写逻辑会变得非常复杂。解决方法是多加一些测试,改善代码质量,不要出BUG。还有一种方法是,保持容量固定,尽量不要扩容,但这与互联网的风格(从很小的模型做起,慢慢将它扩大化)不相符。
3. 不支持异构存储。提供云存储服务的公司必然会面临一个问题,有很多客户存储的文件非常小,而另外很多客户存储的文件非常大。小文件通常伴随着很高的IOPS需求,比较简单的做法是将Sata盘(100 IOPS)换成SAS盘(300 IOPS)或者SSD盘(10000 IOPS以上)来得到更高的IOPS。但是对于无中心存储,由于key是Hash的,所以根本不知道小文件会存在哪里,这时能提高IOPS的唯一办法是加强所有机器的能力。例如,每台机器中将10块Sata盘、2块SAS盘和1块SSD盘作为一个整体加入缓存系统,提升系统的IOPS,但整体的成本和复杂性都会增加很多。另外一种方式是拼命扩大集群规模,这样整体的IOPS能力自然会比较高。
类似的异构需求还包括某些客户数据只想存两份,而其他客户数据则想多存几份,这在无中心存储中都很难解决。
4. 数据不一致的问题。比如要覆盖一个key,基于hash意味着要删除一个文件,再重新上传一个文件,新上传的文件和之前的一个文件会在同一块磁盘的同一个目录下使用同样的文件名。如果覆盖时出现意外,只覆盖了三个副本中的两个或者一个,那么就很容易读到错误的数据,让用户感觉到覆盖没有发生,但原始数据已经丢失了。这是最难容忍的一个问题。解决方案是在写入文件时,先写一个临时文件,最后再重命名修改。但由于是在分布式架构中,且跨机器操作,会导致逻辑的复杂性增加很多。
简单总结一下,以GlusterFS为代表的无中心设计带来的一些问题如下图所示。

有中心的存储设计:Hadoop
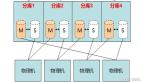
Hadoop的设计目标是存大文件、做offline分析、可伸缩性好。Hadoop的元数据存储节点(NameNode节点)属于主从式存储模式,尽量将数据加载到内存,能提高对数据的访问性能。另外,放弃高可用,可进一步提高元数据的响应性能(NameNode的变更不是同步更新到从机,而是通过定期合并的方式来更新)。
Hadoop具有以下几方面优点。
1. 为大文件服务。例如在块大小为64MB时,10PB文件只需要存储1.6亿条数据,如果每条200Byte,那么需要32GB左右的内存。而元信息的QPS也不用太高,如果每次QPS能提供一个文件块的读写,那么1000QPS就能达到512Gb/s的读写速度,满足绝大部分数据中心的需求。
2. 为offline业务服务,高可用服务可以部分牺牲。
3. 为可伸缩性服务,可以伸缩存储节点,元信息节点无需伸缩。
然而有如此设计优点的Hadoop为什么不适合在公有云领域提供服务呢?
1. 元信息容量太小。在公有云平台上,1.6亿是个非常小的数字,单个热门互联网应用的数据都不止这些。1.6亿条数据占用32GB内存,100亿条数据需要2000GB内存,这时Hadoop就完全扛不住了。
2. 元信息节点无法伸缩。元信息限制在单台服务器,1000QPS甚至是优化后的15000QPS的单机容量远不能达到公有云的需求。
3. 高可用不完美。就是前面所提到的NameNode问题,在业务量太大时,Hadoop支撑不住。
因此,做有中心的云存储时,通常的做法是完全抛弃掉原先的单中心节点设计,引入一些其他的设计。
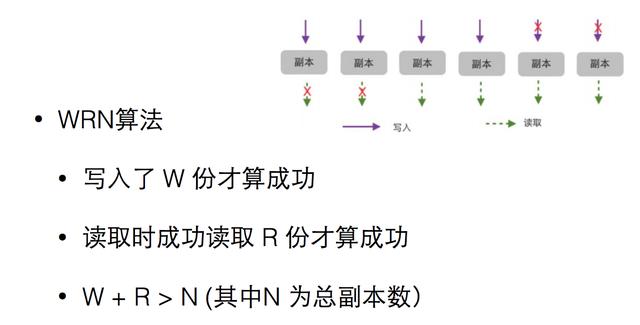
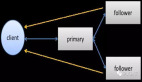
常见的是WRN算法,为数据准备多个样本,写入W份才成功,成功读取R份才算成功,W+R大于N(其中N为总副本数)。这样就解决了之前提到的高可用问题,任何一个副本宕机,整个系统的读写都完全不受影响。
在这个系统里,利用这种技术有以下几个问题需要注意:
W,R,N选多少合适
第一种选择2,2,3,一共三副本,写入两份成功,读取时成功读取两份算成功。但是其中一台机器下线的话,会出现数据读不出来的情况,导致数据不可用。
第二种选择4,4,6或者6,6,9,能够容忍单机故障。但机器越多,平均响应时间越长。
失败的写入会污染数据
比如4,4,6的场景,如果写入只成功了3份,那么这次写入是失败的。但如果写入是覆盖原来的元数据,就意味着现在有三份正确的数据,有三份错误的数据,无法判断哪份数据正确,哪份数据错误。回避的方法是写入数据带版本(不覆盖,只是追加),即往数据库里面插入新数据。有些云存储的使用方法是对一个文件进行反复的修改,比如用M3U8文件直播。随着直播进程的开始不停地更改文件,大概5秒钟一次,持续一个小时文件会被修改720次。这时候从数据库读取文件信息时,就不再是读1条记录,而是每台读取720条记录,很容易导致数据库出现性能瓶颈。
下面,我们简单总结一下以Hadoop为代表的有中心的存储设计存在的问题。

基于数据库的分布式存储设计:GridFS、HBase
GridFS
GridFS基于MongoDB,相当于一个文件存储系统,是一种分块存储形式,每块大小为255KB。数据存放在两个表里,一个表是chunks,加上元信息后单条记录在256KB以内;另一个表是files,存储文件元信息。
GridFS的优点如下所述。
1.可以一次性满足数据库和文件都需要持久化这两个需求。绝大部分应用的数据库数据需要持久化,用户上传的图片也要做持久化,GridFS用一套设施就能满足,可以降低整个运维成本和机器采购成本。
2.拥有MongoDB的全部优点:在线存储、高可用、可伸缩、跨机房备份;
3.支持Range GET,删除时可以释放空间(需要用MongoDB的定期维护来释放空间)。
GridFS的缺点如下所述。
1.oplog耗尽。oplog是MongoDB上一个固定大小的表,用于记录MongoDB上的每一步操作,MongoDB的ReplicaSet的同步依赖于oplog。一般情况下oplog在5GB~50GB附近,足够支撑24小时的数据库修改操作。但如果用于GridFS,几个大文件的写入就会导致oplog迅速耗尽,很容易引发secondary机器没有跟上,需要手工修复,大家都知道,MongoDB的修复非常费时费力。简单来说,就是防冲击能力差,跟数据库的设计思路有关,毕竟不是为文件存储设计的。除了手工修复的问题,冲击还会造成主从数据库差异拉大,对于读写分离,或者双写后再返回等使用场景带来不小的挑战。
2.滥用内存。MongoDB使用MMAP将磁盘文件映射到内存。对于GridFS来说,大部分场景都是文件只需读写一次,对这种场景没法做优化,内存浪费巨大,会挤出那些需要正常使用内存的数据(比如索引)。这也是设计阻抗失配带来的问题。
3.伸缩性问题。需要伸缩性就必须引入MongoDB Sharding,需要用files_id作Sharding,如果不修改程序,files_id递增,所有的写入都会压入最后一组节点,而不是均匀分散。在这种情况下,需要改写驱动,引入一个新的files_id生成方法。另外,MongoDB Sharding在高容量压力下的运维很痛苦。MongoDB Sharding需要分裂,分裂的时候响应很差,会导致整个服务陷入不可用的状态。
对GridFS的总结如下。

HBase
前面提到Hadoop因为NameNode容量问题,所以不适合用来做小文件存储,那么HBase是否合适呢?
HBase有以下优点。
1.伸缩性、高可用都在底层解决了。
2.容量很大,几乎没有上限。
但缺点才是最关键的,HBase有以下缺点。
1.微妙的可用性问题。首先是Hadoop NameNode的高可用问题。其次,HBase的数据放在Region上,Region会有分裂的问题,分裂和合并的过程中Region不可用,不管用户这时是想读数据还是写数据,都会失败。虽然可以用预分裂回避这个问题,但这就要求预先知道整体规模,并且key的分布是近均匀的。在多用户场景下,key均匀分布很难做到,除非舍弃掉key必须按顺序这个需求。
2.大文件支持。HBase对10MB以上的大文件支持不好。改良方案是将数据拼接成大文件,然后HBase只存储文件名、offset和size。这个改良方案比较实用,但在空间回收上需要补很多开发的工作。
应对方案是HBase存元数据,Hadoop存数据。但是,Hadoop是为offline设计的,对NameNode的高可用考虑不充分。HBase的Region分拆和合并会造成短暂的不可用,如果可以,最好做预拆,但预拆也有问题。如果对可用性要求低,那么这种方案可用。
绕过问题的存储设计:FastDFS
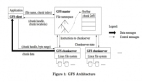
Hadoop的问题是NameNode压力过高,那么FastDFS的思路是给NameNode减压。减压方法是将NameNode的信息编码到key中。对于范例URL:group1/M00/00/00/rBAXr1AJGF_3rCZAAAAEc45MdM850_big.txt来说,NameNode只需要做一件事,将group1翻译成具体的机器名字,不用关心key的位置,只要关心组的信息所在的位置,而这个组的信息就放在key里面,就绕过了之前的问题。
FastDFS的优点如下。
1.结构简单,元数据节点压力低;
2.扩容简单,扩容后无需重新平衡。
FastDFS的缺点如下。
1.不能自定义key,这对多租户是致命的打击,自己使用也会降低灵活性。
2.修复速度:磁盘镜像分布,修复速度取决于磁盘写入速度,比如4TB的盘,100MB/s的写入速度,至少需要11个小时。
3.大文件冲击问题没有解决。首先,文件大小有限制(不能超过磁盘大小);其次,大文件没有分片,导致大文件的读写都由单块盘承担,所以对磁盘的网络冲击很大。
总结
几种存储设计可以总结如下。