本周一,云头条报道称“Github.com 已挂了 8 个小时:数据存储设备坏掉了!” 许多用户在Twitter上纷纷吐槽,抱怨网站宕机,包括中国、日本的好多惴惴不安的程序员,一些人抱怨自己无法登录进去,或者分支版本丢失了,等等。
乍一看,又是“宕机”惹的祸。可是,元芳,你怎么看?
疑点一:具体表现。
从美国西海岸时间周日下午4点开始,GitHub.com一直处于抽疯的状态。具体来说,该网站仍在提供页面服务,它只是间歇性地提供过期的文件,但忽略了提交上去的Gist、代码错误报告和帖子。有时候,它似乎在提供只读缓存或它本身的旧备份,不过一些推送的新代码无法发布到网站上。
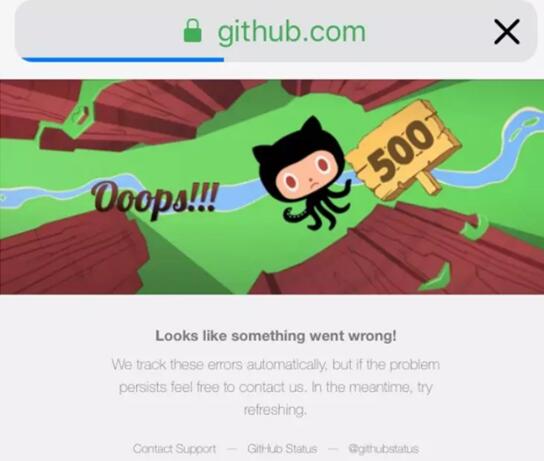
官网故障
疑点二:官方声明。
开发团队在下午5点后说:“我们在继续努力迁移数据存储系统,以便恢复访问GitHub.com的服务。”该团队随后在过去的几分钟补充道:“我们在继续修复GitHub.com的数据存储系统。在此过程中您可能会看到不一致的结果。”
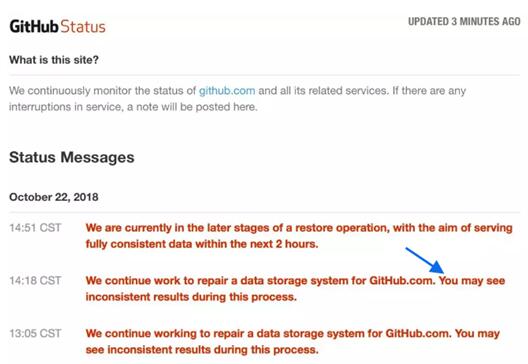
官网声明
一般来说,像上面案例中提到的“迁移数据存储系统,以便恢复访问GitHub.com的服务”,也是应对IT事故、恢复业务的常规流程,无可厚非。然而在故障8小时候,仍旧无法提供业务支持,只能提供“旧备份”数据或者“不一致”的数据,让我不禁怀疑GitHub网站的数据有丢失的嫌疑。
作为一个面向开源及私有软件项目的托管平台,Github拥有超过900万开发者用户。在GitHub,用户可以十分轻易地找到海量的开源代码。这意味着每时每刻都有大量重要数据在GitHub汇集。如果真的丢失了部分数据,对GitHub来说可能只是一小丢丢,可是对最终用户而言,则是100%的灾难。
虽说容灾备份领域早就突破了早期的“数据备份与恢复”范畴,而增加了“业务连续”方面的内容,但数据才是根本,没有数据,谈何业务?
在这一点上,我十分赞同容灾备份老牌厂商和力记易提出的“一个优秀的容灾备份方案,数据可用是底线”的说法。
2015年底,笔者在一次行业会议上结识了和力记易公司的张总。当时大会就数据安全的重要性进行热烈讨论,在交流时,有人提起前不久银监会通报了某银行的数据丢失问题,为什么明明做了“双机双柜”,怎么还是不能“幸免于难”?和力记易的张总寥寥数语解开了这个疑问,“数据库数据还在,但是发生了内部逻辑错误(比如ASM头文件错误),所以整个数据库就不可用了。”
我开玩笑的问张总“双机双柜方案都解决不了问题,你们和力记易的容灾备份方案呢?”张总斩钉截铁的说“我们可以!”
不论是何种数据备份,定时也好,实时也好,快照也好,镜像也好,技术上的差别就决定了数据备份与恢复的不同结果。“备份数据”能忠实于“源数据”是最基本的,但是如果这份数据恢复回来以后无法使用,那这个恢复就没有任何意义。和力记易容灾备份软件——备特佳的CDP持续数据保护技术,区别于市场其他备份软件的最核心的一点就是:不仅能够保证备份数据的完整性,更能保证恢复数据的可用性。这一点,和力记易称之为“容灾备份的底线”。
两年前的经历现在却历历在目,当时是因为震撼,今天被Github勾想了起来,却是衷心的希望GitHub的事故,乍一看是“宕机”,实际上也是“宕机”,千万不要丢失数据,浪费了忠实用户的心血和成绩。
所幸,发文时,Github在历经了24小时磨难后,终于恢复正常,数据没有丢失,真好。