云盘为云服务器提供高可用、高可靠、持久化的数据块级随机存储,其性能和数据可靠性尤为重要。UCloud根据以往的运营经验,在过去一年里重新设计了云盘的底层架构,在提升普通云盘性能的同时,完成了对NVME高性能存储的支持。下文从IO路径优化、元数据分片、支持NVME等技术维度着手,详细讲解了UCloud云硬盘的架构升级和性能提升策略。
IO路径优化
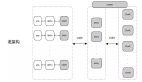
过去,IO读写需要经过三层架构,请求首先通过网络,访问proxy代理服务器(proxy主要负责IO的路由获取、缓存、读写转发以及IO写操作的三份复制),***到达后端存储节点。老的架构里,每一次读/写IO都需要经过2次网络转发操作。

为了降低延时,优化后的方案将proxy负责的功能拆分,定义由client负责IO的路由获取、缓存,以及将IO的读写发送到主chunk当中,由主chunk负责IO写的三份复制。架构升级之后,IO的读写只需经过两层架构,尤其对于读IO而言,一次网络请求可直达后端存储节点,其时延平均可降低0.2-1ms。
元数据分片
分布式存储会将数据进行分片,从而将每个分片按多副本打散存储于集群中。老架构中,UCloud支持的分片大小是1G。但是,在特殊场景下(如业务IO热点局限在较小范围内),1G分片会使普通SATA磁盘的性能非常差,并且在SSD云盘中,也不能均匀的将IO流量打撒到各个存储节点上。所以新架构中,UCloud将元数据分片调小,支持1M大小的数据分片。
分片过小时,需要同时分配或挂载的元数据量会非常大,容易超时并导致部分请求失败。这是由于元数据采用的是预分配和挂载,申请云盘时系统直接分配所有元数据并全部load到内存。
例如,同时申请100块300G的云盘,如果按1G分片,需要同时分配3W条元数据;如果按照1M分片,则需要同时分配3000W条元数据。

为了解决性能瓶颈,团队采用放弃路由由中心元数据节点分配的方式。该方案中,Client 端和集群后端采用同样的计算规则R(分片大小、pg个数、映射方法、冲突规则);云盘申请时,元数据节点利用计算规则四元组判断容量是否满足;云盘挂载时,从元数据节点获取计算规则四元组; IO时,按计算规则R(分片大小、pg个数、映射方法、冲突规则)计算出路路由元数据然后直接进行IO。通过这种改造方案,可以确保在1M数据分片的情况下,元数据的分配和挂载畅通无阻,并节省IO路径上的消耗。

对NVME高性能存储的支持
NVME充分利用 PCI-E 通道的低延时以及并行性极大的提升NAND固态硬盘的读写性能和降低时延,其性能百倍于HDD。目前常用的基于NAND的固态硬盘可支持超10W的写IOPS、40-60W的读IOPS以及1GB-3GB读写带宽,为支持NVME,软件上需要配套的优化设计。

首先,传统架构采用单线程传输,单个线程写 IOPS达6W,读IOPS达8W,难以支持后端NVME硬盘几十万的IOPS以及1-2GB的带宽。为了利用NVME磁盘的性能,需要将单线程传输改为多线程传输,系统定期上报线程CPU以及磁盘负载状态,当满足某线程持续繁忙、而有线程持续空闲情况时,可将选取部分磁盘分片的IO切换至空闲线程,目前5个线程可以完全发挥NVME的能力。

此外,在架构优化上,除了减少IO路径层级以及更小分片外,UCloud在IO路径上使用内存池、对象池,减少不停的new delete,同时尽量用数组索引,减少查询消耗,并避免字符串比较以及无谓的拷贝,最终充分地发挥NVME磁盘性能。
以上内容最早发表于UCloud 10月12日在上海主办的Tech Talk***期活动。Tech Talk是UCloud面向用户做深度技术交流的线下活动,后面也会继续举办,欢迎参加。