实际问题
在流计算场景中,数据会源源不断的流入Apache Flink系统,每条数据进入Apache Flink系统都会触发计算。那么在计算过程中如果网络、机器等原因导致Task运行失败了,Apache Flink会如何处理呢?在 《Apache Flink 漫谈系列 - State》一篇中我们介绍了 Apache Flink 会利用State记录计算的状态,在Failover时候Task会根据State进行恢复。但State的内容是如何记录的?Apache Flink 是如何保证 Exactly-Once 语义的呢?这就涉及到了Apache Flink的 容错(Fault Tolerance) 机制,本篇将会为大家进行相关内容的介绍。
什么是Fault Tolerance
容错(Fault Tolerance) 是指容忍故障,在故障发生时能够自动检测出来,并使系统能够自动恢复正常运行。当出现某些指定的网络故障、硬件故障、软件错误时,系统仍能执行规定的一组程序,或者说程序不会因系统中的故障而中止,并且执行结果也不包含系统故障所引起的差错。
传统数据库Fault Tolerance
我们知道MySQL的binlog是一个Append Only的日志文件,MySQL的主备复制是高可用的主要方式,binlog是主备复制的核心手段(当然MySQL高可用细节很复杂也有多种不同的优化点,如 纯异步复制优化为半同步和同步复制以保证异步复制binlog导致的master和slave的同步时候网络坏掉,导致主备不一致问题等)。MySQL主备复制,是MySQL容错机制的一部分,在容错机制之中也包括事物控制,在传统数据库中事物可以设置不同的事物级别,以保证不同的数据质量,级别由低到高 如下:
- Read uncommitted - 读未提交,就是一个事务可以读取另一个未提交事务的数据。那么这种事物控制成本***,但是会导致另一个事物读到脏数据,那么如何解决读到脏数据的问题呢?利用Read committed 级别...
- Read committed - 读提交,就是一个事务要等另一个事务提交后才能读取数据。这种级别可以解决读脏数据的问题,那么这种级别有什么问题呢?这个级别还有一个 不能重复读的问题,即:开启一个读事物T1,先读取字段F1值是V1,这时候另一个事物T2可以UPDATA这个字段值V2,导致T1再次读取字段值时候获得V2了,同一个事物中的两次读取不一致了。那么如何解决不可重复读的问题呢?利用 Repeatable read 级别...
- Repeatable read - 重复读,就是在开始读取数据(事务开启)时,不再允许修改操作。重复读模式要有事物顺序的等待,需要一定的成本达到高质量的数据信息,那么重复读还会有什么问题吗?是的,重复读级别还有一个问题就是 幻读,幻读产生的原因是INSERT,那么幻读怎么解决呢?利用Serializable级别...
- Serializable - 序列化 是***的事务隔离级别,在该级别下,事务串行化顺序执行,可以避免脏读、不可重复读与幻读。但是这种事务隔离级别效率低下,比较耗数据库性能,一般不使用。
主备复制,事物控制都是传统数据库容错的机制。
流计算Fault Tolerance的挑战
流计算Fault Tolerance的一个很大的挑战是低延迟,很多Apache Flink任务都是7 x 24小时不间断,端到端的秒级延迟,要想在遇上网络闪断,机器坏掉等非预期的问题时候快速恢复正常,并且不影响计算结果正确性是一件极其困难的事情。同时除了流计算的低延时要求,还有计算模式上面的挑战,在Apache Flink中支持Exactly-Once和At-Least-Once两种计算模式,如何做到在Failover时候不重复计算,进而精准的做到Exactly-Once也是流计算Fault Tolerance要重点解决的问题。
Apache Flink的Fault Tolerance 机制
Apache Flink的Fault Tolerance机制核心是持续创建分布式流数据及其状态的快照。这些快照在系统遇到故障时,作为一个回退点。Apache Flink中创建快照的机制叫做Checkpointing,Checkpointing的理论基础 Stephan 在 Lightweight Asynchronous Snapshots for Distributed Dataflows 进行了细节描述,该机制源于由K. MANI CHANDY和LESLIE LAMPORT 发表的 Determining-Global-States-of-a-Distributed-System Paper,该Paper描述了在分布式系统如何解决全局状态一致性问题。
在Apache Flink中以Checkpointing的机制进行容错,Checkpointing会产生类似binlog一样的、可以用来恢复任务状态的数据文件。Apache Flink中也有类似于数据库事物控制一样的数据计算语义控制,比如:At-Least-Once和Exactly-Once。
Checkpointing 的算法逻辑
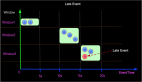
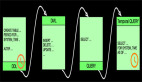
上面我们说Checkpointing是Apache Flink中Fault Tolerance的核心机制,我们以Checkpointing的方式创建包含timer,connector,window,user-defined state 等stateful Operator的快照。在Determining-Global-States-of-a-Distributed-System的全局状态一致性算法中重点描述了全局状态的对齐问题,在Lightweight Asynchronous Snapshots for Distributed Dataflows中核心描述了对齐的方式,在Apache Flink中采用以在流信息中插入barrier的方式完成DAG中异步快照。 如下图(from Lightweight Asynchronous Snapshots for Distributed Dataflows)描述了Asynchronous barrier snapshots for acyclic graphs,也是Apache Flink中采用的方式。
上图描述的是一个增量计算word count的Job逻辑,核心逻辑是如下几点:
- barrier 由source节点发出;
- barrier会将流上event切分到不同的checkpoint中;
- 汇聚到当前节点的多流的barrier要对齐;
- barrier对齐之后会进行Checkpointing,生成snapshot;
- 完成snapshot之后向下游发出barrier,继续直到Sink节点。
这样在整个流计算中以barrier方式进行Checkpointing,随着时间的推移,整个流的计算过程中按时间顺序不断的进行Checkpointing,如下图:
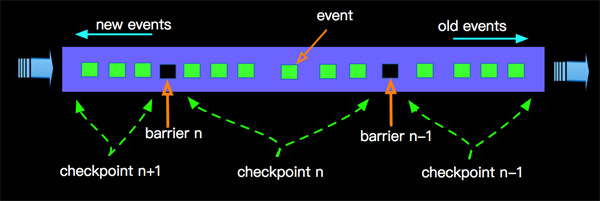
生成的snapshot会存储到StateBackend中,相关State的介绍可以查阅 《Apache Flink 漫谈系列 - State》。这样在进行Failover时候,从***一次成功的checkpoint进行恢复。
Checkpointing 的控制
上面我们了解到整个流上面我们会随这时间推移不断的做Checkpointing,不断的产生snapshot存储到Statebackend中,那么多久进行一次Checkpointing?对产生的snapshot如何持久化的呢?带着这些疑问,我们看看Apache Flink对于Checkpointing如何控制的?有哪些可配置的参数:(这些参数都在 CheckpointCoordinator 中进行定义)
- checkpointMode - 检查点模式,分为 AT_LEAST_ONCE 和 EXACTLY_ONCE 两种模式;
- checkpointInterval - 检查点时间间隔,单位是毫秒;
- checkpointTimeout - 检查点超时时间,单位毫秒。
在Apache Flink中还有一些其他配置,比如:是否将存储到外部存储的checkpoints数据删除,如果不删除,即使job被cancel掉,checkpoint信息也不会删除,当恢复job时候可以利用checkpoint进行状态恢复。我们有两种配置方式,如下:
- ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION - 当job被cancel时候,外部存储的checkpoints不会删除;
- ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION - 当job被cancel时候,外部存储的checkpoints会被删除。
Apache Flink 如何做到Exactly-once
通过上面内容我们了解了Apache Flink中Exactly-Once和At-Least-Once只是在进行checkpointing时候的配置模式,两种模式下进行checkpointing的原理是一致的,那么在实现上有什么本质区别呢?
1. 语义
At-Least-Once - 语义是流上所有数据至少被处理过一次(不要丢数据)
Exactly-Once - 语义是流上所有数据必须被处理且只能处理一次(不丢数据,且不能重复)
从语义上面Exactly-Once 比 At-Least-Once对数据处理的要求更严格,更精准,那么更高的要求就意味着更高的代价,这里的代价就是 延迟。
2. 实现
那在实现上面Apache Flink中At-Least-Once 和 Exactly-Once有什么区别呢?区别体现在多路输入的时候(比如 Join),当所有输入的barrier没有完全到来的时候,早到来的event在Exactly-Once模式下会进行缓存(不进行处理),而在At-Least-Once模式下即使所有输入的barrier没有完全到来,早到来的event也会进行处理。也就是说对于At-Least-Once模式下,对于下游节点而言,本来数据属于checkpoint N 的数据在checkpoint N-1 里面也可能处理过了。
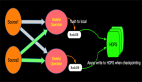
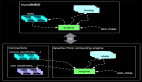
我以Exactly-Once为例说明Exactly-Once模式相对于At-Least-Once模式为啥会有更高的延时?如下图:
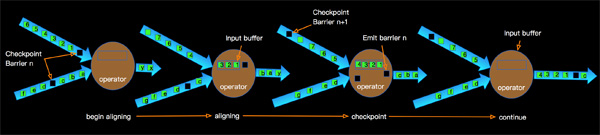
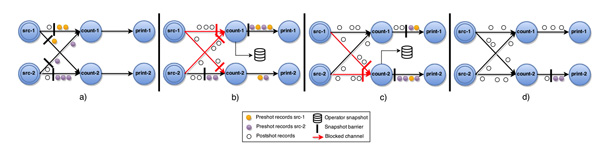
上图示意了某个节点进行Checkpointing的过程:
- 当Operator接收到某个上游发下来的第barrier时候开始进行barrier的对齐阶段;
- 在进行对齐期间早到的input的数据会被缓存到buffer中;
- 当Operator接收到上游所有barrier的时候,当前Operator会进行Checkpointing,生成snapshot并持久化;
- 当完Checkpointing时候将barrier广播给下游Operator。
多路输入的barrier没有对齐的时候,barrier先到的输入数据会缓存在buffer中,不进行处理,这样对于下游而言buffer的数据越多就有更大的延迟。这个延时带来的好处就是相邻Checkpointing所记录的数据(计算结果或event)没有重复。相对At-Least-Once模式数据不会被buffer,减少延时的利好是以容忍数据重复计算为代价的。
在Apache Flink的代码实现上用CheckpointBarrierHandler类处理barrier,其核心接口是:
- public interface CheckpointBarrierHandler {
- ...
- //返回operator消费的下一个BufferOrEvent。这个调用会导致阻塞直到获取到下一个BufferOrEvent
- BufferOrEvent getNextNonBlocked() throws Exception;
- ...}
其中BufferOrEvent,可能是正常的data event,也可能是特殊的event,比如barrier event。对应At-Least-Once和Exactly-Once有两种不同的实现,具体如下:
- Exactly-Once模式 - BarrierBuffer
BarrierBuffer用于提供Exactly-Once一致性保证,其行为是:它将以barrier阻塞输入直到所有的输入都接收到基于某个检查点的barrier,也就是上面所说的对齐。为了避免背压输入流,BarrierBuffer将从被阻塞的channel中持续地接收buffer并在内部存储它们,直到阻塞被解除。
BarrierBuffer 实现了CheckpointBarrierHandler的getNextNonBlocked, 该方法用于获取待处理的下一条记录。该方法是阻塞调用,直到获取到下一个记录。其中这里的记录包括两种,一种是来自于上游未被标记为blocked的输入,比如上图中的 event(a),;另一种是,从已blocked输入中缓冲区队列中被释放的记录,比如上图中的event(1,2,3,4)。
- At-Least-Once模式 - BarrierTracker
BarrierTracker会对各个输入接收到的检查点的barrier进行跟踪。一旦它观察到某个检查点的所有barrier都已经到达,它将会通知监听器检查点已完成,以触发相应地回调处理。不像BarrierBuffer的处理逻辑,BarrierTracker不阻塞已经发送了barrier的输入,也就说明不采用对齐机制,因此本检查点的数据会及时被处理,并且因此下一个检查点的数据可能会在该检查点还没有完成时就已经到来。这样在恢复时只能提供At-Least-Once的语义保证。
BarrierTracker也实现了CheckpointBarrierHandler的getNextNonBlocked, 该方法用于获取待处理的下一条记录。与BarrierBuffer相比它实现很简单,只是阻塞的获取要处理的event。
如上两个CheckpointBarrierHandler实现的核心区别是BarrierBuffer会维护多路输入是否要blocked,缓存被blocked的输入的record。所谓有得必有失,有失必有得,舍得舍得在这里也略有体现哈 :)。
完整Job的Checkpointing过程
在 《Apache Flink 漫谈系列 - State》中我们有过对Apache Flink存储到State中的内容做过介绍,比如在connector会利用OperatorState记录读取位置的offset,那么一个完整的Apache Flink任务的执行图是一个DAG,上面我们描述了DAG中一个节点的过程,那么整体来看Checkpointing的过程是怎样的呢?在产生checkpoint并分布式持久到HDFS的过程是怎样的呢?
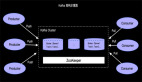
1. 整体Checkpointing流程

上图我们看到一个完整的Apache Flink Job进行Checkpointing的过程,JM触发Soruce发射barriers,当某个Operator接收到上游发下来的barrier,开始进行barrier的处理,整体根据DAG自上而下的逐个节点进行Checkpointing,并持久化到Statebackend,一直到DAG的sink节点。
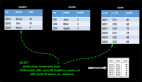
2. Incremental Checkpointing
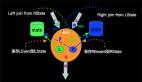
对于一个流计算的任务,数据会源源不断的流入,比如要进行双流join(Apache Flink 漫谈系列 - Join 篇会详细介绍),由于两边的流event的到来有先后顺序问题,我们必须将left和right的数据都会在state中进行存储,Left event流入会在Right的State中进行join数据,Right event流入会在Left的State中进行join数据,如下图左右两边的数据都会持久化到State中:
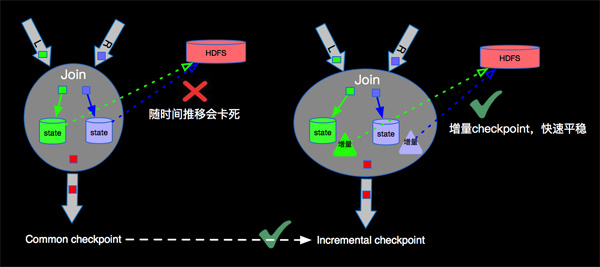
由于流上数据源源不断,随着时间的增加,每次checkpoint产生的snapshot的文件(RocksDB的sst文件)会变的非常庞大,增加网络IO,拉长checkpoint时间,最终导致无法完成checkpoint,进而导致Apache Flink失去Failover的能力。为了解决checkpoint不断变大的问题,Apache Flink内部实现了Incremental Checkpointing,这种增量进行checkpoint的机制,会大大减少checkpoint时间,并且如果业务数据稳定的情况下每次checkpoint的时间是相对稳定的,根据不同的业务需求设定checkpoint的interval,稳定快速的进行Checkpointing,保障Apache Flink任务在遇到故障时候可以顺利的进行Failover。Incremental Checkpointing的优化对于Apache Flink成百上千的任务节点带来的利好不言而喻。
端到端exactly-once
根据上面的介绍我们知道Apache Flink内部支持Exactly-Once语义,要想达到端到端(Soruce到Sink)的Exactly-Once,需要Apache Flink外部Soruce和Sink的支持,具体如下:
- 外部Source的容错要求:Apache Flink 要做到 End-to-End 的 Exactly-Once 需要外部Source的支持,比如上面我们说过 Apache Flink的Checkpointing机制会在Source节点记录读取的Position,那就需要外部Source提供读取数据的Position和支持根据Position进行数据读取。
- 外部Sink的容错要求:Apache Flink 要做到 End-to-End 的 Exactly-Once相对比较困难,以Kafka作为Sink为例,当Sink Operator节点宕机时候,根据Apache Flink 内部Exactly-Once模式的容错保证, 系统会回滚到上次成功的Checkpoint继续写入,但是上次成功checkpoint之后当前checkpoint未完成之前已经把一部分新数据写入到kafka了. Apache Flink自上次成功的checkpoint继续写入kafka,就造成了kafka再次接收到一份同样的来自Sink Operator的数据,进而破坏了End-to-End 的 Exactly-Once 语义(重复写入就变成了At-Least-Once了),如果要解决这一问题,Apache Flink 利用Two Phase Commit(两阶段提交)的方式来进行处理。本质上是Sink Operator 需要感知整体Checkpoint的完成,并在整体Checkpoint完成时候将计算结果写入Kafka。
小结
本篇和大家介绍了Apache Flink的容错(Fault Tolerance)机制,本篇内容结合《Apache Flink 漫谈系列 - State》 一起查阅相信大家会对Apache Flink的State和Fault Tolerance会有更好的理解,也会对后面介绍window,retraction都会有很好的帮助。
# 关于点赞和评论
本系列文章难免有很多缺陷和不足,真诚希望读者对有收获的篇章给予点赞鼓励,对有不足的篇章给予反馈和建议,先行感谢大家!
作者:孙金城,花名 金竹,目前就职于阿里巴巴,自2015年以来一直投入于基于Apache Flink的阿里巴巴计算平台Blink的设计研发工作。
【本文为51CTO专栏作者“金竹”原创稿件,转载请联系原作者】