背景
本次SQL优化是针对javaweb中的表格查询做的。
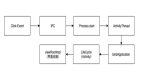
部分网络架构图

业务简单说明
N个机台将业务数据发送至服务器,服务器程序将数据入库至MySQL数据库。服务器中的javaweb程序将数据展示到网页上供用户查看。
原数据库设计
- windows单机主从分离
- 已分表分库,按年分库,按天分表
- 每张表大概20w左右的数据
原查询效率
3天数据查询70-80s
目标
3-5s
业务缺陷
无法使用sql分页,只能用java做分页。
问题排查
前台慢 or 后台慢
- 如果你配置了druid,可在druid页面中直接查看sql执行时间和uri请求时间
- 在后台代码中用System.currentTimeMillis计算时间差。
结论 : 后台慢,且查询sql慢
sql有什么问题
- sql拼接过长,达到了3000行,有的甚至到8000行,大多都是union all的操作,且有不必要的嵌套查询和查询了不必要的字段
- 利用explain查看执行计划,where条件中除时间外只有一个字段用到了索引
备注 : 因优化完了,之前的sql实在找不到了,这里只能YY了。
查询优化
去除不必要的字段
效果没那么明显
去除不必要的嵌套查询
效果没那么明显
分解sql
- 将union all的操作分解,例如(一个union all的sql也很长)
- select aa from bb_2018_10_01 left join ... on .. left join .. on .. where ..
- union all
- select aa from bb_2018_10_02 left join ... on .. left join .. on .. where ..
- union all
- select aa from bb_2018_10_03 left join ... on .. left join .. on .. where ..
- union all
- select aa from bb_2018_10_04 left join ... on .. left join .. on .. where ..
将如上sql分解成若干个sql去执行,最终汇总数据,***快了20s左右。
- select aa from bb_2018_10_01 left join ... on .. left join .. on .. where ..
将分解的sql异步执行
利用java异步编程的操作,将分解的sql异步执行并最终汇总数据。这里用到了CountDownLatch和ExecutorService,示例代码如下:
- // 获取时间段所有天数
- List<String> days = MyDateUtils.getDays(requestParams.getStartTime(), requestParams.getEndTime());
- // 天数长度
- int length = days.size();
- // 初始化合并集合,并指定大小,防止数组越界
- List<你想要的数据类型> list = Lists.newArrayListWithCapacity(length);
- // 初始化线程池
- ExecutorService pool = Executors.newFixedThreadPool(length);
- // 初始化计数器
- CountDownLatch latch = new CountDownLatch(length);
- // 查询每天的时间并合并
- for (String day : days) {
- Map<String, Object> param = Maps.newHashMap();
- // param 组装查询条件
- pool.submit(new Runnable() {
- @Override
- public void run() {
- try {
- // mybatis查询sql
- // 将结果汇总
- list.addAll(查询结果);
- } catch (Exception e) {
- logger.error("getTime异常", e);
- } finally {
- latch.countDown();
- }
- }
- });
- }
- try {
- // 等待所有查询结束
- latch.await();
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- // list为汇总集合
- // 如果有必要,可以组装下你想要的业务数据,计算什么的,如果没有就没了
结果又快了20-30s
优化MySQL配置
以下是我的配置示例。加了skip-name-resolve,快了4-5s。其他配置自行断定
- [client]
- port=3306
- [mysql]
- no-beep
- default-character-set=utf8
- [mysqld]
- server-id=2
- relay-log-index=slave-relay-bin.index
- relay-log=slave-relay-bin
- slave-skip-errors=all #跳过所有错误
- skip-name-resolve
- port=3306
- datadir="D:/mysql-slave/data"
- character-set-server=utf8
- default-storage-engine=INNODB
- sql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION"
- log-output=FILE
- general-log=0
- general_log_file="WINDOWS-8E8V2OD.log"
- slow-query-log=1
- slow_query_log_file="WINDOWS-8E8V2OD-slow.log"
- long_query_time=10
- # Binary Logging.
- # log-bin
- # Error Logging.
- log-error="WINDOWS-8E8V2OD.err"
- # 整个数据库***连接(用户)数
- max_connections=1000
- # 每个客户端连接***的错误允许数量
- max_connect_errors=100
- # 表描述符缓存大小,可减少文件打开/关闭次数
- table_open_cache=2000
- # 服务所能处理的请求包的***大小以及服务所能处理的***的请求大小(当与大的BLOB字段一起工作时相当必要)
- # 每个连接独立的大小.大小动态增加
- max_allowed_packet=64M
- # 在排序发生时由每个线程分配
- sort_buffer_size=8M
- # 当全联合发生时,在每个线程中分配
- join_buffer_size=8M
- # cache中保留多少线程用于重用
- thread_cache_size=128
- # 此允许应用程序给予线程系统一个提示在同一时间给予渴望被运行的线程的数量.
- thread_concurrency=64
- # 查询缓存
- query_cache_size=128M
- # 只有小于此设定值的结果才会被缓冲
- # 此设置用来保护查询缓冲,防止一个极大的结果集将其他所有的查询结果都覆盖
- query_cache_limit=2M
- # InnoDB使用一个缓冲池来保存索引和原始数据
- # 这里你设置越大,你在存取表里面数据时所需要的磁盘I/O越少.
- # 在一个独立使用的数据库服务器上,你可以设置这个变量到服务器物理内存大小的80%
- # 不要设置过大,否则,由于物理内存的竞争可能导致操作系统的换页颠簸.
- innodb_buffer_pool_size=1G
- # 用来同步IO操作的IO线程的数量
- # 此值在Unix下被硬编码为4,但是在Windows磁盘I/O可能在一个大数值下表现的更好.
- innodb_read_io_threads=16
- innodb_write_io_threads=16
- # 在InnoDb核心内的允许线程数量.
- # ***值依赖于应用程序,硬件以及操作系统的调度方式.
- # 过高的值可能导致线程的互斥颠簸.
- innodb_thread_concurrency=9
- # 0代表日志只大约每秒写入日志文件并且日志文件刷新到磁盘.
- # 1 ,InnoDB会在每次提交后刷新(fsync)事务日志到磁盘上
- # 2代表日志写入日志文件在每次提交后,但是日志文件只有大约每秒才会刷新到磁盘上
- innodb_flush_log_at_trx_commit=2
- # 用来缓冲日志数据的缓冲区的大小.
- innodb_log_buffer_size=16M
- # 在日志组中每个日志文件的大小.
- innodb_log_file_size=48M
- # 在日志组中的文件总数.
- innodb_log_files_in_group=3
- # 在被回滚前,一个InnoDB的事务应该等待一个锁被批准多久.
- # InnoDB在其拥有的锁表中自动检测事务死锁并且回滚事务.
- # 如果你使用 LOCK TABLES 指令, 或者在同样事务中使用除了InnoDB以外的其他事务安全的存储引擎
- # 那么一个死锁可能发生而InnoDB无法注意到.
- # 这种情况下这个timeout值对于解决这种问题就非常有帮助.
- innodb_lock_wait_timeout=30
- # 开启定时
- event_scheduler=ON
被批准多久. # InnoDB在其拥有的锁表中自动检测事务死锁并且回滚事务. # 如果你使用 LOCK TABLES 指令, 或者在同样事务中使用除了InnoDB以外的其他事务安全的存储引擎 # 那么一个死锁可能发生而InnoDB无法注意到. # 这种情况下这个timeout值对于解决这种问题就非常有帮助. innodb_lock_wait_timeout=30# 开启定时event_scheduler=ON
根据业务,再加上筛选条件
快4-5s
将where条件中除时间条件外的字段建立联合索引
效果没那么明显
将where条件中索引条件使用inner join的方式去关联
针对这条,我自身觉得很诧异。原sql,b为索引
- select aa from bb_2018_10_02 left join ... on .. left join .. on .. where b = 'xxx'
应该之前有union all,union all是一个一个的执行,***汇总的结果。修改为
- select aa from bb_2018_10_02 left join ... on .. left join .. on .. inner join
- (
- select 'xxx1' as b2
- union all
- select 'xxx2' as b2
- union all
- select 'xxx3' as b2
- union all
- select 'xxx3' as b2
- ) t on b = t.b2
结果快了3-4s
性能瓶颈
根据以上操作,3天查询效率已经达到了8s左右,再也快不了了。查看mysql的cpu使用率和内存使用率都不高,到底为什么查这么慢了,3天最多才60w数据,关联的也都是一些字典表,不至于如此。继续根据网上提供的资料,一系列骚操作,基本没用,没辙。
环境对比
因分析过sql优化已经ok了,试想是不是磁盘读写问题。将优化过的程序,分别部署于不同的现场环境。一个有ssd,一个没有ssd。发现查询效率悬殊。用软件检测过发现ssd读写速度在700-800M/s,普通机械硬盘读写在70-80M/s。
优化结果及结论
- 优化结果:达到预期。
- 优化结论:sql优化不仅仅是对sql本身的优化,还取决于本身硬件条件,其他应用的影响,外加自身代码的优化。
小结
优化的过程是自身的一个历练和考验,珍惜这种机会,不做只写业务代码的程序员。希望以上可以有助于你的思考,不足之处望指正。