单证是国际贸易中非常重要的一环,由于单证数量多、格式复杂、大量以图像形式存在等问题,给工作效率和风险控制带来极大的影响。在这种情况下,如何利用技术提高处理效能、防控风险就显得迫在眉睫。接下来,我们一起看看阿里工程师是如何解决这一问题。
业务背景
国际贸易的流程非常复杂,特别是B类贸易。为了防控各种风险,每个环节都有很多单证的交叉验证,以及基于单证构建的风控策略。比如:企业信息、银行卡等的交叉验证;信用证、提单、保单、箱单、发票、报关单等的风险审核。这些单证多而复杂,比如信用证业务,需要审核各种条款,并且做到单证一致、单单一致,往往需要非常专业的领域人员负责。整个审核周期耗时长,而且存在各种操作风险。因此,智能单证应运而生,通过使用机器学习和人工智能等技术,提高处理效率,降低成本和风险,开辟国际贸易的新模式。智能单证的价值在于:
- 提供订单决策报告,条款、信用和贸易风险报告,制单审单解决方案,服务更多国际贸易的中小企业。
- 利用人工智能技术,降低成本和风险,提高效率,提升客户体验,助力电商相关核心业务的优化升级。

技术方案
直接面临的是三个问题:
- 处理对象:大量格式复杂的单证,其中五成以上是扫描或者拍照的图片,质量层次不齐。
- 知识沉淀:各种术语、规则、名单、策略都是线下或者人工经验,没有沉淀,不成体系。
- 借力创新:项目时间紧,业务线多,需要平衡时间和扩展性,通过借力和创新落地产品。
因此,整体技术方案主要抽象成四大部分:图像处理服务、自然语言处理、领域知识图谱、统一技术架构。
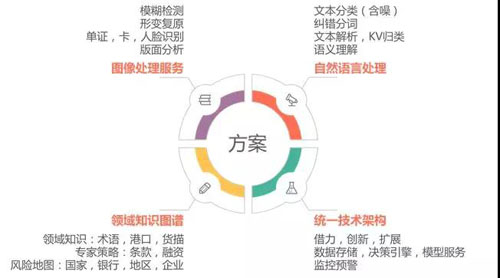
图像处理服务
图像质量比较好时,集团内已有的图像、人脸等识别技术可以达到高的Accuracy。但是,实际业务中的图像往往要复杂很多,直接调用已有的技术,整体Recall差不多只有五成不到。而且,通常的识别技术没有理解能力,比如:对于形变的图像,即使OCR识别出了字符,也无法正确恢复语义;图像的哪部分是实际需要的,也无法分析和判断。因此,图像处理服务,除了借力集团内的识别技术,更大的挑战是结合实际业务,落地好预处理(模糊检测、形变复原等)以及后处理(版面分析等)工作。
自然语言处理
由于单证的类型很多,并且五成以上都是图像,集团内外最好的OCR产品,都存在至少一成的词识别错误,因此,需要抗噪能力强的文本分类模型,先将单证进行自动分拣归类。另外,即使字符的识别错误较少,由于没有针对领域进行优化和分词,无法直接阅读和无人化使用。因此,将识别结果进行领域相关的纠错分词,也是势在必行。然后,通过解析引擎进行内容解析和Key-Value关系重建,结合基于文本构建的领域知识图谱和风控策略,完成语义理解和智能审核。
领域知识图谱
本文构建的知识图谱主要沉淀三部分内容:领域知识,包括国际贸易中的术语、缩写、港口信息等;专家策略,包括条款策略、冲突策略、融资策略、审核意见等;风险地图,包括风险国家、银行、地区、企业等。领域知识图谱是智能单证的根基所在,所有的前序处理都是为了与其结合,真正落地实现智能审核和风险防控。
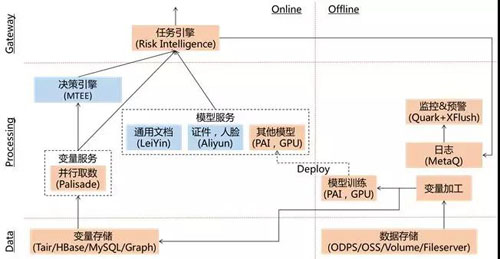
统一技术架构
技术架构上肯定不能重复造轮子,而且必须考虑项目时间,以及业务和技术的可扩展性。因此,根据团队已有的沉淀,抽象出统一的技术架构。首先,所有的服务接口收拢到统一的任务引擎。然后,充分借力集团已有的成熟技术和平台,比如:雷音(OCR技术),阿里云(证件、人脸识别技术),MTEE(实时决策引擎),PAI(模型训练、部署平台)等等。最后,针对实际业务中面临的问题,在算法和模型上深耕并且落地创新。
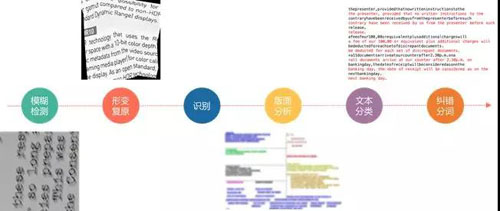
算法创新
本节阐述落地和创新的一些算法及模型,主要集中在图像处理和自然语言处理方面,包括模糊检测、形变复原以及纠错分词。
模糊检测
模糊检测,或者称为图像质量评估(Image Quality Assessment),需要轻量、快速地达到目标:智能处理 if 图像质量好 else 提示重传/人工处理。很多传统方法可以实现特定模糊类型的检测,比如Laplacian算子法,通过计算二阶微分,然后求方差,根据阈值可以确定图像是否模糊。

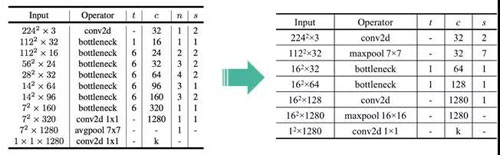
传统方法在特征提取及特征表现上存在局限性。本文改进MobileNetV2的网络结构,实现一种新的模糊检测算法。模糊检测需要特别关注图像细节的差异,因此,先通过随机切片及HSV颜色空间筛选的方法生成样本集合,然后基于OCR识别率指标划分正负样本。

原始MobileNetV2网络包含十七层Bottleneck,模型层数较深,并且每层还进行扩展,在实际训练中,不易收敛且模型较大。因此,通过对原始网络进行裁剪和改进,新的结构仅包含两层卷积、两层池化、两层Bottleneck以及一层全连接,网络更浅更窄,模型参数更少。目前,该模糊检测算法的准确率约93.4%,模型原始大小约2M,而使用原始MobileNetV2训练的模型大小约26M。
形变复原
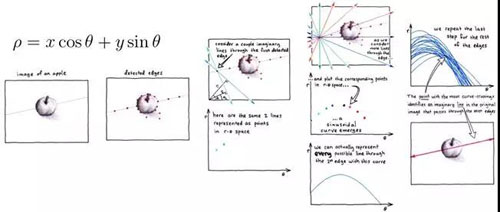
图像形变的类型有很多,比如旋转,折痕,卷曲等。这些问题除了直接影响OCR的识别效果,更严重的是影响语义重建。要做到实用的无人化审核,图像的形变复原工作至关重要。很多传统方法可以解决特定的简单的形变问题,比如对于简单的旋转形变,可以通过Hough Transform先检测直线,然后通过旋转角度进行复原。
近年来,基于深度学习的方法,比如FCN,STN,Unet等,也被尝试用来处理形变问题。本文结合深度学习语义分割领域的相关知识,针对已有方法的不足设计优化方案,提出一种新的形变复原算法。
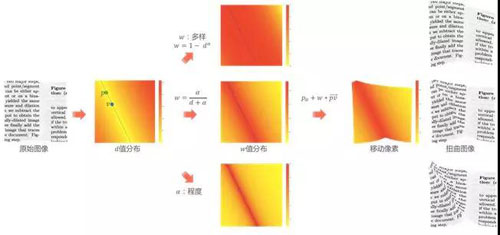
首先,利用数据合成的方法构造样本。通过![]() 的不同形式模拟多种形变类型,比如折痕、卷曲等;通过
的不同形式模拟多种形变类型,比如折痕、卷曲等;通过![]() 的大小变化模拟不同的形变程度。然后,通过插值和图像修复的方法,解决模拟图像的缺失像素问题。
的大小变化模拟不同的形变程度。然后,通过插值和图像修复的方法,解决模拟图像的缺失像素问题。
已有的基于Stacked Unet的前沿方法,容易出现裂痕、文本行扭曲、字符形变严重等问题。本文基于Dilated Convolution优化网络结构,并且通过调整损失函数、平滑预测值等方法,提出一种新的形变复原算法,提升模型的效果。
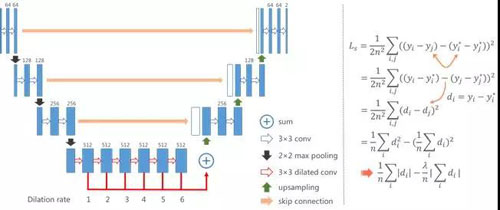
本文采用MS-SSIM作为算法复原效果的评价指标,其全称为Multi-Scale Structural Similarity,指的是多尺度下的结构相似性的综合评估。新算法的MS-SSIM达到0.693,而基于前沿论文的MS-SSIM为0.490,提升效果很明显。更详细的介绍见:
OCR如何读取皱巴巴的文件?深度学习在文档图像形变矫正的应用详解。

纠错分词
前文提到,集团内外最好的OCR产品,都存在至少一成的词识别错误。另外,即使字符的识别错误较少,由于没有针对领域进行优化和分词,无法直接阅读和无人化使用。因此,将识别结果进行领域相关的纠错分词,也是势在必行。
通常传统的实现方案中,纠错是基于分好的词级别进行的,而分词是基于没错的文本进行的。直接将纠错和分词结合的HMM模型,由于文本比较长,预测阶段的搜索空间很大,很耗时。因此,本文从新的视角看这个问题:将分词看成是纠错的一个特例,空格也作为有效字符,缺了空格也是一种错误;将纠错看成是一个翻译问题,是将一个错误的字符序列,翻译成一个正确的字符序列。这样,将纠错分词抽象成Sequence to Sequence的问题。
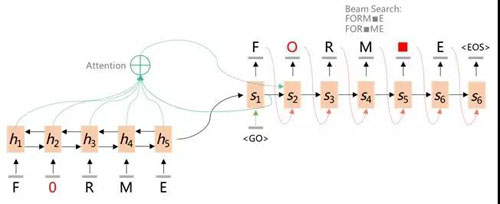
通过数据合成(根据概率转移矩阵,对字符进行增、删、改等编辑操作),以及迁移优化,训练得到满足目标要求的模型。目前,图片质量较好时,OCR识别结果与Ground Truth的差错率(编辑距离)为15.91%(若忽略空格:2.91%);经过本文的纠错分词模型,差错率降到2.24%,词准确率提升到93.56%。

应用实例
智能单证切入的业务环节,新模式的提效至少都在50%以上,成本和风险都大大降低,部分环节实现零风险和无人化。本节介绍智能单证在两个实际业务环节的应用。
信用证审核
客户拍照或者扫描上传信用证,经过一系列的图像处理和自然语言处理,智能审核每条条款,标记风险信息,返回审核和决策报告。

单证核对
客户拍照或者扫描上传单证(比如:保单、提单、报关单等),智能解析和核对每条栏位,标记信息(一致:紫色;可疑:黄色;缺失:红色),返回核对和建议报告。

总结展望
本文总结智能单证的业务背景及技术方案,阐述落地和创新的一些算法及模型,介绍实际业务中的一些应用。智能单证,作为一种国际贸易的新模式,除了使用机器学习和人工智能技术,提供风险和决策报告,以及整体的解决方案;同时也在推进其他前沿技术(比如:区块链技术)的落地,更好地服务更多国际贸易的中小企业。
关于我们
我们是新零售增值业务技术团队,旨在用科技的力量,为中小微贸企业提供在贸易和供应链场景下的金融,风控,信用,保险等增值服务。通过链接中小企业和金融机构,运用新技术、大数据和平台优势,让无数中小微企业能够从银行获取到只有大型企业才能得到的服务,为无数中小企业提供高效,安全,低成本的金融服务,让企业的信用转化为财富。
参考文献
[1] L. Kang, P. Ye, Y. Li, D. Doermann. ADeep Learning Approach to Document Image Quality Assessment[C]// IEEEInternational Conference on Image Processing, 2014:2570-2574.
[2] P. Ye, D. Doermann. Document ImageQuality Assessment: A Brief Survey[C]// International Conference on Document Analysisand Recognition. IEEE Computer Society, 2013:723-727.
[3] Howard A G, Zhu M, Chen B, et al. MobileNets:Efficient Convolutional Neural Networks for Mobile Vision Applications[J]. arXivpreprint arXiv:1704.04861, 2017.
[4] Sandler M, Howard A, Zhu M, et al.Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification,Detection and Segmentation[J]. arXiv preprint arXiv:1801.04381, 2018.
[5] N. Nayef, M. Muzzamil Luqman, S. Prum, etal. SmartDoc-QA: A Dataset for Quality Assessment of Smartphone CapturedDocument Images - Single and Multiple Distortions[C]// International Workshopon Camera-Based Document Analysis and Recognition, 2015:1231-1235.
[6] Ma K, Shu Z, Bai X, et al. DocUNet:Document Image Unwarping via A Stacked U-Net[C]// Proceedings of the IEEEConference on Computer Vision and Pattern Recognition, 2018:4700-4709.
[7] Ronneberger O, Fischer P, Brox T. U-net:Convolutional Networks for Biomedical Image Segmentation[C]// InternationalConference on Medical Image Computing and Computer Assisted Intervention, 2015:234-241.
[8] Yu F, Koltun V. Multi-Scale ContextAggregation by Dilated Convolutions[J]. arXiv preprint arXiv:1511.07122, 2015.
[9] Wang Z, Simoncelli E, Bovik A. Multi-ScaleStructural Similarity for Image Quality Assessment[C]// Asilomar Conference on SignalsSystems and Computers, 2003:1398-1402.
[10]Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. Sequence to Sequence Learningwith Neural Networks[J]. arXiv preprint arXiv:1409.3215, 2014.
[11]https://stackoverflow.com/questions/4709725/explain-hough-transformation
【本文为51CTO专栏作者“阿里巴巴官方技术”原创稿件,转载请联系原作者】