本文是这个系列的第二篇,着重讨论存储引擎的需求、思考和设计。上一篇是《SDS之HCI系列:分布式块存储的研发如何设计元数据服务?》。
先来看一下我们会对数据存储引擎模块有什么样的需求。

首先,肯定是还是可靠。因为我们客户的应用场景都大部分是核心的应用,数据可靠是要绝对保证的,没有任何妥协的空间。
其次是性能,目前在万兆网络和SSD,包括 NVMe SSD 都已经非常普及。随着硬件的速度越来越快,性能的瓶颈会从硬件转移到软件。尤其对于存储引擎来说,性能至关重要。
除了追求绝对的性能以外,我们还希望能够做到高效。我们希望每一个 CPU 指令都不被浪费。我们追求用最少的 CPU 指令完成一次 IO 操作。这背后的原因是,存储硬件设备越来越快,目前最快的存储已经可以做到单次访问只需要 10 纳秒。而如果程序中加一次锁,做一次上下文切换,可能几百个纳秒就过去了。如果不做到高效的话,目前的 CPU 可能完全无法发挥出 SSD 的性能。除了高效的使用 CPU 以外,我们也要高效的使用内存资源,网络带宽资源。同时,由于目前相同容量的 SSD 的价格还高于 HDD 的价格,所以我们也尽可能的节省磁盘空间的占用,通过利用压缩,去重等技术,提高 SSD 的空间使用效率。
***,也是非常重要的一点,存储引擎需要易于 Debug,而且要易于升级。对于软件工程师来说,50% 以上的工作时间都是在做 Debug,而对存储软件工程师来说,这个比例可能更高。我们希望做一个非常易于 Debug 的软件产品,如果发现问题,可以快速的定位并修复。升级也是一样,现在软件的迭代速度越来越快,我们希望软件可以方便的易于升级,这样我们可以让用户更快的使用上新版本的软件,享受到新版本的功能,以及性能的优化。
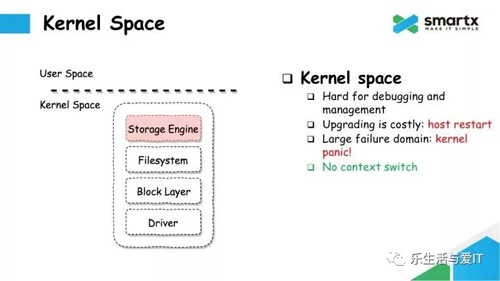
接下来,我们来看一下具体的实现。很多传统的存储厂商在实现存储引擎的时候,往往会选择把整个 IO 路径的实现放在 Kernel Space 里面。例如在上图中,上层是一个核心的存储引擎,下层是文件系统,块设备,以及驱动。由于网络栈也是实现在内核中的,把存储引擎放在内核里面就可以***化性能,减少上下文切换(Context Switch)。
但这种实现有很多非常严重的问题,首先就是难于 Debug。如果大家做过内核开发,就会知道在内核中 Debug 是一件非常麻烦的事情。而且开发语言也只能用 C,不能用其他语言。
同时,在内核里面开发,升级会非常困难。一次升级,不管是 Bugfix,还是增加新功能,都可能需要重启整个服务器,这对于存储系统来说代价是非常巨大的。还有一个很重要的因素就是故障域非常大。Kernel 里面的模块如果出问题,可能导致整个 Kernel 被污染,可能是死锁,可能是 Kernel Panic。通常也是需要重启服务器才能修复。
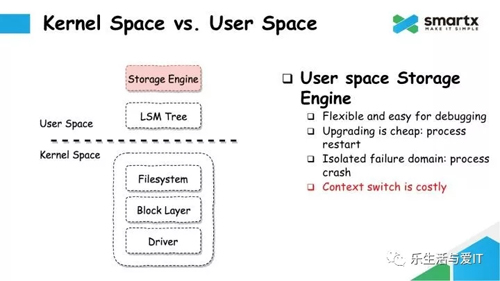
既然有这么多问题,那我们在设计的时候肯定不会选择用 Kernel Space 的方式。我们选择在 Userspace,也就是用户态实现我们的存储引擎。
在 User Space 实现,很多项目会选择把存储引擎构建在 LSM Tree 的数据结构上。LSM Tree 运行在文件系统之上。User Space 和 Kernel 比起来更灵活,可以用各种语言;升级也很方便,只需要重启一下进程就可以,不需要重启服务器;User Space 的故障只会影响到服务进程本身,并不会影响到 Kernel 的运行。但这种方式的问题就是性能不够好,由于 IO 还是需要经过 Kernel,所以会产生上下文切换,这个切换就会引入性能的开销。
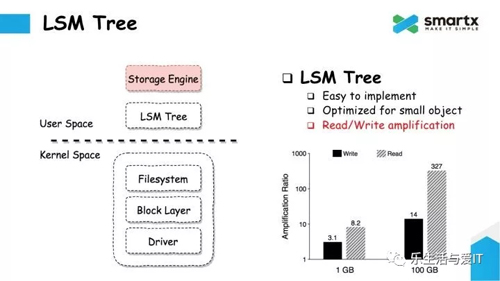
接下来,我们来说一下 LSM Tree。LSM Tree 的数据结构以及实现我们在这里就做不详细介绍了。总的来说,LSM Tree 是很多存储引擎的核心。
LSM Tree 的好处就是实现起来是相对简单的,有很多开源的实现可以参考,而且它对小块数据写入优化做的非常好,会将小块数据合并,并批量写入。
然而 LSM Tree 并不是银弹,它***的问题由于他的数据结构而导致的『读放大』和『写放大』。这个问题会有多严重呢。我们可以来看一下这个图(编者按:参见上图),这是一个对『读写放大』的测试结果。从图中可以看到,如果写入 1GB 的数据,最终会产生 3 倍的数据写入量,也就是 3 倍的『写放大』。如果写入 100G 的话,则会被放大到 14 倍,也就是说如果写 100G 的数据,实际上在磁盘上会产生 1.4TB 的写流量。而『读放大』会更加严重,在这个场景下会放大到 300 多倍。这就违背了我们最开始提到了我们希望提高硬件效率的诉求。
LSM Tree 虽然有各种各样的好处,但是由于存在严重的『读写放大』问题,所以我们并不会采用LSM Tree 来做数据存储引擎。我们可以借鉴 LSM Tree 中优秀的思想,结合我们自己的需求,实现一套存储引擎。这个包含了数据分配,空间管理,IO 等逻辑。
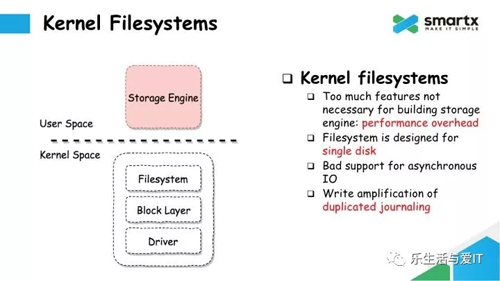
接下来,我们看到这个这个图中还有一个文件系统。这个文件系统是实现在内核中的,在块设备之上。大家比较常见的文件系统包括 ext4,xfs,btrfs 等,很多存储引擎也是实现在文件系统之上的。然而我们需要思考一下我们是否真的需要一个文件系统。
首先,文件系统所提供的功能远远多于存储引擎的需求。例如文件系统提供的 ACL 功能,Attribute 功能,多级目录树功能,这些功能对于一个专用的存储引擎来说,都是不需要的。这些额外的功能经常会产生一些 Performance Overhead,尤其是一些全局锁,对性能影响非常严重。
其次,大部分文件系统在设计的时候,都是面向单一磁盘的设计方式,而不是面向多块磁盘的。而一般存储服务器上都会部署 10 块,甚至更多的磁盘,而且有可能是 SSD,有可能是 HDD,也可能是混合部署。
第三,很多文件系统在异步 IO 上支持的并不好,尽管支持异步 IO 的接口,但实际使用过程中,偶尔还是会有阻塞的情况发生,这也是文件系统里一个非常不好的地方。
***一个问题,文件系统为了保证数据和元数据的一致性,也会有 Journaling 的设计。但这些 Journaling 也会引入写放大的问题。如果服务器上挂载了多个文件系统,单个文件系统的 Journaling 也无法做到跨文件系统的原子性。
最终我们在设计存储引擎的时候,我们选择了抛弃文件系统,抛弃 LSM Tree,自己在做一个理想中的存储引擎,去掉不必要的功能,尽可能的避免写放大。把我们想要的功能直接实现在块设备上。
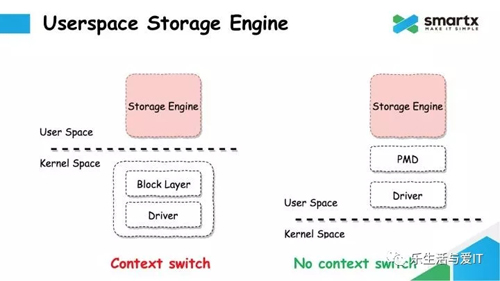
我们并没有想要自己实现 Block Layer 这一层,这是因为 Linux Kernel 中,Block Layer 是非常薄的一层,里面实现的算法也非常简单,这些算法也都有参数可调,也都有办法关闭掉,所以不会有太多额外的性能开销。
左边这个图就是 ZBS 目前的实现方式。但这种方式***的问题还是性能,Block Layer 和 Driver 都运行在 Kernel Space,User Space 的存储引擎的 IO 都会经过 Kernel Space,会产生 Context Switch。未来我们会转向右边这个图的方式,通过 SSD 厂家提供的 User Space 驱动,结合 PMD(Poll Mode Driver)引擎,以提供更好的性能。
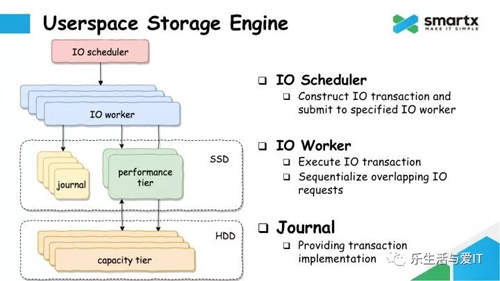
接下来,我们看一下 ZBS 的 User Space 存储引擎具体的实现。
IO Scheduler 负责接收上层发下来的 IO 请求,构建成一个 Transaction,并提交给指定的 IO Worker。IO Worker 负责执行这个 Transaction。Journal 模块负责将 Transaction 持久化到磁盘上,并负责 Journal 的回收。Performance Tier 和 Capacity Tire 分别负责管理磁盘上的空闲空间,以及把数据持久化到对应的磁盘上。